Habilitação da representação do usuário para monitorar a atividade de usuários e trabalhos do Spark
Os Cadernos do EMR permitem configurar a representação do usuário em um cluster do Spark. Esse recurso ajuda a rastrear a atividade do trabalho iniciado no editor de blocos de anotações. Além disso, os Cadernos do EMR têm um widget do caderno Jupyter integrado para visualizar detalhes do trabalho do Spark junto com a saída da consulta no editor de cadernos. O widget está disponível por padrão e não requer configuração especial. No entanto, para visualizar os servidores de históricos, o cliente deve estar configurado para visualizar interfaces Web do Amazon EMR hospedadas no nó primário.
nota
Os cadernos do EMR estão disponíveis como Workspaces do EMR Studio no console. O botão Criar Workspace no console permite criar cadernos. Para acessar ou criar Workspaces, os usuários dos Cadernos do EMR precisam de permissões adicionais de perfil do IAM. Para obter mais informações, consulte Amazon EMR Notebooks are Amazon EMR Studio Workspaces in the console e console do Amazon EMR.
Configuração da representação do usuário do Spark
Por padrão, os trabalhos do Spark que os usuários enviam usando o editor de blocos de anotações parecem se originar de uma identidade de usuário livy indiscriminada. Você pode configurar a representação do usuário para o cluster para que esses trabalhos sejam associados à identidade de usuário que executou o código. Os diretórios de usuários do HDFS no nó primário são criados para cada identidade de usuário que executa códigos no caderno. Por exemplo, se o usuário NbUser1 executar o código do editor de cadernos, é possível se conectar ao nó primário e ver que hadoop fs -ls /user mostra o diretório /user/user_NbUser1.
Para habilitar esse recurso, configure as propriedades nas classificações de configuração livy-conf e core-site. Esse recurso não está disponível por padrão quando o Amazon EMR cria um cluster em conjunto com um caderno. Para obter mais informações sobre como usar classificações de configuração para personalizar aplicações, consulte Configuring applications no Guia de lançamento do Amazon EMR.
Use as seguintes classificações e valores de configuração para habilitar a representação do usuário para os Cadernos do EMR:
[ { "Classification": "core-site", "Properties": { "hadoop.proxyuser.livy.groups": "*", "hadoop.proxyuser.livy.hosts": "*" } }, { "Classification": "livy-conf", "Properties": { "livy.impersonation.enabled": "true" } } ]
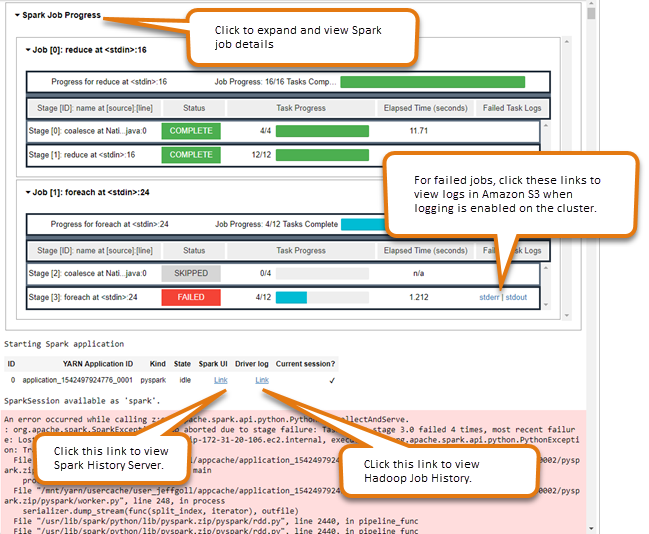
Uso do widget de monitoramento de trabalhos do Spark
Quando você executa código no editor de blocos de anotações que executam trabalhos do Spark no cluster do EMR, a saída inclui um widget de bloco de anotações Jupyter para monitoramento de trabalhos do Spark. O widget fornece detalhes do trabalho e links úteis para a página do servidor de histórico do Spark e para a página de histórico de trabalhos do Hadoop, além de links convenientes para logs de trabalho no Amazon S3 para todos os trabalhos com falha.
Para visualizar as páginas do servidor de histórico no nó primário do cluster, você deve configurar um cliente SSH e um proxy, conforme apropriado. Para ter mais informações, consulte Visualizar interfaces Web hospedadas em clusters do Amazon EMR. Para visualizar os logs no Amazon S3, o registro em log do cluster deve estar habilitado, que é o padrão para os novos clusters. Para ter mais informações, consulte Visualizar arquivos de log arquivados no Amazon S3.
A seguir é apresentado um exemplo de monitoramento de trabalhos do Spark.