As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Depuração de aplicações e trabalhos com o EMR Studio
Com o Amazon EMR Studio, você pode iniciar interfaces de aplicações de dados para analisar aplicações e execuções de trabalhos no navegador.
Você também pode iniciar interfaces do usuário persistentes externas ao cluster para o Amazon EMR em execução em clusters do EC2 no console do Amazon EMR. Para obter mais informações, consulte Exibir interfaces do usuário de aplicações persistentes no Amazon EMR.
Com base nas configurações do seu navegador, pode ser necessário habilitar pop-ups para a abertura da interface do usuário de uma aplicação.
Para obter informações sobre como configurar e usar as interfaces da aplicação, consulte The YARN Timeline Server, Monitoring and Instrumentation ou Tez UI Overview.
Depuração do Amazon EMR em execução em trabalhos do Amazon EC2
- Workspace UI
-
Inicialização de uma interface do usuário no cluster usando um arquivo de caderno
Ao usar as versões 5.33.0 e posteriores do Amazon EMR, você pode iniciar a interface do usuário da Web do Spark (a interface do usuário do Spark ou o servidor de histórico do Spark) de um caderno no seu Workspace.
On-cluster As UIs funcionam com PySpark os kernels Spark ou SparkR. O tamanho máximo de arquivo visível para logs de eventos ou para logs de contêineres do Spark é de 10 MB. Se seus arquivos de log excederem 10 MB, recomendamos usar o servidor de histórico do Spark persistente em vez da interface do usuário do Spark no cluster para depurar trabalhos.
Para que o EMR Studio inicie interfaces do usuário de aplicações no cluster usando um Workspace, um cluster deve ser capaz de se comunicar com o Amazon API Gateway. Você deve configurar o cluster do EMR para permitir o tráfego de rede de saída para o Amazon API Gateway e certificar-se de que o Amazon API Gateway possa ser acessado pelo cluster.
A interface do usuário do Spark acessa os logs de contêineres ao resolver nomes de host. Se você usar um nome de domínio personalizado, deverá se certificar de que os nomes de host dos nós do cluster possam ser resolvidos pelo DNS da Amazon ou pelo servidor DNS especificado. Para fazer isso, defina as opções do Protocolo de Configuração Dinâmica de Host (DHCP) para a Amazon Virtual Private Cloud (VPC) associada ao seu cluster. Para obter mais informações sobre as opções do DHCP, consulte Conjuntos de opções DHCP no Guia do usuário da Amazon Virtual Private Cloud.
-
No EMR Studio, abra o Workspace que você deseja usar e certifique-se de que ele esteja conectado a um cluster do Amazon EMR em execução no EC2. Para instruções, consulte Anexar uma computação a um Workspace do EMR Studio.
-
Abra um arquivo de notebook e use o PySpark kernel, Spark ou SparkR. Para selecionar um kernel, escolha o nome do kernel no canto superior direito da barra de ferramentas do caderno para abrir a caixa de diálogo Selecionar kernel. O nome aparecerá como Nenhum Kernel! se nenhum kernel tiver sido selecionado.
-
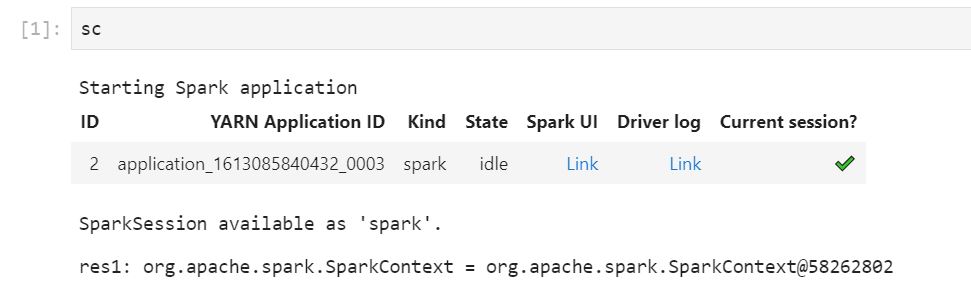
Execute o código do seu caderno. Quando você inicia o Spark Context, o apresentado a seguir aparece como a saída no caderno. Pode demorar alguns segundos para que a aparição ocorra. Se você iniciou o Spark Context, poderá executar o comando %%info para acessar um link para a interface do usuário do Spark a qualquer momento.
Se os links da interface do usuário do Spark não funcionarem ou não aparecerem após alguns segundos, crie uma nova célula de caderno e execute o comando %%info para gerar os links novamente.
-
Para iniciar a interface do usuário do Spark, escolha Link em IU do Spark. Se a aplicação do Spark estiver em execução, a interface do usuário do Spark será aberta em uma nova guia. Se aplicação estiver sido concluída, o servidor de histórico do Spark será aberto.
