Ajudar a melhorar esta página
Para contribuir com este guia de usuário, escolha o link Editar esta página no GitHub, disponível no painel direito de cada página.
Conceitos sobre Kubernetes
O Amazon Elastic Kubernetes Service (Amazon EKS) é um serviço gerenciado AWS baseado no projeto Kubernetes
Esta página divide os conceitos do Kubernetes em três seções: Por que usar o Kubernetes?, Clusters e Workloads. A primeira seção descreve o valor da execução de um serviço do Kubernetes, em particular como um serviço gerenciado como o Amazon EKS. A seção Workloads aborda como as aplicações do Kubernetes são criadas, armazenadas, executadas e gerenciadas. A seção Clusters apresenta os diferentes componentes que compõem os clusters do Kubernetes e quais são suas responsabilidades pela criação e manutenção dos clusters do Kubernetes.
À medida que você avançar nesse conteúdo, os links levarão a descrições adicionais dos conceitos do Kubernetes tanto na documentação do Amazon EKS e quanto na do Kubernetes, caso deseje se aprofundar em algum dos tópicos abordados aqui. Para obter detalhes sobre como o Amazon EKS implementa o ambiente de gerenciamento e os recursos computacionais do Kubernetes, consulte Arquitetura do Amazon EKS.
Por que usar o Kubernetes?
O Kubernetes foi projetado para aprimorar a disponibilidade e a escalabilidade ao executar aplicações em contêineres essenciais e com qualidade de produção. Em vez de apenas executar o Kubernetes em uma única máquina (embora isso seja possível), o Kubernetes alcança esses objetivos permitindo que você execute aplicações em conjuntos de computadores que podem se expandir ou se contrair para atender à demanda. O Kubernetes inclui recursos que facilitam para você:
-
Implantar aplicações em várias máquinas (usando contêineres implantados em pods)
-
Monitorar a integridade de contêineres e reiniciar contêineres que falharam
-
Aumentar ou reduzir a escala dos contêineres verticalmente dependendo da carga
-
Atualizar os contêineres com versões novas
-
Alocar recursos entre contêineres
-
Equilibrar o tráfego entre máquinas
A automatização desses tipos de tarefas complexas com o Kubernetes permite que os desenvolvedores de aplicações se concentrem em criar e melhorar suas workloads de aplicações, em vez de se preocupar com a infraestrutura. O desenvolvedor normalmente cria arquivos de configuração formatados como arquivos YAML que descrevem o estado desejado da aplicação. Isso pode incluir quais contêineres executar, limites de recursos, número de réplicas de pod, alocação de CPU/memória, regras de afinidade e muito mais.
Atributos do Kubernetes
Para alcançar seus objetivos, o Kubernetes oferece os seguintes atributos:
-
Containerized : é uma ferramenta de orquestração de contêineres do Kubernetes. Para usar o Kubernetes, suas aplicações deverão ser conteinerizadas primeiro. Dependendo do tipo de aplicação, isso pode ocorrer na forma de um conjunto de microsserviços, como trabalhos em lotes ou em outras formas. Então, suas aplicações podem usar um fluxo de trabalho do Kubernetes que engloba um enorme ecossistema de ferramentas, em que os contêineres podem ser armazenados como imagens em um registro de contêineres
, implantados em um cluster do Kubernetes e executados em um nó disponível. É possível criar e testar contêineres individuais em seu computador local com o Docker ou outro runtime de contêiner antes de implantá-los no cluster do Kubernetes. -
Escalonável: se a demanda por suas aplicações exceder a capacidade das instâncias em execução dessas aplicações, o Kubernetes poderá ter a escala aumentada verticalmente. Conforme necessário, o Kubernetes pode dizer se as aplicações precisam de mais CPU ou memória e responder expandindo automaticamente a capacidade disponível ou usando mais da capacidade existente. O aumento da escala pode ser feito no nível do pod, se houver computação suficiente disponível para executar mais instâncias da aplicação (escalação automática horizontal do pod
), ou no nível do nó, se mais nós precisarem ser criados para lidar com o aumento da capacidade (Cluster Autoscaler ou Karpenter ). Como a capacidade não é mais necessária, esses serviços podem excluir pods desnecessários e desligar nós desnecessários. -
Disponível: se uma aplicação ou nó se tornar não íntegro ou indisponível, o Kubernetes poderá mover as workloads em execução para outro nó disponível. Você pode forçar o problema simplesmente excluindo uma instância em execução de uma workload ou um nó que esteja executando suas workloads. O ponto principal aqui é que as workloads poderão ser levadas para outros locais se não for mais possível executá-las onde estão.
