As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Usar trabalhos do Flink pelo Zeppelin no Amazon EMR
Introdução
O Amazon EMR 6.10.0 e versões posteriores oferecem suporte à integração de Apache Zeppelin com o Apache Flink. É possível enviar trabalhos do Flink de forma interativa por meio dos cadernos Zeppelin. Com o intérprete Flink, é possível executar consultas do Flink, definir trabalhos em lote e de transmissão do Flink e visualizar a saída nos cadernos Zeppelin. O intérprete Flink foi desenvolvido com base na API REST do Flink. Isso possibilita acessar e manipular trabalhos do Flink de dentro do ambiente Zeppelin para realizar processamento e análise de dados em tempo real.
Há quatro subintérpretes no intérprete Flink. Eles servem a outras finalidades, mas estão todos na JVM e compartilham os mesmos pontos de entrada pré-configurados do Flink (ExecutionEnviroment, StreamExecutionEnvironment, BatchTableEnvironment, StreamTableEnvironment). Os intérpretes são estes:
-
%flink: criaExecutionEnvironment,StreamExecutionEnvironment,BatchTableEnvironment,StreamTableEnvironmente fornece um ambiente Scala -
%flink.pyflink: fornece um ambiente Python -
%flink.ssql: fornece um ambiente SQL de transmissão -
%flink.bsql: fornece um ambiente SQL em lote
Pré-requisitos
-
A integração do Zeppelin com o Flink é compatível com clusters criados com o Amazon EMR 6.10.0 e versões posteriores.
-
Para visualizar as interfaces Web hospedadas em clusters do EMR conforme necessário para essas etapas, é necessário configurar um túnel SSH para permitir o acesso de entrada. Para obter mais informações, consulte Configure proxy settings to view websites hosted on the primary node.
Configurar o Zeppelin-Flink em um cluster do EMR
Realize as etapas a seguir para configurar o Apache Flink no Apache Zeppelin para ser executado em um cluster do EMR:
-
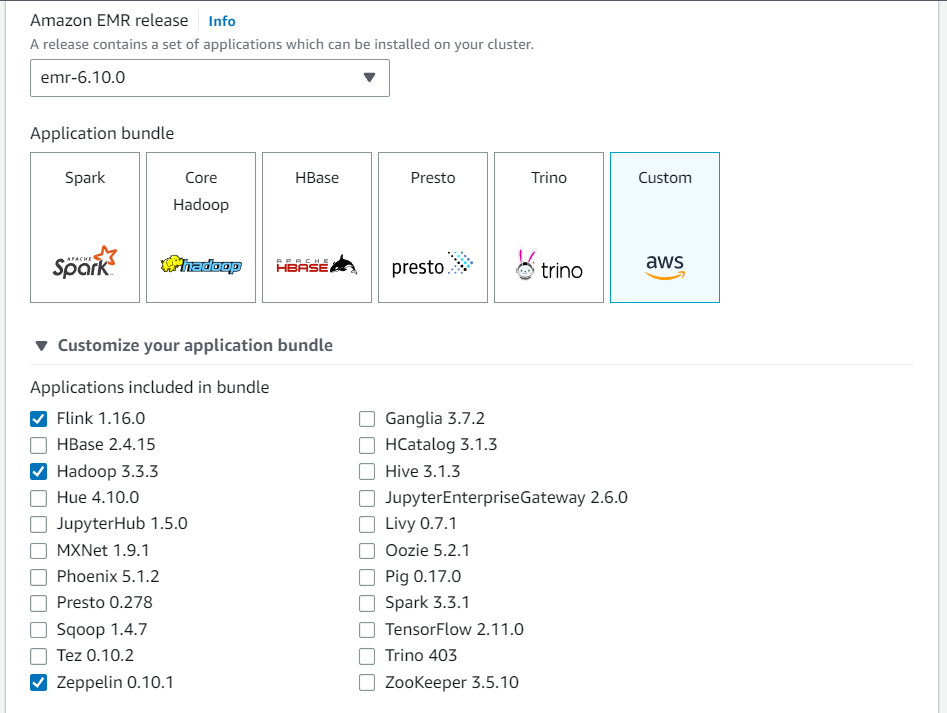
Crie um novo cluster pelo console do Amazon EMR. Selecione a versão emr-6.10.0 ou posterior do Amazon EMR. Em seguida, escolha personalizar seu pacote de aplicações com a opção Personalizado. Inclua, no mínimo, Flink, Hadoop e Zeppelin no pacote.
