As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como o Iceberg funciona
O Iceberg rastreia arquivos de dados individuais em uma tabela em vez de em diretórios. Dessa forma, os gravadores podem criar arquivos de dados no local (os arquivos não são movidos nem alterados). Além disso, os gravadores só podem adicionar arquivos à tabela em uma confirmação explícita. O estado da tabela é mantido em arquivos de metadados. Todas as alterações no estado da tabela criam um novo arquivo de metadados que substitui atomicamente os metadados antigos. O arquivo de metadados da tabela rastreia o esquema da tabela, a configuração do particionamento e outras propriedades.
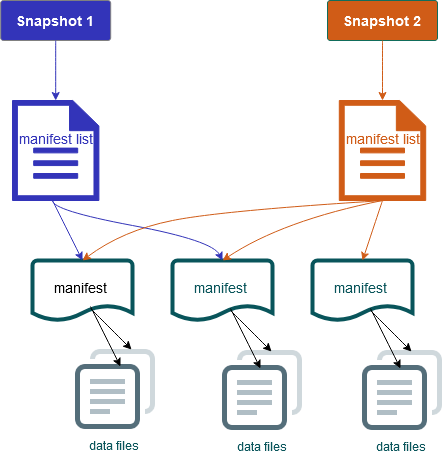
Ele também inclui snapshots do conteúdo da tabela. Cada snapshot é um conjunto completo de arquivos de dados na tabela em um momento específico. Os snapshots são listados no arquivo de metadados, mas os arquivos de um snapshot são armazenados em arquivos manifesto separados. As transições atômicas de um arquivo de metadados da tabela para o próximo fornecem isolamento de snapshots. Os leitores usam o instantâneo que estava atualizado quando carregaram os metadados da tabela. Os leitores não são afetados pelas alterações até atualizarem e escolherem um novo local de metadados. Arquivos de dados em snapshots são armazenados em um ou mais arquivos manifesto que contêm uma linha para cada arquivo de dados na tabela, seus dados de partição e suas métricas. Um snapshot é a união de todos os arquivos nos seus manifestos. Os arquivos manifesto também podem ser compartilhados entre snapshots para evitar a regravação de metadados que são alterados com pouca frequência.
Diagrama de snapshots do Iceberg
O Iceberg oferece os seguintes atributos:
-
Oferece suporte a ACID transações e viagens no tempo em seu data lake do Amazon S3.
-
As novas tentativas de confirmação se beneficiam das vantagens de performance da simultaneidade otimista
. -
A resolução de conflitos em nível de arquivo resulta em alta simultaneidade.
-
Com estatísticas mínimas e máximas por coluna nos metadados, você pode pular arquivos, o que aumenta a performance de consultas seletivas.
-
Você pode organizar tabelas em layouts de partição flexíveis, com a evolução da partição permitindo atualizações nos esquemas de partição. As consultas e os volumes de dados podem, então, mudar sem contar com diretórios físicos.
-
Oferece suporte à evolução e à aplicação do esquema
. -
As tabelas do Iceberg funcionam como coletores idempotentes e fontes reproduzíveis. Isso permite streaming e suporte em lote com pipelines exatamente uma vez. Os coletores idempotentes rastreiam operações de gravação que foram bem-sucedidas no passado. Portanto, o coletor pode solicitar dados novamente em caso de falha e descartar dados que tiverem sido enviados várias vezes.
-
Visualize o histórico e a linhagem, incluindo evolução da tabela, o histórico de operações e as estatísticas de cada confirmação.
-
Migre de um conjunto de dados existente com uma opção de formato de dados (ParquetORC, Avro) e mecanismo de análise (Spark, Trino, PrestoDB, Flink, Hive).