-
Declarativo: o Kubernetes usa a reconciliação ativa para verificar constantemente se o estado que você declara para o cluster corresponde ao estado real. Ao aplicar objetos do Kubernetes
a um cluster, normalmente por meio de arquivos de configuração formatados em YAML, você pode, por exemplo, solicitar a inicialização das workloads que deseja executar no cluster. Posteriormente, é possível alterar as configurações para fazer algo como usar uma versão mais recente de um contêiner ou alocar mais memória. O Kubernetes fará o que for necessário para estabelecer o estado desejado. Isso pode incluir ativar ou desativar nós, interromper e reiniciar workloads ou obter contêineres atualizados. -
Compossível- como uma aplicação geralmente consiste em vários componentes, você quer poder gerenciar um conjunto desses componentes (geralmente representados por vários contêineres) juntos. Embora o Docker Compose ofereça uma maneira de fazer isso diretamente com o Docker, o comando Kompose
do Kubernetes pode ajudar você a fazer isso com o Kubernetes. Consulte Traduzir um arquivo Docker Compose para recursos do Kubernetes para obter um exemplo de como fazer isso. -
Extensível: ao contrário do software proprietário, o projeto de código aberto do Kubernetes foi projetado para ser aberto para você, que pode estender o Kubernetes da maneira que desejar para atender às suas necessidades. As APIs e os arquivos de configuração são abertos para modificações diretas. Incentivamos os terceiros a criar seus próprios controladores
para estender a infraestrutura e os recursos do usuário final do Kubernetes. Os webhooks permitem que você configure regras de cluster para aplicar políticas e se adaptar às mudanças nas condições. Para obter mais ideias sobre como estender os clusters do Kubernetes, consulte Como estender Kubernetes . -
Portátil: muitas organizações padronizaram suas operações no Kubernetes porque ele permite gerenciar todas as necessidades de aplicações da mesma forma. Os desenvolvedores podem usar os mesmos pipelines para criar e armazenar aplicações conteinerizadas. Essas aplicações podem então ser implantadas em clusters do Kubernetes executados on-premises, em nuvens, em terminais de ponto de venda em restaurantes ou em dispositivos de IoT distribuídos por instalações remotas de uma empresa. Sua natureza de código aberto permite que as pessoas desenvolvam essas distribuições especiais do Kubernetes, junto com as ferramentas necessárias para gerenciá-las.
Gerenciar o Kubernetes
O código-fonte do Kubernetes está disponível gratuitamente, portanto, com seu próprio equipamento, você pode instalar e gerenciar o Kubernetes por conta própria. No entanto, o autogerenciamento do Kubernetes requer profundo conhecimento operacional e exige tempo e esforços para ser mantido. Por esses motivos, a maioria das pessoas que implantam workloads de produção escolhe um provedor de nuvem (como o Amazon EKS) ou um provedor on-premises (como o Amazon EKS Anywhere) com sua própria distribuição do Kubernetes testada e o suporte de especialistas no Kubernetes. Isso permite a você descarregar grande parte do trabalho pesado indiferenciado necessário para manter seus clusters, incluindo:
-
Hardware: se você não tiver hardware disponível para executar o Kubernetes de acordo com seus requisitos, um provedor de nuvem, como o AWS Amazon EKS, pode reduzir os custos iniciais. Com o Amazon EKS, isso significa que é possível consumir os melhores recursos de nuvem oferecidos pela AWS, incluindo instâncias de computação (Amazon Elastic Compute Cloud), seu próprio ambiente privado (Amazon VPC), gerenciamento central de identidades e permissões (IAM) e armazenamento (Amazon EBS). A AWS gerencia os computadores, as redes, os data centers e todos os outros componentes físicos necessários para executar o Kubernetes. Da mesma forma, você não precisa planejar seu data center para lidar com a capacidade máxima nos dias de maior demanda. Para o Amazon EKS Anywhere ou outros clusters do Kubernetes on-premises, você é responsável por gerenciar a infraestrutura usada em suas implantações do Kubernetes, mas ainda pode contar com a AWS para manter o Kubernetes atualizado.
-
Administrar o ambiente de gerenciamento: o Amazon EKS gerencia a segurança e a disponibilidade do ambiente de gerenciamento do Kubernetes hospedado pela AWS, que é responsável por agendar contêineres, gerenciar a disponibilidade de aplicações e outras tarefas importantes para que você possa se concentrar em suas workloads de aplicações. Se seu cluster falhar, é esperado que a AWS tenha os meios necessários para restaurá-lo para um estado de execução. Para o Amazon EKS Anywhere, você mesmo gerenciaria o ambiente de gerenciamento.
-
Atualizações testadas: ao atualizar seus clusters, você pode contar com o Amazon EKS ou o Amazon EKS Anywhere para fornecer versões testadas de suas distribuições do Kubernetes.
-
Complementos: há centenas de projetos criados para estender e trabalhar com o Kubernetes que podem ser adicionados à infraestrutura do cluster ou ser usados para ajudar na execução das workloads. Em vez de desenvolver e gerenciar esses complementos por conta própria, a AWS fornece Complementos do Amazon EKS que você pode usar com seus clusters. O Amazon EKS Anywhere fornece pacotes selecionados
que incluem compilações de muitos projetos populares de código aberto. Assim, você não precisa criar o software sozinho ou gerenciar patches críticos de segurança, correções de bugs ou atualizações. Da mesma forma, se os padrões atenderem às suas necessidades, é normal que esses complementos exijam muito pouca configuração. Consulte Cluster estendido para obter detalhes sobre como estender seu cluster com complementos.
