O Amazon Forecast não está mais disponível para novos clientes. Os clientes existentes do Amazon Forecast podem continuar usando o serviço normalmente. Saiba mais
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Algoritmo DeepAR+
A DeepAR+ do Amazon Forecast é um algoritmo de aprendizagem para prever séries temporais escalares (uma dimensão) usando redes neurais recorrentes (RNNs). Os métodos de previsão clássicos, como o Média móvel integrada autorregressiva (ARIMA - Autoregressive integrated moving average) ou o Suavização exponencial (ETS - Exponential smoothing), adequam um único modelo a cada série temporal e usam esse modelo para extrapolar as séries temporais para o futuro. Em muitos aplicativos, no entanto, você pode ter muitas séries temporais semelhantes em um conjunto de unidades transversais. Esses agrupamentos de série temporal exigem diferentes produtos, cargas de servidor e solicitações de páginas da web. Nesse caso, pode ser útil treinar um modelo único conjuntamente sobre todas essas séries temporais. A DeepAR+ usa essa abordagem. Quando o conjunto de dados contém centenas de recursos de série temporal, o algoritmo DeepAR+ supera os métodos padrão ARIMA e ETS. Você também pode usar o modelo treinado para gerar previsões para novas séries temporais que são semelhantes às que você já treinou.
cadernos em Python
Como funciona o DeepAR+
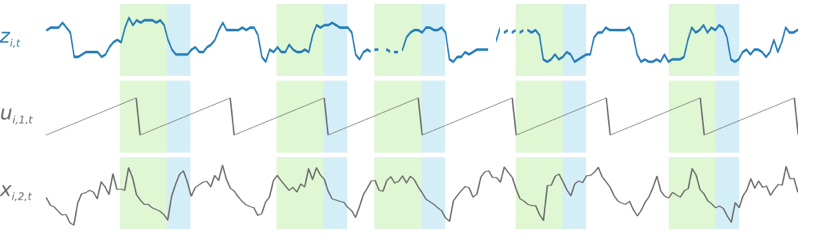
Durante o treinamento, a DeepAR+ usa um conjunto de dados de treinamento e um conjunto de dados de teste opcional. Ela usa o conjunto de dados de teste para avaliar o modelo treinado. Em geral, os conjuntos de dados de treinamento e de teste não precisam conter o mesmo conjunto de série temporal. Você pode usar um modelo treinado em um determinado conjunto de treinamento para gerar previsões para o futuro da série temporal nesse conjunto de treinamento e para outras séries temporais. Os conjuntos de dados de treinamento e de teste consistem em séries temporais de destino (de preferência, mais de uma). Opcionalmente, eles podem ser associados a um vetor de série temporal de recursos e a um vetor de recursos categóricos (para obter detalhes, consulte Interface de entrada/saída da DeepAR no Guia do desenvolvedor do ). O exemplo a seguir mostra como isso funciona para um elemento de um conjunto de dados de treinamento indexado por i. O conjunto de dados de treinamento consiste em uma série temporal de destino, zi,t, e duas séries temporais de recursos associadas, xi,1,t e xi,2,t.

A série temporal de destino pode conter valores ausentes (indicados nos gráficos por quebras na série temporal). A DeepAR+ é compatível apenas com séries temporais de recursos que são conhecidas no futuro. Isso permite que você execute situações "e se" contrafatuais. Por exemplo, "O que acontecerá se eu alterar o preço de um produto de alguma forma?"
Cada série temporal de destino também pode ser associada a vários recursos categóricos. Você pode usar esses para codificar que uma série temporal pertence a determinados agrupamentos. O uso de recursos categóricos permite que o modelo aprenda o comportamento típico para esses agrupamentos, o que pode aumentar a precisão. Um modelo implementa isso aprendendo um vetor de incorporação para cada grupo que captura as propriedades comuns a todas as séries temporais do grupo.
Para facilitar os padrões dependentes de tempo, como picos durante fins de semana, a DeepAR+ cria séries temporais de recursos automaticamente com base na granularidade da série temporal. Por exemplo, a DeepAR+ cria duas séries temporais de recursos (dia do mês e dia do ano) em uma série temporal semanal. Ela usa essas séries temporais de recursos derivados junto com a série temporal de recursos personalizada que você fornece durante o treinamento e a inferência. O exemplo a seguir mostra dois recursos de série temporal derivada: ui,1,t representa a hora do dia, e ui,2,t, o dia da semana.

A DeepAR+ inclui essa série temporal de recursos automaticamente com base na frequência e no tamanho dos dados de treinamento. A tabela a seguir lista os recursos que podem ser derivados para cada frequência básica de tempo com suporte.
| Frequência da série temporal | Recursos derivados |
|---|---|
| Minuto | minuto da hora, hora do dia, dia da semana, dia do mês, dia do ano |
| Hora | hora do dia, dia da semana, dia do mês, dia do ano |
| Dia | dia da semana, dia do mês, dia do ano |
| Semana | dia do mês, semana do ano |
| Mês | mês do ano |
Um modelo de DeepAR+ é treinado por amostragem aleatória de vários exemplos de treinamento em cada uma das séries temporais no conjunto de dados de treinamento. Cada exemplo de treinamento consiste em um par de janelas de previsão e contexto adjacentes com comprimentos predefinidos fixos. O hiperparâmetro context_length controla até que ponto no passado a rede pode ver, e o parâmetro ForecastHorizon controla até que ponto no futuro as previsões podem ser feitas. Durante o treinamento, o Amazon Forecast ignora elementos no conjunto de dados de treinamento com séries temporais menores que a duração da previsão especificada. O exemplo a seguir mostra cinco amostras, com uma duração de contexto (realçada em verde) de 12 horas e uma duração de previsão (realçada em azul) de 6 horas, extraídas do elemento i. Para resumir, excluímos as séries temporais de recursos xi,1,t e ui,2,t.
Para capturar padrões de sazonalidade, o DeepAR+ também alimenta valores com atraso (período anterior) automaticamente da série temporal de destino. Em nosso exemplo com amostras tomadas em uma frequência por hora, para cada índice de tempo t = T, o modelo expõe os valores zi,t, que ocorreram há aproximadamente um, dois e três dias no passado (destacados em rosa).