-
Crie o resto do cluster com as configurações de sua preferência.
-
Quando o cluster estiver em execução, selecione o cluster no console para visualizar os detalhes e abra a guia Aplicações. Selecione Zeppelin na seção Interfaces de usuário da aplicação para abrir a interface da Web do Zeppelin. Configure o acesso à interface da Web do Zeppelin com um túnel SSH para o nó primário e uma conexão proxy, conforme descrito em Pré-requisitos.
-
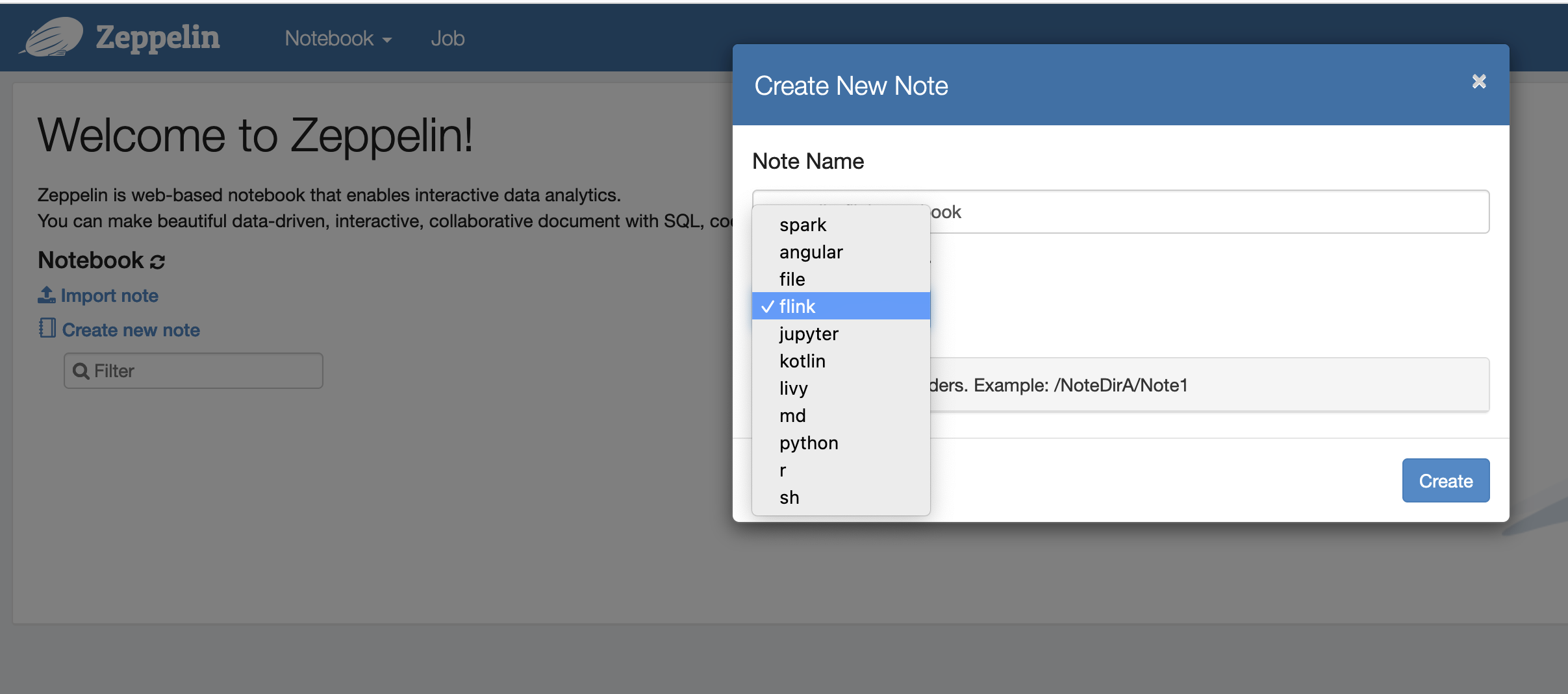
Agora, você pode criar uma nova nota em um caderno do Zeppelin usando o Flink como intérprete padrão.