Kubernetes em ação
O diagrama a seguir mostra as principais atividades que você realizará como administrador ou desenvolvedor de aplicações do Kubernetes para criar e usar um cluster do Kubernetes. No processo, ele ilustra como os componentes do Kubernetes interagem entre si usando a Nuvem AWS como exemplo do provedor de nuvem subjacente.
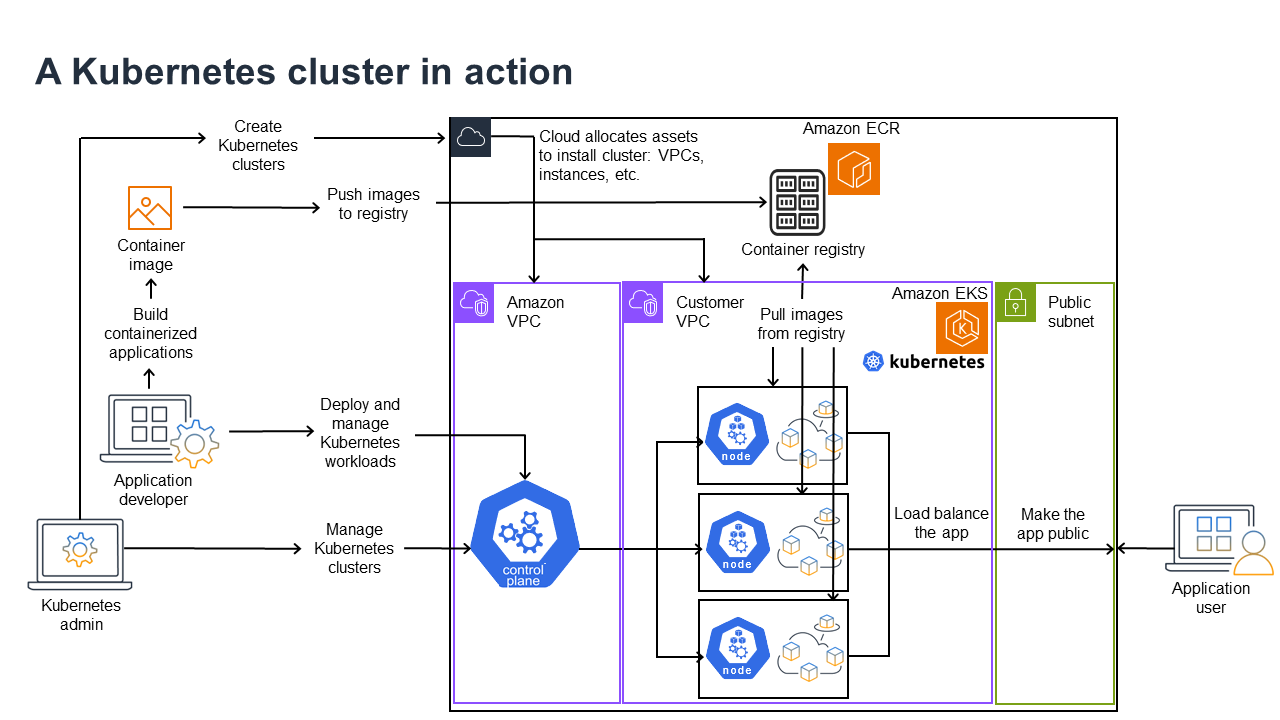
Um administrador do Kubernetes cria o cluster do Kubernetes usando uma ferramenta específica para o tipo de provedor no qual o cluster será criado. Este exemplo usa a Nuvem AWS como provedor, que oferece o serviço gerenciado do Kubernetes denominado Amazon EKS. O serviço gerenciado realiza automaticamente a alocação dos recursos necessários para criar o cluster, o que inclui a criação de duas novas nuvens privadas virtuais (Amazon VPCs) para o cluster, a configuração de redes e o mapeamento de permissões do Kubernetes diretamente nas novas VPCs para o gerenciamento de ativos na nuvem. O serviço gerenciado também garante que os serviços do ambiente de gerenciamento tenham locais para serem executados, e aloca zero ou mais instâncias do Amazon EC2 como nós do Kubernetes para a execução de workloads. A AWS gerencia uma Amazon VPC para o ambiente de gerenciamento, enquanto a outra Amazon VPC contém os nós do cliente que executam as workloads.
Muitas das futuras tarefas do administrador do Kubernetes serão realizadas usando ferramentas do Kubernetes como o kubectl. Essa ferramenta faz solicitações de serviços diretamente no ambiente de gerenciamento do cluster. As maneiras como as consultas e alterações são feitas no cluster são então muito semelhantes às formas como você as faria em qualquer cluster do Kubernetes.
