As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como as configurações de trabalho funcionam
As configurações de distribuição e anulação são usadas ao implantar um trabalho e as configurações de tempo limite e repetição para execução do trabalho. As seções a seguir mostram mais informações sobre como essas configurações funcionam.
Tópicos
Configurações de implantação, agendamento e anulação de trabalhos
Você pode usar as configurações de distribuição, agendamento e anulação do trabalho para definir quantos dispositivos recebem o documento do trabalho, agendar uma distribuição do trabalho e determinar os critérios para cancelar um trabalho.
Você pode especificar a rapidez com que os destinos são notificados sobre a execução de um trabalho pendente. Você também pode criar uma distribuição em etapas para gerenciar as atualizações, reinicializações e outras operações. Para especificar como seus destinos são notificados, use as taxas de distribuição de trabalhos.
Taxas de distribuição de trabalho
Você pode criar uma configuração de distribuição usando uma taxa de distribuição constante ou uma exponencial. Para especificar o número máximo de destinos de trabalho a serem informados por minuto, use uma taxa de distribuição constante.
AWS IoT os trabalhos podem ser implantados usando taxas de implantação exponenciais à medida que vários critérios e limites são atendidos. Se o número de trabalhos com falha corresponder a um conjunto de critérios que você especificar, você poderá cancelar a distribuição do trabalho. Você define os critérios da taxa de distribuição do trabalho ao criar um trabalho usando o objeto JobExecutionsRolloutConfig. Você também define os critérios de anulação do trabalho na criação do trabalho usando o objeto AbortConfig.
O exemplo a seguir mostra como as taxas de distribuição funcionam. Por exemplo, uma distribuição de trabalho com uma taxa básica de 50 por minuto, fator de incremento de 2 e número de dispositivos notificados e bem-sucedidos, cada um, de 1.000, funcionaria da seguinte forma: o trabalho começará com uma taxa de 50 execuções de trabalho por minuto e continuará nessa taxa até que 1.000 objetos tenham recebido notificações de execução de trabalho ou 1.000 execuções de trabalho bem-sucedidas tenham ocorrido.
A tabela a seguir ilustra como a implantação continuaria nos primeiros quatro incrementos.
|
Taxa de implementação por minuto |
50 |
100 |
200 |
400 |
|
Número de dispositivos notificados ou execuções de trabalho bem-sucedidas para satisfazer um aumento na taxa |
1.000 |
2.000 |
3.000 |
4.000 |
nota
Se você estiver no limite máximo simultâneo de 500 trabalhos (isConcurrent = True), todos os trabalhos ativos permanecerão com o status de IN-PROGRESS e não implementarão nenhuma nova execução de trabalho até que o número de trabalhos simultâneos seja 499 ou menos (isConcurrent = False). Isso se aplica a trabalhos contínuos e de snapshot.
Se isConcurrent = True, o trabalho está implementando atualmente execuções de trabalhos em todos os dispositivos do seu grupo de destino. Se isConcurrent = False, o trabalho concluiu a distribuição de todas as execuções de trabalhos em todos os dispositivos do seu grupo de destino. Ele atualizará seu estado de status quando todos os dispositivos do grupo de destino atingirem um estado terminal ou uma porcentagem limite do grupo de destino, caso você tenha selecionado uma configuração de anulação de trabalho. Os estados de status do nível de trabalho para isConcurrent = True e isConcurrent = False são ambos IN_PROGRESS.
Para obter mais informações sobre limites de trabalho ativos e simultâneos, consulte Limites de trabalho ativos e simultâneos.
Taxas de distribuição de trabalhos para trabalhos contínuos usando grupos dinâmicos de objetos
Quando você usa um trabalho contínuo para implantar operações remotas em sua frota, o AWS IoT Jobs implementa execuções de trabalhos para dispositivos em seu grupo-alvo. Para novos dispositivos adicionados ao grupo dinâmico de objetos, essas execuções de trabalhos continuam sendo distribuídas nesses dispositivos mesmo após a criação do trabalho.
