Noções básicas sobre métricas de ajuste de escala gerenciado no Amazon EMR
O Amazon EMR publica métricas de alta resolução com dados em uma granularidade de um minuto quando o ajuste de escala gerenciado está habilitado em um cluster. É possível visualizar eventos em cada iniciação e conclusão de redimensionamento controlada pelo ajuste de escala gerenciado usando o console do Amazon EMR ou o console do Amazon CloudWatch. As métricas do CloudWatch são essenciais para a operação do Ajuste de Escala Gerenciado do Amazon EMR. É recomendável monitorar atentamente as métricas do CloudWatch para garantir que os dados não estejam ausentes. Para obter mais informações sobre como configurar os alarmes do CloudWatch para detectar métricas ausentes, consulte Usar alarmes do Amazon CloudWatch. Para obter mais informações sobre como usar eventos do CloudWatch com o Amazon EMR, consulte Monitor CloudWatch events.
As métricas a seguir indicam as capacidades atuais ou de destino de um cluster. Essas métricas só estão disponíveis quando a escalabilidade gerenciada está habilitada. Para clusters compostos por frotas de instâncias, as métricas de capacidade de cluster são medidas em Units. Para clusters compostos por grupos de instâncias, as métricas de capacidade de cluster são medidas em Nodes ou vCPU com base no tipo de unidade usado na política de escalabilidade gerenciada.
| Métrica | Descrição |
|---|---|
|
O número total desejado de unidades/nós/vCPUs em um cluster, conforme determinado pela escalabilidade gerenciada. Unidades: Contagem |
|
O número total atual de unidades/nós/vCPUs disponíveis em um cluster em execução. Quando um redimensionamento de cluster for solicitado, essa métrica será atualizada depois que as novas instâncias forem adicionadas ou removidas do cluster. Unidades: Contagem |
|
O número desejado de unidades/nós/vCPUs CORE em um cluster, conforme determinado pela escalabilidade gerenciada. Unidades: Contagem |
|
O número atual de unidades/nós/vCPUs CORE em execução em um cluster. Unidades: Contagem |
|
O número desejado de unidades/nós/vCPUs TASK em um cluster, conforme determinado pela escalabilidade gerenciada. Unidades: Contagem |
|
O número atual de unidades/nós/vCPUs TASK em execução em um cluster. Unidades: Contagem |
As métricas a seguir indicam o status de uso do cluster e dos aplicativos. Essas métricas estão disponíveis para todos os recursos do Amazon EMR mas são publicadas em uma resolução mais alta com dados em uma granularidade de um minuto quando o ajuste de gerenciado é habilitado para um cluster. É possível correlacionar as métricas a seguir com as métricas de capacidade do cluster na tabela anterior para entender as decisões de escalabilidade gerenciada.
| Métrica | Descrição |
|---|---|
|
|
O número de aplicativos enviados para o YARN que foram concluídos. Caso de uso: monitorar o progresso do cluster Unidades: Contagem |
|
|
O número de aplicativos enviados para o YARN em estado pendente. Caso de uso: monitorar o progresso do cluster Unidades: Contagem |
|
|
O número de aplicativos enviados para o YARN que estão em execução. Caso de uso: monitorar o progresso do cluster Unidades: Contagem |
ContainerAllocated |
O número de contêineres de recurso alocados pelo ResourceManager. Caso de uso: monitorar o progresso do cluster Unidades: Contagem |
|
|
O número de contêineres na fila que ainda não foram alocados. Caso de uso: monitorar o progresso do cluster Unidades: Contagem |
ContainerPendingRatio |
A relação de contêineres pendentes para contêineres alocados (ContainerPendingRatio = ContainerPending / ContainerAllocated). Se ContainerAllocated = 0, ContainerPendingRatio = ContainerPending. O valor de ContainerPendingRatio representa um número, e não uma porcentagem. Esse valor é útil para escalonar recursos de cluster com base no comportamento de alocação do contêiner. Unidades: Contagem |
|
|
O percentual de armazenamento do HDFS em uso no momento. Caso de uso: analisar a performance do cluster Unidade: percentual |
|
|
Indica que um cluster não está mais executando nenhum trabalho, mas ainda está ativo e acumulando cobranças. É definido como 1 se nenhuma tarefa ou nenhum trabalho estiver em execução, caso contrário, é definido como 0. Esse valor é verificado em intervalos de 5 minutos, sendo que um valor de 1 indica somente que o cluster estava ocioso no momento da verificação, e não que ele ficou ocioso durante todo o período de 5 minutos. Para evitar falsos positivos, é necessário gerar um alarme quando esse valor for 1 em mais de uma verificação consecutiva de cinco minutos. Por exemplo, você pode gerar um alerta para esse valor se ele for 1 por 30 minutos ou mais. Caso de uso: monitorar a performance do cluster Unidade: booliano |
|
|
A quantidade de memória disponível para ser alocada. Caso de uso: monitorar o progresso do cluster Unidades: Contagem |
|
|
O número de nós executando tarefas ou trabalhos MapReduce no momento. Equivalente ao Caso de uso: monitorar o progresso do cluster Unidades: Contagem |
|
|
A porcentagem de memória restante disponível para YARN (YARNMemoryAvailablePercentage = MemoryAvailableMB / MemoryTotalMB). Esse valor é útil para escalonar recursos de cluster com base no uso da memória YARN. Unidade: percentual |
Criar grafos de métricas de ajuste de escala gerenciado
É possível criar grafos de métricas para visualizar os padrões de workload do cluster e as decisões de ajuste de escala correspondentes tomadas pelo Ajuste de Escala Gerenciado do Amazon EMR, conforme demonstrado nas etapas a seguir.