Um desenvolvedor de aplicações que deseja implantar workloads nesse cluster pode realizar várias tarefas. O desenvolvedor precisa criar a aplicação em uma ou mais imagens de contêiner e, em seguida, enviar essas imagens para um registro de contêineres acessível pelo cluster do Kubernetes. A AWS oferece o Amazon Elastic Container Registry (Amazon ECR) para esse fim.
Para executar a aplicação, o desenvolvedor pode criar arquivos de configuração no formato YAML que informam ao cluster como executar a aplicação, incluindo quais contêineres extrair do registro e como agrupá-los em pods. O ambiente de gerenciamento (agendador) agenda os contêineres em um ou mais nós e o runtime do contêiner em cada nó realmente extrai e executa os contêineres necessários. O desenvolvedor também pode configurar um application load balancer para equilibrar o tráfego para os contêineres disponíveis em execução em cada nó e expor a aplicação para que ela se torne disponível em uma rede pública para o mundo externo. Com tudo isso feito, alguém que queira usar a aplicação poderá se conectar ao endpoint da aplicação para acessá-la.
As seções a seguir analisam os detalhes de cada um desses recursos, da perspectiva de clusters e workloads do Kubernetes.
Clusters
Se seu trabalho é iniciar e gerenciar clusters do Kubernetes, tenha em mente como os clusters do Kubernetes são criados, aprimorados, gerenciados e excluídos. Você também deverá saber quais são os componentes que compõem um cluster e o que precisa ser feito para mantê-los.
As ferramentas para gerenciar clusters lidam com a sobreposição entre os serviços do Kubernetes e o provedor de hardware subjacente. Por esse motivo, a automação dessas tarefas tende a ser feita pelo provedor do Kubernetes (como o Amazon EKS ou Amazon EKS Anywhere) usando as ferramentas específicas do provedor. Por exemplo, para iniciar um cluster do Amazon EKS, é possível usar eksctl create cluster, enquanto que para o Amazon EKS Anywhere é possível usar eksctl anywhere create cluster. Observe que, embora esses comandos criem um cluster do Kubernetes, eles são específicos do provedor e não fazem parte do projeto do Kubernetes em si.
Ferramentas de criação e gerenciamento de clusters
O projeto do Kubernetes oferece ferramentas para criar um cluster do Kubernetes manualmente. Portanto, se você deseja instalar o Kubernetes em uma única máquina, ou executar o ambiente de gerenciamento em uma máquina e adicionar nós manualmente, pode usar ferramentas da CLI como kind
Na Nuvem AWS, é possível criar clusters do Amazon EKS usando ferramentas de CLI, como eksctl
-
Plano de controle gerenciado- o site AWS garante que o cluster do Amazon EKS esteja disponível e seja dimensionável, pois gerencia o ambiente de gerenciamento para você e o disponibiliza em AWS Availability Zones.
-
Gerenciamento de nós: em vez de adicionar nós manualmente, você pode fazer com que o Amazon EKS crie nós automaticamente conforme necessário, usando os grupos de nós gerenciados (consulte Simplificar o ciclo de vida dos nós com grupos de nós gerenciados) ou o Karpenter
. Os grupos de nós gerenciados têm integrações com o ajuste de escala automático de clusters do Kubernetes. Usando as ferramentas de gerenciamento de nós, você pode se beneficiar da economia de custos graças a recursos como instâncias spot, consolidação e disponibilidade de nós e utilização de recursos de programação para definir como as workloads são implantadas e os nós são selecionados. -
Redes do cluster: usando modelos do CloudFormation, o
eksctlconfigura a rede entre os componentes do ambiente de gerenciamento e do plano de dados (nó) no cluster do Kubernetes. Ele também configura endpoints por meio dos quais as comunicações internas e externas podem ocorrer. Consulte Desmistificar redes de cluster para nós de processamento do Amazon EKSpara obter detalhes. As comunicações entre os Pods no Amazon EKS são realizadas por meio das Identidades de Pods do Amazon EKS (consulte Saiba como a Identidade de Pods do EKS concede aos pods acesso aos serviços da AWS), que fornecem uma maneira de permitir que os Pods utilizem métodos da AWS para gerenciar credenciais e permissões em nuvem. -
Complementos: o Amazon EKS evita que você tenha que criar e adicionar componentes de software que são comumente usados para dar suporte a clusters do Kubernetes. Por exemplo, quando você cria um cluster do Amazon EKS usando o AWS Management Console, ele adiciona automaticamente os complementos kube-proxy do Amazon EKS (Gerenciar o kube-proxy em clusters do Amazon EKS), plug-in da CNI da Amazon VPC para Kubernetes (Atribuir IPs a pods com a CNI da Amazon VPC) e CoreDNS (Gerenciar o CoreDNS para DNS em clusters do Amazon EKS). Consulte Complementos do Amazon EKS para obter mais informações sobre esses complementos, incluindo uma lista dos que estão disponíveis.