-
Consulte os exemplos de código a seguir que demonstram como executar trabalhos do Flink em um caderno do Zeppelin.
Executar trabalhos do Flink com o Zeppelin-Flink em um cluster do EMR
-
Exemplo 1, Flink Scala
a) WordCount Exemplo de Batch (SCALA)
%flink val data = benv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .groupBy(0) .sum(1) .print()b) WordCount Exemplo de streaming (SCALA)
%flink val data = senv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .keyBy(0) .sum(1) .print senv.execute()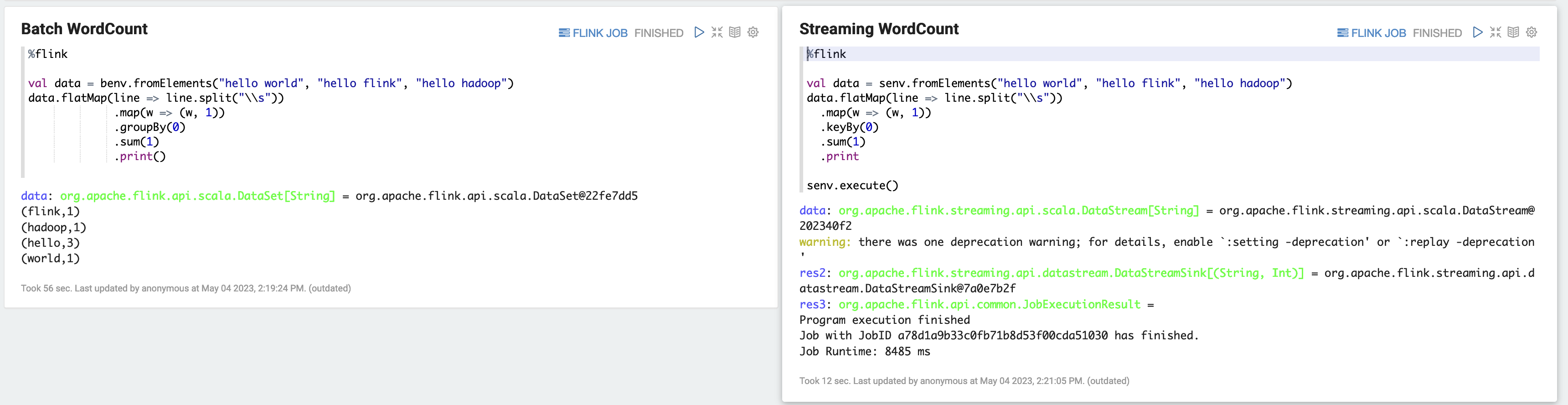
-
Exemplo 2, Flink Streaming SQL
%flink.ssql SET 'sql-client.execution.result-mode' = 'tableau'; SET 'table.dml-sync' = 'true'; SET 'execution.runtime-mode' = 'streaming'; create table dummy_table ( id int, data string ) with ( 'connector' = 'filesystem', 'path' = 's3://s3-bucket/dummy_table', 'format' = 'csv' ); INSERT INTO dummy_table SELECT * FROM (VALUES (1, 'Hello World'), (2, 'Hi'), (2, 'Hi'), (3, 'Hello'), (3, 'World'), (4, 'ADD'), (5, 'LINE')); SELECT * FROM dummy_table;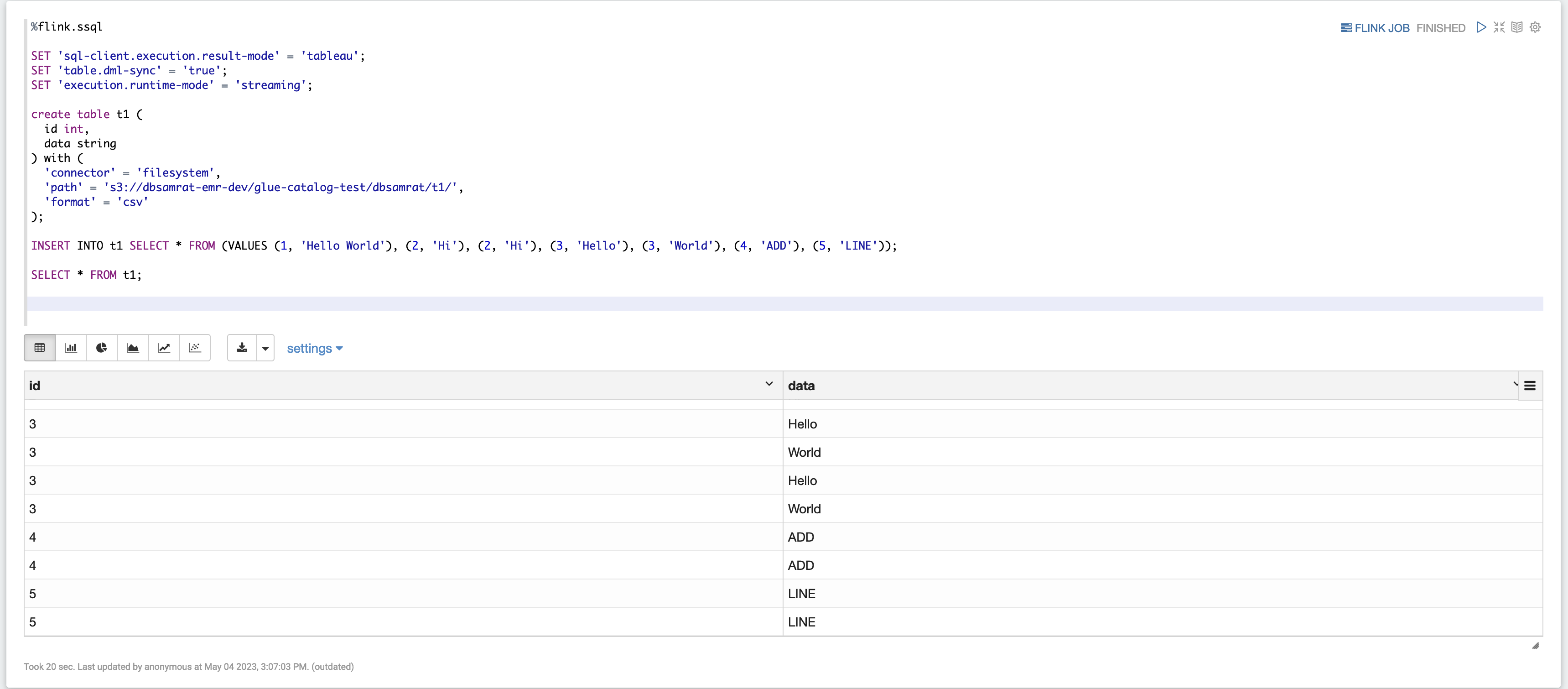