Como criar gráficos de métricas de escalabilidade gerenciada no console do CloudWatch
-
Abra o console do CloudWatch
. -
No painel de navegação, escolha o Amazon EMR. Você pode pesquisar com base no identificador do cluster para monitoramento.
-
Role para baixo até a métrica para exibição em gráfico. Abra uma métrica para exibir o gráfico.
-
Para criar um gráfico de uma ou mais métricas, marque a caixa de seleção ao lado de cada métrica.
O exemplo a seguir ilustra a ação de Ajuste de Escala Gerenciado do Amazon EMR de um cluster. O gráfico mostra três períodos de redução automática, que economizam custos quando há uma workload menos ativa.
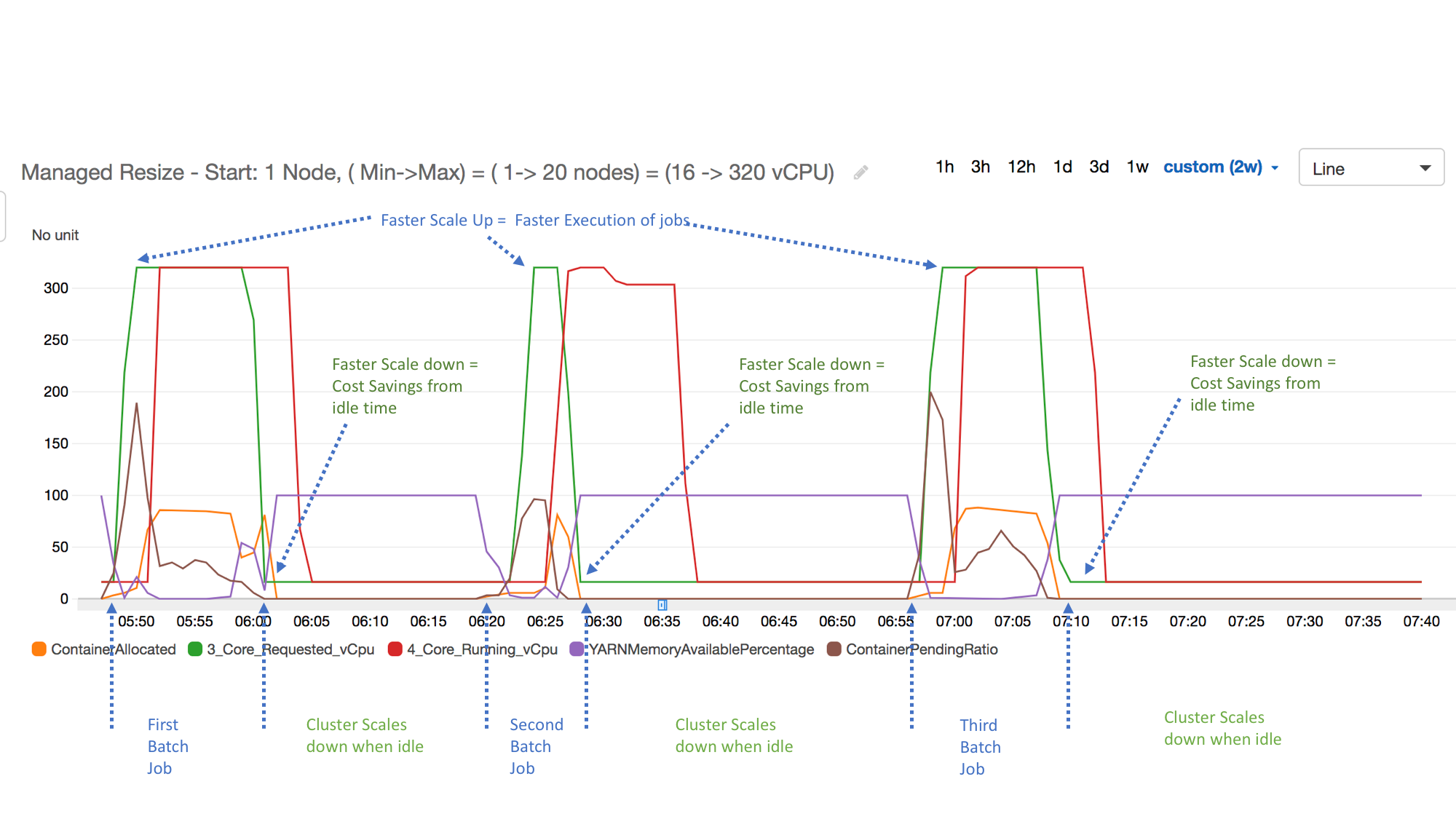
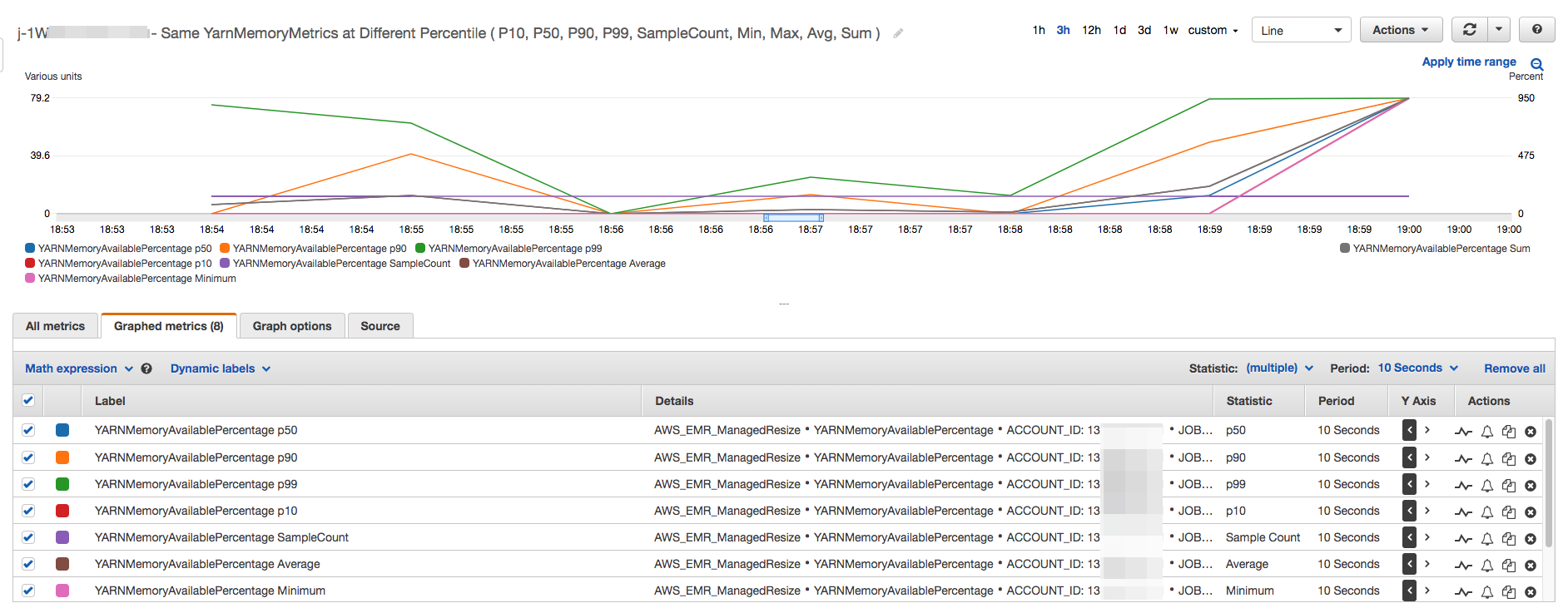
Todas as métricas de capacidade e uso do cluster são publicadas em intervalos de um minuto. As informações estatísticas adicionais também estão associadas a cada dado de um minuto, o que permite representar várias funções como Percentiles, Min, Max, Sum, Average e SampleCount.
Por exemplo, o gráfico a seguir representa graficamente a mesma métrica YARNMemoryAvailablePercentage em percentis diferentes, P10, P50, P90 e P99, juntamente com Sum, Average, Min e SampleCount.