Para executar seus clusters em seus próprios computadores e redes on-premises, a Amazon oferece o Amazon EKS Anywhere
O Amazon EKS Anywhere é baseado no mesmo software Amazon EKS Distroetcd mais adiante neste documento).
Componentes do cluster
Os componentes do cluster do Kubernetes são divididos em duas áreas principais: ambiente de gerenciamento e nós de processamento. Os componentes do ambiente de gerenciamento
Ambiente de gerenciamento
O ambiente de gerenciamento consiste em um conjunto de serviços que gerenciam o cluster. Todos esses serviços podem ser executados em um único computador ou estar espalhados por vários computadores. Internamente, elas são chamadas de instâncias do ambiente de gerenciamento (CPIs). A forma como as CPIs são executadas depende do tamanho do cluster e dos requisitos de alta disponibilidade. Conforme a demanda aumenta no cluster, um serviço de ambiente de gerenciamento pode ser escalado para fornecer mais instâncias desse serviço, sendo as solicitações balanceadas entre as instâncias.
As tarefas realizadas pelos componentes do ambiente de gerenciamento do Kubernetes incluem:
-
Comunicação com os componentes do cluster (servidor de API): o servidor de API (kube-apiserver
) expõe a API do Kubernetes para que as solicitações ao cluster possam ser feitas de dentro e de fora do cluster. Em outras palavras, as solicitações para adicionar ou alterar os objetos de um cluster (pods, serviços, nós etc.) podem vir de comandos externos, como solicitações de kubectlpara executar um pod. Da mesma forma, as solicitações podem ser feitas do servidor da API para componentes dentro do cluster, como uma consulta ao serviçokubeletpara saber o status de um pod. -
Armazenamento de dados sobre o cluster (armazenamento do valor da chave
etcd): o serviçoetcdexerce o papel fundamental de registrar o estado atual do cluster. Se o serviçoetcdse tornasse inacessível, você não conseguiria atualizar ou consultar o status do cluster, embora as workloads continuassem sendo executadas por algum tempo. Por esse motivo, os clusters críticos geralmente têm várias instâncias do serviçoetcdcom balanceamento de carga em execução ao mesmo tempo e fazem backups periódicos do armazenamento dos valores de chave doetcdpara o caso de perda ou corrompimento de dados. Lembre-se de que, no Amazon EKS, tudo isso é gerenciado automaticamente para você por padrão. O Amazon EKS Anywhere fornece instruções sobre backup e restauração de etcd. Consulte o etcd Data Model para aprender como o etcdgerencia os dados. -
Agendar pods para nós (agendador): as solicitações para iniciar ou parar um pod no Kubernetes são direcionadas para o Agendador do Kubernetes
(kube-scheduler ). Como um cluster pode ter vários nós capazes de executar o pod, cabe ao agendador escolher em qual nó (ou nós, no caso de réplicas) o pod deve ser executado. Se não houver capacidade disponível suficiente para executar o pod solicitado em um nó existente, a solicitação falhará, a menos que você tenha feito outras provisões. Essas provisões podem incluir a habilitação de serviços, como grupos de nós gerenciados (Simplificar o ciclo de vida dos nós com grupos de nós gerenciados) ou Karpenter , que são capazes de iniciar automaticamente novos nós para gerenciar as workloads. -
Manter os componentes no estado desejado (Controller Manager): o Controller Manager do Kubernetes é executado como um processo daemon (kube-controller-manager
) para observar o estado do cluster e fazer alterações no cluster para restabelecer os estados esperados. Em particular, existem vários controladores que observam diferentes objetos do Kubernetes, incluindo um statefulset-controller,endpoint-controller,cronjob-controller,node-controllere outros. -
Gerenciar recursos de nuvem (Cloud Controller Manager): as interações entre o Kubernetes e o provedor de nuvem que realiza solicitações para os recursos subjacentes do data center são tratadas pelo Cloud Controller Manager
(cloud-controller-manager ). Os controladores gerenciados pelo Cloud Controller Manager podem incluir um controlador de rota (para configurar rotas de rede na nuvem), controlador de serviço (para usar serviços de balanceamento de carga na nuvem) e controlador de ciclo de vida de nós (para manter os nós sincronizados com o Kubernetes durante os ciclos de vida).
