As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Configurando o Flink na Amazon EMR
Configurar o Flink com o Hive Metastore e o Catálogo do Glue
As EMR versões 6.9.0 e superiores da Amazon oferecem suporte ao Hive Metastore e ao AWS Glue Catalog com o conector Apache Flink para o Hive. Esta seção descreve as etapas necessárias para configurar o Catálogo do AWS Glue e o Hive Metastore com o Flink.
Usar o Hive Metastore
-
Crie um EMR cluster com a versão 6.9.0 ou superior e pelo menos dois aplicativos: Hive e Flink.
-
Use script runner para executar o script a seguir como função de etapa:
hive-metastore-setup.shsudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar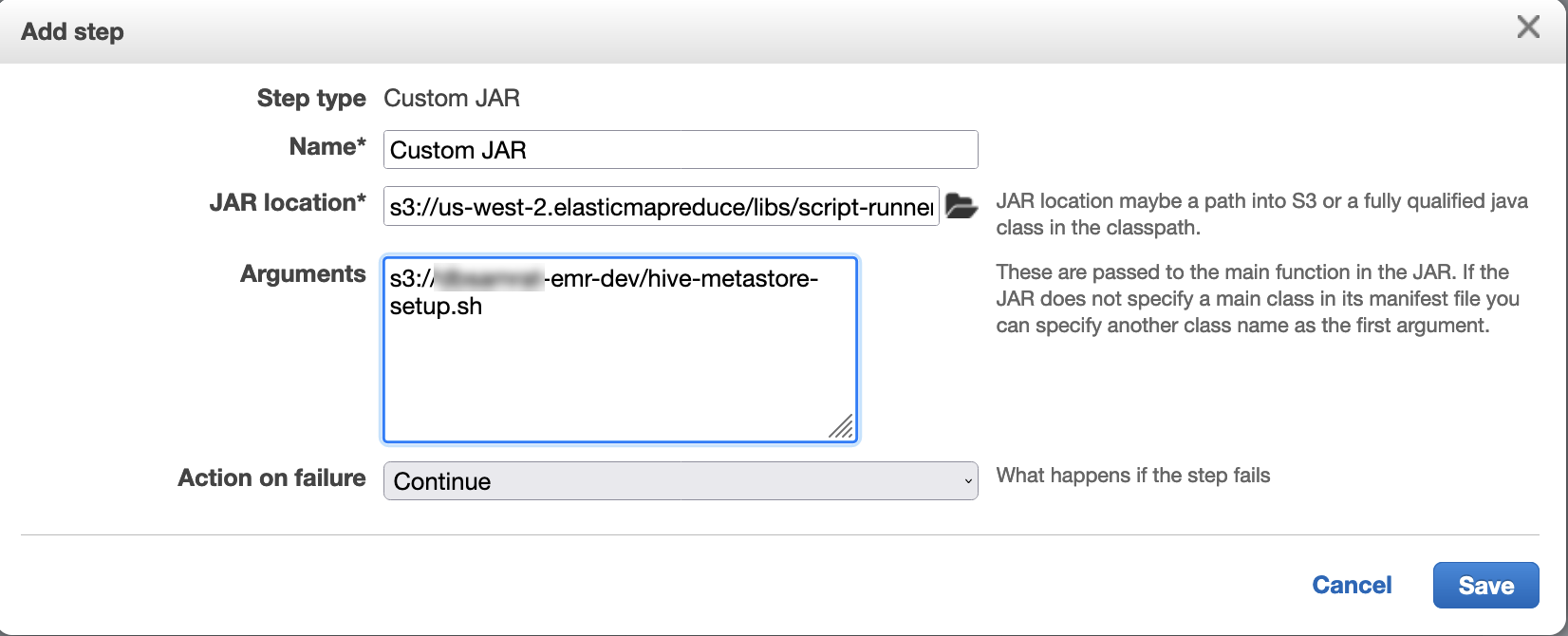
Use o catálogo de dados AWS Glue
-
Crie um EMR cluster com a versão 6.9.0 ou superior e pelo menos dois aplicativos: Hive e Flink.
-
Selecione Usar com metadados da tabela do Hive nas configurações do Catálogo de Dados do AWS Glue para habilitar o Catálogo de Dados no cluster.
-
Use o script runner para executar o seguinte script como uma função de etapa: Execute comandos e scripts em um EMR cluster da Amazon:
glue-catalog-setup.sh
sudo cp /usr/lib/hive/auxlib/aws-glue-datacatalog-hive3-client.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib sudo cp /usr/lib/hive/lib/hive-exec-3.1.3*.jar /lib/flink/lib sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib sudo chmod 755 /usr/lib/flink/lib/aws-glue-datacatalog-hive3-client.jar sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar sudo chmod 755 /usr/lib/flink/lib/hive-exec-3.1.3*.jar sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar
Configurar o Flink com um arquivo de configuração
Você pode usar a EMR configuração da Amazon API para configurar o Flink com um arquivo de configuração. Os arquivos que podem ser configurados no API são:
-
flink-conf.yaml -
log4j.properties -
flink-log4j-session -
log4j-cli.properties
O principal arquivo de configuração para o Flink é flink-conf.yaml.