Para inferência, o modelo treinado usa como entrada a série temporal de destino, que pode ou não ter sido usada durante o treinamento, e prevê uma distribuição de probabilidades para os próximos valores de ForecastHorizon. Como a DeepAR+ é treinada em todo o conjunto de dados, a previsão considera os padrões aprendidos de séries temporais semelhantes.
Para obter informações sobre a matemática por trás da DeepAR+, consulte o artigo DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
Hiperparâmetros do DeepAR+
A tabela a seguir lista os hiperparâmetros que podem ser usados no algoritmo DeepAR+. Os parâmetros em negrito participam da otimização de hiperparâmetros (HPO).
| Nome do parâmetro | Descrição |
|---|---|
context_length |
O número de pontos no tempo em que o modelo lê antes de fazer a previsão. O valor desse parâmetro deve ser o mesmo que o de
|
epochs |
O número máximo de passagens para examinar os dados de treinamento. O valor ideal depende do tamanho dos dados e da taxa de aprendizagem. Conjuntos de dados menores e taxas de aprendizagem mais baixas exigem mais epochs para alcançar bons resultados.
|
learning_rate |
A taxa de aprendizagem usada no treinamento.
|
learning_rate_decay |
A taxa na qual a taxa de aprendizagem diminui. No máximo, a taxa de aprendizagem é reduzida
|
likelihood |
O modelo gera uma previsão probabilística e pode fornecer quantis da distribuição e retornar amostras. Dependendo de seus dados, escolha uma probabilidade (modelo de ruído) apropriada usada para estimativas de incerteza. Valores válidos
|
max_learning_rate_decays |
O número máximo de reduções da taxa de aprendizagem que devem ocorrer.
|
num_averaged_models |
Na DeepAR+, a trajetória de treinamento pode encontrar vários modelos. Cada modelo pode ter diferentes pontos fortes e fracos de previsão. A DeepAR+ pode calcular a média dos comportamentos do modelo para aproveitar os pontos fortes de todos os modelos.
|
num_cells |
O número de células a ser usado em cada camada oculta da RNN.
|
num_layers |
O número de camadas ocultas na RNN.
|
Ajustar modelos de DeepAR+
Para ajustar modelos do DeepAR+ do Amazon Forecast, siga estas recomendações para otimizar o processo de treinamento e a configuração do hardware.
Melhores práticas para otimização de processos
Para obter os melhores resultados, siga estas recomendações:
-
Exceto ao dividir os conjuntos de dados de treinamento e teste, sempre forneça toda a série temporal para treinamento e teste e ao chamar o modelo para inferência. Independentemente de como você definir
context_length, não divida séries temporais ou forneça apenas parte delas. O modelo usará pontos de dados mais anteriores do quecontext_lengthpara os valores de recursos defasados. -
Para ajustar o modelo, você pode dividir o conjunto de dados em conjuntos de dados de treinamento e teste. Em um cenário de avaliação típico, você deve testar o modelo na mesma série temporal usada no treinamento, mas nos pontos temporais
ForecastHorizonfuturos imediatamente após o último ponto temporal visível durante o treinamento. Para criar conjuntos de dados de treinamento e teste que satisfaçam esses critérios, use o conjunto de dados inteiro (toda a série temporal) como um conjunto de dados de teste e remova os últimos pontosForecastHorizonde cada série temporal para treinamento. Dessa forma, durante o treinamento, o modelo não vê os valores de destino de pontos temporais nos quais ele é avaliado durante o teste. Na fase de teste, os últimos pontosForecastHorizonde cada série temporal no conjunto de dados de teste são retidos, e uma previsão é gerada. A previsão é então comparada com os valores reais dos últimos pontosForecastHorizon. Você pode criar avaliações mais complexas repetindo séries temporais várias vezes no conjunto de dados de teste, mas isolando-as em diferentes pontos finais. Isso produz métricas de precisão médias que são calculadas ao longo de várias previsões de diferentes pontos temporais. -
Evite usar valores muito grandes (> 400) para o
ForecastHorizon, pois isso torna o modelo lento e menos preciso. Para prever mais adiante no futuro, considere a agregação para uma frequência mais alta. Por exemplo, use5minem vez de1min. -
Devido às defasagens, o modelo pode olhar mais para trás no tempo além de
context_length. Portanto, você não precisa definir esse parâmetro como um valor grande. Um bom ponto de partida para esse parâmetro é o mesmo valor que o deForecastHorizon. -
Treine os modelos DeepAR+ com quantas séries temporais estiverem disponíveis. Embora um modelo de DeepAR+ treinado em uma única série temporal possa funcionar bem, métodos de previsão padrão, como ARIMA ou ETS, podem ser mais precisos e são mais personalizados para este caso de uso. A DeepAR+ começa a superar os métodos padrão quando o conjunto de dados contém centenas de séries temporais de recursos. Atualmente, a DeepAR+ requer que o número total de observações disponíveis em todas as séries temporais de treinamento seja, pelo menos, 300.