Nós de processamento (plano de dados)
Para um cluster do Kubernetes de nó único, as workloads são executadas na mesma máquina que o ambiente de gerenciamento. No entanto, uma configuração mais padrão é ter um ou mais sistemas de computador separados (nós
Quando você cria um cluster do Kubernetes pela primeira vez, algumas ferramentas de criação de clusters permitem configurar um determinado número de nós a serem adicionados ao cluster (seja identificando sistemas de computador existentes ou fazendo com que o provedor crie novos sistemas). Antes que qualquer workload seja adicionada a esses sistemas, serviços são adicionados a cada nó para implementar esses recursos:
-
Gerenciar cada nó (
kubelet): o servidor de API se comunica com o serviço kubeletem execução em cada nó para garantir que o nó esteja corretamente registrado e que os Pods solicitados pelo Agendador estejam em execução. O kubelet pode ler os manifestos do Pod e configurar volumes de armazenamento ou outros recursos necessários aos Pods no sistema local. Ele também pode verificar a integridade dos contêineres executados localmente. -
Executar contêineres em um nó (runtime do contêiner)- o runtime do contêiner
em cada nó gerencia os contêineres solicitados para cada pod atribuído ao nó. Isso significa que ele pode extrair imagens do contêiner do registro apropriado, executar o contêiner, interrompê-lo e responder às consultas sobre ele. O runtime de contêiner padrão é containerd . A partir da versão 1.24 do Kubernetes, a integração especial do Docker ( dockershim) que poderia ser usada como runtime de contêiner foi removida do Kubernetes. Embora ainda seja possível usar o Docker para testar e executar contêineres em seu sistema local, para usar o Docker com o Kubernetes, agora é necessário Instalar o mecanismo do Dockerem cada nó para usá-lo com o Kubernetes. -
Gerenciar a rede entre contêineres (
kube-proxy): para poder oferecer suporte à comunicação entre pods, o Kubernetes usa um recurso conhecido como Servicepara configurar redes de pods que rastreiam endereços IP e portas associados a esses pods. O serviço kube-proxy é executado em cada um dos nós para permitir que a comunicação entre os pods ocorra.
Cluster estendido
Há alguns serviços que podem ser adicionados ao Kubernetes para oferecer suporte ao cluster, mas eles não são executados no ambiente de gerenciamento. Esses serviços geralmente são executados diretamente em nós no namespace kube-system ou em seu próprio namespace (como geralmente é feito com provedores de serviços terceirizados). Um exemplo comum é o serviço CoreDNS, que fornece serviços de DNS ao cluster. Consulte Descobrindo serviços integrados
Há diferentes tipos de complementos que podem ser adicionados aos seus clusters. Para garantir a integridade dos seus clusters, é possível adicionar recursos de observabilidade (consulte Monitorar a performance de clusters e visualizara logs) que possibilitam atividades como registro de log, auditoria e métricas. Com essas informações, você pode solucionar problemas que ocorrem, geralmente por meio das mesmas interfaces de observabilidade. Exemplos desses tipos de serviços incluem o Amazon GuardDuty, o CloudWatch (consulte Monitorar dados de cluster com o Amazon CloudWatch), o AWS Distro para OpenTelemetry
Para obter uma lista mais completa dos complementos do Amazon EKS disponíveis, consulte Complementos do Amazon EKS.
Workloads
O Kubernetes define uma workload
Contêineres
O elemento mais básico de uma workload de aplicação que você implementa e gerencia no Kubernetes é um Pod
Como o pod é a menor unidade implantável, ele normalmente contém um único contêiner. No entanto, vários contêineres podem existir em um pod nos casos em que os contêineres estão fortemente acoplados. Por exemplo, um contêiner de servidor Web pode ser empacotado em um pod com um tipo de contêiner auxiliar
As especificações do pod (PodSpec
Enquanto um pod é a menor unidade que você pode implantar, um contêiner é a menor unidade que você cria e gerencia.
Criar contêineres
O pod é, na verdade, apenas uma estrutura em torno de um ou mais contêineres, onde cada contêiner contém o sistema de arquivos, executáveis, arquivos de configuração, bibliotecas e outros componentes para realmente executar a aplicação. Pelo fato de uma empresa chamada Docker Inc. ter popularizado os contêineres pela primeira vez, algumas pessoas se referem aos contêineres como contêineres do Docker. No entanto, desde então, a Open Container Initiative
Quando você cria um contêiner, normalmente começa com um Dockerfile (literalmente chamado assim). Dentro desse Dockerfile, é possível identificar:
-
Uma imagem de base- Uma imagem de contêiner de base é um contêiner normalmente criado a partir de uma versão mínima do sistema de arquivos de um sistema operacional (como o Red Hat Enterprise Linux
ou o Ubuntu ) ou de um sistema mínimo aprimorado para fornecer software para executar tipos específicos de aplicações (como aplicações nodejs ou python ). -
Software aplicação- Você pode adicionar o software aplicação ao contêiner da mesma forma que o adicionaria a um sistema Linux. Por exemplo, em seu Dockerfile, é possível executar
npmeyarnpara instalar uma aplicação Java ouyumednfpara instalar pacotes RPM. Em outras palavras, com um comando RUN em um Dockerfile, é possível executar qualquer comando que esteja disponível no sistema de arquivos da sua imagem base para instalar ou configurar o software dentro da imagem de contêiner resultante. -
Instruções- A referência do Dockerfile
descreve as instruções que você pode adicionar a um Dockerfile ao configurá-lo. Isso inclui instruções usadas para criar o que está no próprio contêiner ( ADDouCOPYarquivos do sistema local), identificar comandos para executar quando o contêiner for executado (CMDouENTRYPOINT) e conectar o contêiner ao sistema em que ele é executado (identificando oUSERde execução, umVOLUMElocal para montagem ou as portas paraEXPOSE).