Configurar o número de slots de tarefa que são usados para o Flink na AWS CLI
-
Crie um arquivo
configurations.json, com o seguinte conteúdo:[ { "Classification": "flink-conf", "Properties": { "taskmanager.numberOfTaskSlots":"2" } } ] -
Em seguida, crie um cluster com a seguinte configuração:
aws emr create-cluster --release-labelemr-7.3.0\ --applications Name=Flink \ --configurations file://./configurations.json \ --regionus-east-1\ --log-uri s3://myLogUri\ --instance-type m5.xlarge \ --instance-count2\ --service-role EMR_DefaultRole_V2 \ --ec2-attributes KeyName=YourKeyName,InstanceProfile=EMR_EC2_DefaultRole
nota
Você também pode alterar algumas configurações com o API Flink. Para obter mais informações, consulte Concepts
Com a Amazon EMR versão 5.21.0 e posterior, você pode substituir as configurações do cluster e especificar classificações de configuração adicionais para cada grupo de instâncias em um cluster em execução. Você faz isso usando o EMR console da Amazon, o AWS Command Line Interface (AWS CLI) ou AWS SDK o. Para obter mais informações, consulte Supplying a Configuration for an Instance Group in a Running Cluster.
Opções de paralelismo
Como proprietário da aplicação, você sabe quais recursos atribuir a tarefas no Flink. Para os exemplos nesta documentação, use o mesmo número de tarefas que as instâncias de tarefa que você usa para a aplicação. Geralmente, recomendamos isso para o nível de paralelismo inicial, mas também é possível aumentar a granularidade do paralelismo usando slots de tarefa, que geralmente não excedem o número de núcleos virtuais
Configurando o Flink em um EMR cluster com vários nós primários
O JobManager do Flink permanece disponível durante o processo de failover do nó primário em um EMR cluster da Amazon com vários nós primários. A partir do Amazon EMR 5.28.0, a JobManager alta disponibilidade também é ativada automaticamente. Nenhuma configuração manual é necessária.
Com EMR as versões 5.27.0 ou anteriores da Amazon, esse JobManager é um único ponto de falha. Quando o JobManager falha, ele perde todos os estados de trabalho e não retoma os trabalhos em execução. Você pode ativar a JobManager alta disponibilidade configurando a contagem de tentativas do aplicativo, marcando o ponto de verificação e ativando o armazenamento ZooKeeper como estado para o Flink, conforme demonstra o exemplo a seguir:
[ { "Classification": "yarn-site", "Properties": { "yarn.resourcemanager.am.max-attempts": "10" } }, { "Classification": "flink-conf", "Properties": { "yarn.application-attempts": "10", "high-availability": "zookeeper", "high-availability.zookeeper.quorum": "%{hiera('hadoop::zk')}", "high-availability.storageDir": "hdfs:///user/flink/recovery", "high-availability.zookeeper.path.root": "/flink" } } ]
Você deve configurar o máximo de tentativas principais de aplicativo YARN e de tentativas de aplicativo para o Flink. Para obter mais informações, consulte Configuração da alta disponibilidade do YARN cluster
Configurar o tamanho do processo de memória
Para EMR versões da Amazon que usam o Flink 1.11.x, você deve configurar o tamanho total do processo de memória para JobManager (jobmanager.memory.process.size) e TaskManager (taskmanager.memory.process.size) in. flink-conf.yaml Você pode definir esses valores configurando o cluster com a configuração API ou descomentando manualmente esses campos via. SSH O Flink fornece os valores padrão a seguir.
-
jobmanager.memory.process.size: 1600m -
taskmanager.memory.process.size: 1728m
Para excluir JVM metasespaço e sobrecarga, use o tamanho total da memória do Flink () taskmanager.memory.flink.size em vez de. taskmanager.memory.process.size O valor padrão para taskmanager.memory.process.size é 1280m. Não é recomendável definir taskmanager.memory.process.size e taskmanager.memory.process.size.
Todas as EMR versões da Amazon que usam o Flink 1.12.0 e posteriores têm os valores padrão listados no conjunto de código aberto do Flink como valores padrão na AmazonEMR, então você não precisa configurá-los sozinho.