Depois de iniciar a interface do usuário do Spark, você pode modificar a URL no navegador para abrir o YARN ResourceManager ou o Yarn Timeline Server. Adicione um dos caminhos apresentados a seguir depois de amazonaws.com.
| Interface do usuário da Web |
Path |
Exemplo de URL modificado |
| FIO ResourceManager |
/rm |
j-examplebby5ijhttps://.emrappui-prod. eu-west-1.amazonaws.com /rm |
| Servidor de linha do tempo do YARN |
/yts |
j-examplebby5ijhttps://.emrappui-prod. eu-west-1.amazonaws.com /yts |
| Servidor de histórico do Spark |
/shs |
j-examplebby5ijhttps://.emrappui-prod. eu-west-1.amazonaws.com /shs
|
- Studio UI
-
Inicialização do servidor de linha do tempo do YARN persistente, do servidor de histórico do Spark ou da interface do usuário do Tez usando a interface do usuário do EMR Studio
-
No EMR Studio, selecione Amazon EMR no EC2 no lado esquerdo da página para abrir a lista de clusters do Amazon EMR no EC2.
-
Filtre a lista de clusters por nome, estado ou ID ao inserir valores na caixa de pesquisa. Você também pode pesquisar por intervalo de tempo de criação.
-
Selecione um cluster e, em seguida, escolha Iniciar as interfaces do usuário da aplicação para selecionar uma interface do usuário da aplicação. A interface do usuário da aplicação abre em uma nova guia do navegador e pode demorar algum tempo para carregar.
Depure o EMR Studio em execução no EMR Serverless
Semelhante ao Amazon EMR executado no Amazon EC2, você pode usar a interface de usuário do Workspace para analisar suas aplicações do EMR Serverless. Na interface do usuário do Workspace, ao usar as versões 6.14.0 e posteriores do Amazon EMR, você pode iniciar a interface do usuário da Web do Spark (a interface do usuário do Spark ou o servidor de histórico do Spark) de um caderno no seu Workspace. Para sua conveniência, também fornecemos um link para o log do driver para acesso rápido aos logs do driver do Spark.
Depuração de execuções de trabalhos do Amazon EMR no EKS com o servidor de histórico do Spark
Ao enviar uma execução de trabalho para um cluster do Amazon EMR no EKS, você pode acessar os logs dessa execução de trabalho usando o servidor de histórico do Spark. O servidor de histórico do Spark fornece ferramentas para o monitoramento de aplicações do Spark, como uma lista de estágios e de tarefas do programador, um resumo dos tamanhos de RDD e do uso de memória e informações sobre o ambiente. Você pode iniciar o servidor de histórico do Spark para as execuções de trabalhos do Amazon EMR no EKS das seguintes maneiras:
-
Ao enviar uma execução de trabalho usando o EMR Studio com um endpoint gerenciado do Amazon EMR no EKS, é possível iniciar o servidor de histórico do Spark usando um arquivo de caderno em seu Workspace.
-
Ao enviar uma execução de trabalho usando o AWS SDK AWS CLI ou para Amazon EMR no EKS, você pode iniciar o Spark History Server a partir da interface do EMR Studio.
Para obter informações sobre como usar o servidor de histórico do Spark, consulte Monitoring and Instrumentation na documentação do Apache Spark. Para obter mais informações sobre as execuções de trabalhos, consulte Conceitos e componentes no Guia de desenvolvimento do Amazon EMR no EKS.
Iniciar o servidor de histórico do Spark usando um arquivo de caderno no Workspace do EMR Studio
-
Abra um Workspace conectado a um cluster do Amazon EMR no EKS.
-
Selecione e abra seu arquivo de caderno no Workspace.
-
Escolha IU do Spark na parte superior do arquivo de caderno para abrir o servidor de histórico do Spark persistente em uma nova guia.
Iniciar o servidor de histórico do Spark usando a interface do usuário do EMR Studio
A lista de trabalhos na interface do usuário do EMR Studio exibe somente as execuções de trabalhos que você envia usando o AWS SDK AWS CLI ou o SDK para Amazon EMR no EKS.
-
No EMR Studio, selecione Amazon EMR no EKS no lado esquerdo da página.
-
Pesquise o cluster virtual do Amazon EMR no EKS que você usou para enviar a execução de trabalho. É possível filtrar a lista de clusters por status ou ID ao inserir valores na caixa de pesquisa.
-
Selecione o cluster para abrir a página de detalhes dele. A página de detalhes exibe informações sobre o cluster, como o ID, o namespace e o status. A página também mostra uma lista com todas as execuções de trabalhos enviadas para esse cluster.
-
Na página de detalhes do cluster, selecione uma execução de trabalho para depurar.
-
No canto superior à direita da lista Trabalhos, escolha Iniciar servidor de histórico do Spark para abrir a interface da aplicação em uma nova guia do navegador.