Embora o comando docker e o serviço tenham sido tradicionalmente usados para criar containers (docker build), outras ferramentas disponíveis para criar imagens de contêineres incluem podman
Armazenamento de contêineres
Após criar sua imagem de contêiner, você poderá armazená-la em um registro de distribuição
Para armazenar imagens de contêiner de forma mais pública, é possível enviá-las para um registro de contêiner público. Os registros de contêineres públicos fornecem um local central para armazenar e distribuir imagens de contêineres. Exemplos de registros de contêineres públicos incluem o Amazon Elastic Container Registry
Ao executar workloads em contêineres no Amazon Elastic Kubernetes Service (Amazon EKS), recomendamos obter cópias de imagens oficiais do Docker armazenadas no Amazon Elastic Container Registry. O Amazon ECR armazena essas imagens desde 2021. Você pode pesquisar imagens de contêineres populares na Galeria Pública do Amazon ECR
Depure contêineres em execução
Como os contêineres são criados em um formato padrão, um contêiner pode ser executado em qualquer máquina capaz de executar um runtime de contêiner (como o Docker) e cujo conteúdo corresponda à arquitetura da máquina local (como x86_64 ou arm). Para testar um contêiner ou simplesmente executá-lo em seu desktop local, você pode usar nossos comandos docker run ou podman run para iniciar um contêiner no host local. Para o Kubernetes, no entanto, cada nó de processamento tem um runtime de contêiner implantado, e cabe ao Kubernetes solicitar que um nó execute um contêiner.
Depois que um contêiner é designado para ser executado em um nó, o nó verifica se a versão solicitada da imagem do contêiner já existe nesse nó. Do contrário, o Kubernetes solicita ao runtime do contêiner que extraia esse contêiner do registro de contêiner apropriado e, em seguida, execute esse contêiner localmente. Lembre-se de que uma imagem de contêiner refere-se ao pacote de software que é movido entre seu laptop, o registro de contêiner e os nós do Kubernetes. Um contêiner se refere a uma instância em execução dessa imagem.
Pods
Quando seus contêineres estiverem prontos, trabalhar com os pods inclui configurar, implantar e tornar os pods acessíveis.
Configuração de pods
Ao definir um pod, você atribui um conjunto de atributos a ele. Esses atributos devem incluir pelo menos o nome do pod e a imagem de contêiner a ser executada. No entanto, há muitas outras coisas que podem ser configuradas com as definições do pod (consulte a página PodSpec
-
Armazenamento: quando um contêiner em execução é interrompido e excluído, o armazenamento de dados nesse contêiner desaparece, a menos que você configure um armazenamento mais permanente. O Kubernetes é compatível com muitos tipos diferentes de armazenamento e os abstrai sob o conceito de Volumes
. Os tipos de armazenamento incluem CephFS , NFS , iSCSI e outros. Você pode até mesmo usar um dispositivo de blocos local conectado ao computador local. Com um desses tipos de armazenamento disponíveis em seu cluster, é possível montar o volume de armazenamento em um ponto de montagem selecionado no sistema de arquivos do seu contêiner. Um volume persistente é aquele que continua existindo depois que o pod é excluído, enquanto um volume efêmero é removido quando o pod é excluído. Se o administrador do cluster tiver criado diferentes StorageClasses para o cluster, talvez você tenha a opção de escolher os recursos do armazenamento que você usa como, por exemplo, se o volume é excluído ou recuperado após o uso, se ele se expandirá se for necessário mais espaço e até mesmo se ele atende a determinados requisitos de performance. -
Segredos- ao disponibilizar Segredos
para os contêineres nas especificações do Pod, você pode fornecer as permissões de que esses contêineres precisam para acessar sistemas de arquivos, bancos de dados ou outros ativos protegidos. Chaves, senhas e tokens estão entre os itens que podem ser armazenados como segredos. O uso de segredos faz com que você não precise armazenar essas informações em imagens de contêineres, mas apenas disponibilizá-los para contêineres em execução. Semelhantes aos segredos são os ConfigMaps . Um ConfigMaptende a conter informações menos críticas, como pares de chave-valor para configurar um serviço. -
Recursos de contêineres- os objetos para configuração adicional de contêineres podem assumir a forma de configuração de recursos. Para cada contêiner, é possível solicitar a quantidade de memória e CPU que ele pode usar, bem como impor limites para a quantidade total desses recursos que o contêiner pode usar. Consulte Gerenciamento de recursos para pods e contêineres
para obter exemplos. -
Interrupções- os pods podem ser interrompidos involuntariamente (um nó fica inoperante) ou voluntariamente (uma atualização é desejada). Ao configurar um orçamento de interrupção do pod
, é possível exercer algum controle sobre a disponibilidade da sua aplicação quando interrupções ocorrem. Consulte Especificação de um orçamento de interrupção para sua aplicação para obter exemplos. -
Namespaces: o Kubernetes oferece diferentes maneiras de isolar os componentes e as workloads do Kubernetes uns dos outros. Executar todos os pods de uma aplicação específica no mesmo Namespace
é uma forma comum de proteger e gerenciar esses pods juntos. Você pode criar seus próprios namespaces para usar ou optar por não indicar um namespace (o que faz com que o Kubernetes use o namespace default). Os componentes do ambiente de gerenciamento do Kubernetes geralmente são executados no namespace kube-system.