Configurar o tamanho do arquivo de saída de log
Os contêineres de aplicações Flink criam e gravam em três tipos de arquivos de log: arquivos .out, arquivos .log e arquivos .err. Somente os arquivos .err são compactados e removidos do sistema de arquivos, enquanto os arquivos de log .log e .out permanecem no sistema de arquivos. Para garantir que esses arquivos de saída continuem gerenciáveis e que o cluster continue estável, é possível configurar a alternância de logs log4j.properties para definir um número máximo de arquivos e limitar o tamanho deles.
Amazon EMR versões 5.30.0 e posteriores
A partir do Amazon EMR 5.30.0, o Flink usa a estrutura de registro log4j2 com o nome de classificação de configuração. O exemplo de configuração a seguir demonstra flink-log4j. o formato log4j2.
[ { "Classification": "flink-log4j", "Properties": { "appender.main.name": "MainAppender", "appender.main.type": "RollingFile", "appender.main.append" : "false", "appender.main.fileName" : "${sys:log.file}", "appender.main.filePattern" : "${sys:log.file}.%i", "appender.main.layout.type" : "PatternLayout", "appender.main.layout.pattern" : "%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n", "appender.main.policies.type" : "Policies", "appender.main.policies.size.type" : "SizeBasedTriggeringPolicy", "appender.main.policies.size.size" : "100MB", "appender.main.strategy.type" : "DefaultRolloverStrategy", "appender.main.strategy.max" : "10" }, } ]
Amazon EMR versões 5.29.0 e anteriores
Com EMR as versões 5.29.0 e anteriores da Amazon, o Flink usa a estrutura de registro log4j. O exemplo de configuração a seguir demonstra o formato log4j.
[ { "Classification": "flink-log4j", "Properties": { "log4j.appender.file": "org.apache.log4j.RollingFileAppender", "log4j.appender.file.append":"true", # keep up to 4 files and each file size is limited to 100MB "log4j.appender.file.MaxFileSize":"100MB", "log4j.appender.file.MaxBackupIndex":4, "log4j.appender.file.layout":"org.apache.log4j.PatternLayout", "log4j.appender.file.layout.ConversionPattern":"%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n" }, } ]
Configurar o Flink para ser executado com o Java 11
As EMR versões 6.12.0 e superiores da Amazon oferecem suporte ao tempo de execução do Java 11 para o Flink. As seções a seguir descrevem como configurar o cluster para fornecer suporte ao runtime do Java 11 para o Flink.
Tópicos
Configurar o Flink para Java 11 ao criar um cluster
Use as etapas a seguir para criar um EMR cluster com o tempo de execução do Flink e do Java 11. O arquivo de configuração ao qual você adiciona suporte ao runtime do Java 11 é flink-conf.yaml.
Configurar o Flink para Java 11 em um cluster em execução
Use as etapas a seguir para atualizar um EMR cluster em execução com o Flink e o Java 11 runtime. O arquivo de configuração ao qual você adiciona suporte ao runtime do Java 11 é flink-conf.yaml.
Confirmar o runtime do Java para o Flink em um cluster em execução
Para determinar o tempo de execução Java para um cluster em execução, faça login no nó primário com SSH conforme descrito em Conecte-se ao nó primário com SSH. Em seguida, execute o seguinte comando:
ps -ef | grep flink
O comando ps com a opção -ef lista todos os processos que estão em execução no sistema. É possível filtrar essa saída com grep para encontrar menções à string flink. Revise a saída do valor do Java Runtime Environment (JRE),jre-XX. Na saída a seguir, jre-11 indica que o Java 11 está selecionado em runtime para o Flink.
flink 19130 1 0 09:17 ? 00:00:15 /usr/lib/jvm/jre-11/bin/java -Djava.io.tmpdir=/mnt/tmp -Dlog.file=/usr/lib/flink/log/flink-flink-historyserver-0-ip-172-31-32-127.log -Dlog4j.configuration=file:/usr/lib/flink/conf/log4j.properties -Dlog4j.configurationFile=file:/usr/lib/flink/conf/log4j.properties -Dlogback.configurationFile=file:/usr/lib/flink/conf/logback.xml -classpath /usr/lib/flink/lib/flink-cep-1.17.0.jar:/usr/lib/flink/lib/flink-connector-files-1.17.0.jar:/usr/lib/flink/lib/flink-csv-1.17.0.jar:/usr/lib/flink/lib/flink-json-1.17.0.jar:/usr/lib/flink/lib/flink-scala_2.12-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-java-uber-1.17.0.jar:/usr/lib/flink/lib/flink-table-api-scala-bridge_2.12-1.17.0.
Como alternativa, faça login no nó primário com SSH e inicie uma YARN sessão do Flink com o comandoflink-yarn-session -d. A saída mostra a Java Virtual Machine (JVM) para Flink, java-11-amazon-corretto no exemplo a seguir:
2023-05-29 10:38:14,129 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: containerized.master.env.JAVA_HOME, /usr/lib/jvm/java-11-amazon-corretto.x86_64