-
Exemplo 3, Pyflink. Observe que você deve fazer upload da sua própria amostra de arquivo de texto chamada
word.txtno bucket do S3.%flink.pyflink import argparse import logging import sys from pyflink.common import Row from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema, DataTypes, FormatDescriptor) from pyflink.table.expressions import lit, col from pyflink.table.udf import udtf def word_count(input_path, output_path): t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) # write all the data to one file t_env.get_config().set("parallelism.default", "1") # define the source if input_path is not None: t_env.create_temporary_table( 'source', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .build()) .option('path', input_path) .format('csv') .build()) tab = t_env.from_path('source') else: print("Executing word_count example with default input data set.") print("Use --input to specify file input.") tab = t_env.from_elements(map(lambda i: (i,), word_count_data), DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])) # define the sink if output_path is not None: t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .option('path', output_path) .format(FormatDescriptor.for_format('canal-json') .build()) .build()) else: print("Printing result to stdout. Use --output to specify output path.") t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('print') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .build()) @udtf(result_types=[DataTypes.STRING()]) def split(line: Row): for s in line[0].split(): yield Row(s) # compute word count tab.flat_map(split).alias('word') \ .group_by(col('word')) \ .select(col('word'), lit(1).count) \ .execute_insert('sink') \ .wait() logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s") word_count("s3://s3_bucket/word.txt", "s3://s3_bucket/demo_output.txt")
-
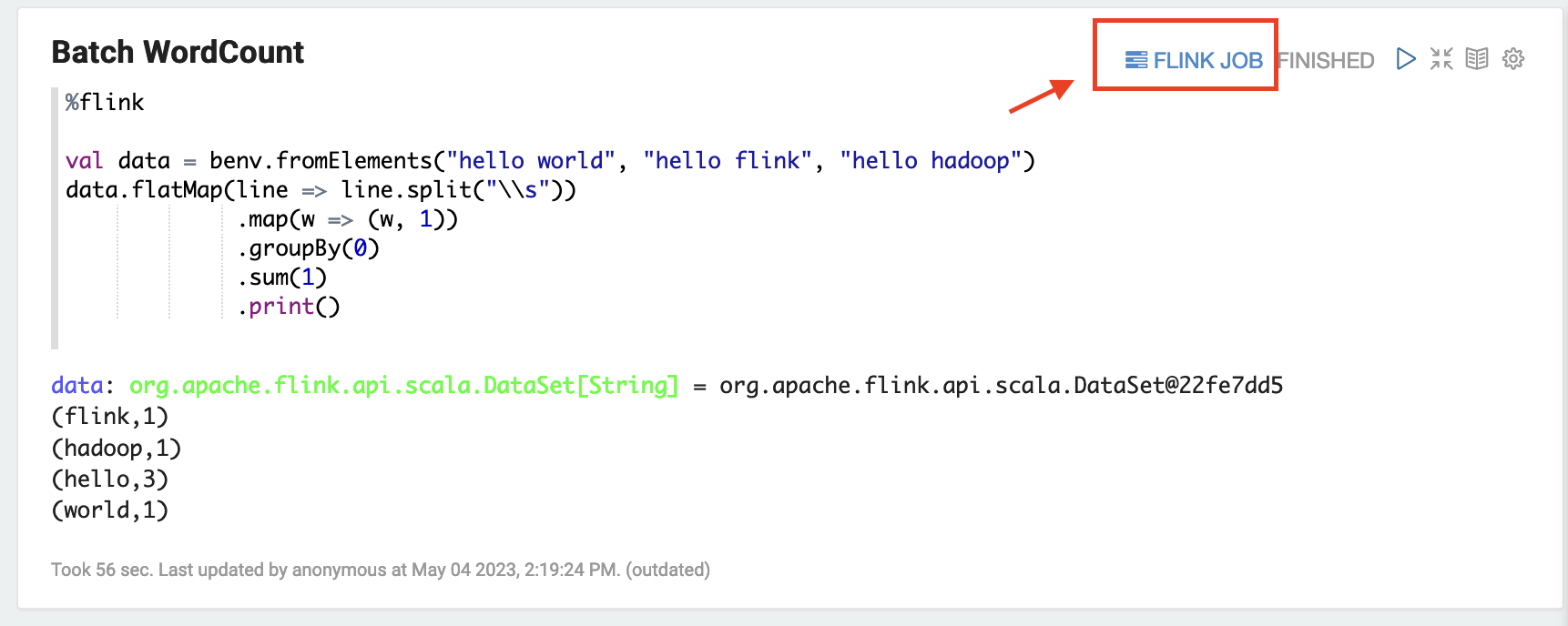
Escolha TRABALHO DO FLINK na interface do usuário do Zeppelin para acessar e visualizar a interface do usuário Web do Flink.
-
Escolher TRABALHO DO FLINK encaminhará o console Web do Flink para outra guia do navegador.