A configuração descrita acima geralmente está reunida em um arquivo YAML para ser aplicada ao cluster do Kubernetes. Para clusters do Kubernetes pessoais, basta armazenar esses arquivos YAML em seu sistema local. No entanto, com clusters e workloads mais críticos, o GitOps
Os objetos usados para reunir e implantar as informações do pod são definidos por um dos seguintes métodos de implantação.
Implantar pods
O método que você escolheria para implantar pods depende do tipo de aplicação que você planeja executar com esses pods. Algumas das opções disponíveis são:
-
Aplicações stateless: uma aplicação stateless não salva os dados da sessão de um cliente, de modo que outra sessão não precisa consultar o que aconteceu em uma sessão anterior. Isso torna mais fácil simplesmente substituir os pods por novos caso eles percam a integridade ou movê-los sem salvar o estado. Se você executar uma aplicação sem estado (como um servidor web), poderá usar uma implantação
para implantar pods e ReplicaSets . Um ReplicaSet define quantas instâncias de um pod você deseja executar simultaneamente. Embora seja possível executar um ReplicaSet diretamente, é comum executar réplicas diretamente em uma implantação para definir quantas réplicas de um pod devem ser executadas por vez. -
Aplicações stateful: uma aplicação stateful é aquela em que a identidade do pod e a ordem em que os pods são iniciados são importantes. Essas aplicações precisam de armazenamento persistente que seja estável e que precise ser implantado e escalado de forma consistente. Para implantar uma aplicação com estado no Kubernetes, é possível usar StatefulSets
. Um exemplo de aplicação que normalmente é executada como StatefulSet é um banco de dados. Em um StatefulSet, é possível definir réplicas, o pod e seus contêineres, volumes de armazenamento a serem montados e locais no contêiner em que os dados são armazenados. Consulte Executar uma aplicação com estado replicada para obter um exemplo de banco de dados sendo implantado como um ReplicaSet. -
Aplicações por nó: há ocasiões em que você deseja executar uma aplicação em todos os nós do cluster do Kubernetes. Por exemplo, seu data center pode exigir que cada computador execute uma aplicação de monitoramento ou um serviço de acesso remoto específico. Para o Kubernetes, é possível usar um DaemonSet
para garantir que a aplicação selecionada seja executada em todos os nós do seu cluster. -
Aplicações executadas até a conclusão: há algumas aplicações que você deseja executar para concluir uma determinada tarefa. Isso pode incluir uma que gere relatórios de status mensais ou limpe dados antigos. Um objeto Job
pode ser usado para configurar uma aplicação para inicializar e executar e, em seguida, sair quando a tarefa for concluída. Um objeto CronJob permite configurar uma aplicação para ser executado em uma hora, minuto, dia do mês, mês ou dia da semana específicos usando uma estrutura definida pelo formato crontab do Linux.
Como tornar as aplicações acessíveis via rede
Com as aplicações sendo frequentemente implantadas como um conjunto de microsserviços que se movem para diversos lugares, o Kubernetes precisava de um modo de permitir que esses microsserviços se localizarem um ao outro. Além disso, para que outras pessoas pudessem acessar uma aplicação fora do cluster do Kubernetes, ele precisava de uma forma para expor essa aplicação em endereços e portas externos. Esses recursos relacionados à rede são implementados com objetos Service e Ingress, respectivamente:
-
Serviços: como um pod pode se deslocar para diferentes nós e endereços, outro pod que precise se comunicar com o primeiro pode ter dificuldade para localizá-lo. Para resolver esse problema, o Kubernetes permite representar uma aplicação como um Service
. Com um Service, é possível identificar um pod ou conjunto de pods com um nome específico e, em seguida, indicar qual porta expõe o serviço dessa aplicação a partir do pod e quais portas outra aplicação poderia usar para entrar em contato com esse serviço. Outro pod em um cluster pode simplesmente solicitar um serviço pelo nome, que o Kubernetes direcionará essa solicitação para a porta adequada para uma instância do pod executando esse serviço. -
Ingress: Ingress
é o que pode tornar as aplicações representadas pelos serviços do Kubernetes disponíveis para clientes que estão fora do cluster. Os recursos básicos de Ingress incluem um balanceador de carga (gerenciado pelo Ingress), o controlador do Ingress e regras para rotear solicitações do controlador para o Service. Existem vários controladores do Ingress que você pode escolher com o Kubernetes.
Próximas etapas
Compreender os conceitos básicos do Kubernetes e como eles se relacionam com o Amazon EKS ajudará você a navegar na documentação do Amazon EKS e na documentação do Kubernetes
