As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
JupyterHub
O Jupyter Notebook
O Sparkmagic é uma biblioteca de kernels que permite que os notebooks Jupyter interajam com o Apache Spark executado na Amazon EMR por meio de, que é um servidor para o Spark
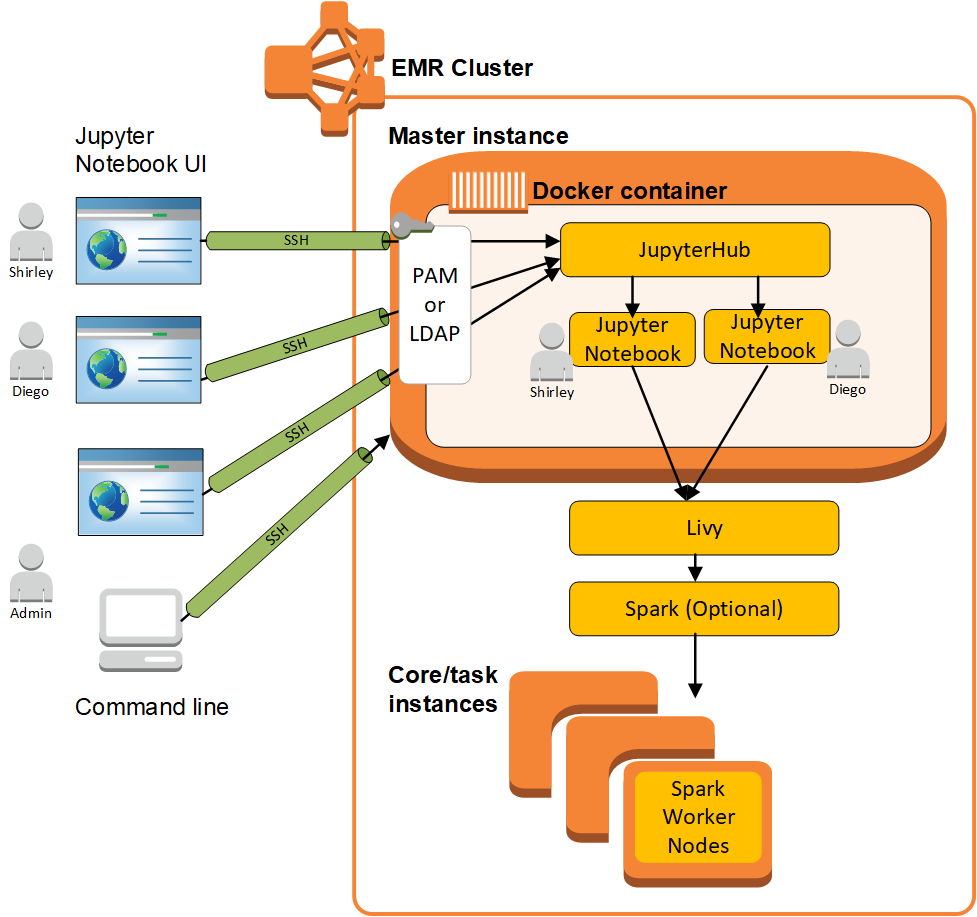
O diagrama a seguir mostra os componentes do JupyterHub na Amazon EMR com os métodos de autenticação correspondentes para usuários de notebooks e administradores. Para obter mais informações, consulte Adicionar usuários e administradores do Caderno Jupyter.
A tabela a seguir lista a versão JupyterHub incluída na versão mais recente da série Amazon EMR 7.x, junto com os componentes com os quais a Amazon é EMR instalada. JupyterHub
Para a versão dos componentes instalados JupyterHub nesta versão, consulte Versões de componentes da versão 7.5.0.
| Gravadora EMR de lançamento da Amazon | JupyterHub Versão | Componentes instalados com JupyterHub |
|---|---|---|
emr-7.5.0 |
JupyterHub 1.5.0 |
emrfs, emr-goodies, emr-ddb, hadoop-client, hadoop-hdfs-datanode, hadoop-hdfs-library, hadoop-hdfs-namenode, hadoop-kms-server, hadoop-yarn-nodemanager, hadoop-yarn-resourcemanager, hadoop-yarn-timeline-server, hudi, hudi-spark, r, spark-client, spark-history-server, spark-on-yarn, spark-yarn-slave, livy-server, jupyterhub |
A tabela a seguir lista a versão JupyterHub incluída na versão mais recente da série EMR 6.x da Amazon, junto com os componentes com os quais a Amazon é EMR instalada. JupyterHub
Para a versão dos componentes instalados JupyterHub nesta versão, consulte Versões de componentes da versão 6.15.0.
| Gravadora EMR de lançamento da Amazon | JupyterHub Versão | Componentes instalados com JupyterHub |
|---|---|---|
emr-6.15.0 |
JupyterHub 1.5.0 |
aws-sagemaker-spark-sdk, emrfs, emr-goodies, emr-ddb, hadoop-client, hadoop-hdfs-datanode, hadoop-hdfs-library, hadoop-hdfs-namenode, hadoop-kms-server, hadoop-yarn-nodemanager, hadoop-yarn-resourcemanager, hadoop-yarn-timeline-server, hudi, hudi-spark, r, spark-client, spark-history-server, spark-on-yarn, spark-yarn-slave, livy-server, jupyterhub |
A tabela a seguir lista a versão JupyterHub incluída na versão mais recente da série Amazon EMR 5.x, junto com os componentes com os quais a Amazon é EMR instalada. JupyterHub
Para a versão dos componentes instalados JupyterHub nesta versão, consulte Versões de componentes da versão 5.36.2.
| Gravadora EMR de lançamento da Amazon | JupyterHub Versão | Componentes instalados com JupyterHub |
|---|---|---|
emr-5.36.2 |
JupyterHub 1.4.1 |
aws-sagemaker-spark-sdk, emrfs, emr-goodies, emr-ddb, hadoop-client, hadoop-hdfs-datanode, hadoop-hdfs-library, hadoop-hdfs-namenode, hadoop-kms-server, hadoop-yarn-nodemanager, hadoop-yarn-resourcemanager, hadoop-yarn-timeline-server, hudi, hudi-spark, r, spark-client, spark-history-server, spark-on-yarn, spark-yarn-slave, livy-server, jupyterhub |
O kernel do Python 3 incluído na JupyterHub Amazon EMR é o 3.6.4.
As bibliotecas instaladas no jupyterhub contêiner podem variar entre as versões de EMR lançamento da Amazon e as EC2 AMI versões da Amazon.
Para listar bibliotecas instaladas usando o conda
Execute o seguinte comando na linha de comandos do nó principal:
sudo docker exec jupyterhub bash -c "conda list"
Para listar bibliotecas instaladas usando o pip
Execute o seguinte comando na linha de comandos do nó principal:
sudo docker exec jupyterhub bash -c "pip freeze"
Tópicos
- Crie um cluster com JupyterHub
- Considerações ao usar JupyterHub na Amazon EMR
- Configurando JupyterHub
- Configurar a persistência de cadernos no Amazon S3
- Conectar-se ao nó principal e aos servidores de cadernos
- JupyterHub configuração e administração
- Adicionar usuários e administradores do Caderno Jupyter
- Instalar Kernels e bibliotecas adicionais
- JupyterHub histórico de lançamentos