A configuração de distribuição pode controlar as taxas de distribuição somente para dispositivos adicionados ao grupo até a criação do trabalho. Depois que um trabalho é criado, para qualquer novo dispositivo, as execuções do trabalho são criadas quase em tempo real assim que os dispositivos se juntam ao grupo de destino.
Você pode agendar um trabalho contínuo ou de snapshot com até um ano de antecedência usando um horário de início, horário de término e comportamento de término predeterminados para o que acontecerá com a execução de cada trabalho ao atingir o horário de término. Além disso, você pode criar uma janela de manutenção recorrente opcional com frequência, horário de início e duração flexíveis para que trabalhos contínuos possam distribuir um documento de trabalho em todos os dispositivos do grupo de destino.
Configurações de agendamento de trabalho
Horário de início
O horário de início de um trabalho agendado é a data e a hora futuras em que o trabalho iniciará a distribuição do documento de trabalho em todos os dispositivos do grupo de destino. O horário de início de um trabalho agendado se aplica a trabalhos contínuos e trabalhos de snapshot. Quando um trabalho agendado é criado inicialmente, ele mantém um estado de status de SCHEDULED. Ao chegar ao startTime que você selecionou, ele é atualizado para IN_PROGRESS e inicia a distribuição do documento de trabalho. O startTime deve ser menor ou igual a um ano a partir da data e hora iniciais em que você criou o trabalho agendado.
Para obter mais informações sobre a sintaxe para startTime usar um comando de API ou o AWS CLI, consulte Timestamp.
Para um trabalho com a configuração de agendamento opcional que ocorre durante uma janela de manutenção recorrente em um local que observa o horário de verão, o horário mudará em uma hora ao mudar do horário de verão para o horário padrão e do horário padrão para o horário de verão.
nota
O fuso horário exibido no AWS Management Console é o fuso horário atual do seu sistema. No entanto, esses fusos horários serão convertidos em UTC no sistema.
Horário de término
O horário de término de um trabalho agendado é a data e a hora futuras em que o trabalho interromperá a distribuição do documento de trabalho em qualquer dispositivo restante no grupo de destino. A hora de término de um trabalho agendado se aplica a trabalhos contínuos e trabalhos de snapshot. Depois que um trabalho agendado chega ao endTime selecionado e todas as execuções do trabalho atingem um estado terminal, ele atualiza seu estado de status de IN_PROGRESS para COMPLETED. O endTime deve ser menor ou igual a dois anos a partir da data e hora iniciais em que você criou o trabalho agendado. A duração mínima entre o startTime e o endTime é de 30 minutos. As tentativas de repetição da execução do trabalho ocorrerão até que o trabalho alcance o endTime; então, o endBehavior ditará como proceder.
Para obter mais informações sobre a sintaxe para endTime usar um comando de API ou o AWS CLI, consulte Timestamp.
Para um trabalho com a configuração de agendamento opcional que ocorre durante uma janela de manutenção recorrente em um local que observa o horário de verão, o horário mudará em uma hora ao mudar do horário de verão para o horário padrão e do horário padrão para o horário de verão.
nota
O fuso horário exibido no AWS Management Console é o fuso horário atual do seu sistema. No entanto, esses fusos horários serão convertidos em UTC no sistema.
Comportamento final
O comportamento final de um trabalho agendado determina o que acontece com o trabalho e com todas as execuções de trabalhos inacabados quando o trabalho chega ao endTime selecionado.
A seguir, são listados os comportamentos finais que você pode selecionar ao criar o trabalho ou o modelo de trabalho:
-
STOP_ROLLOUT-
STOP_ROLLOUTinterrompe a distribuição do documento de trabalho em todos os dispositivos restantes no grupo de destino do trabalho. Além disso, todas as execuções de trabalhosQUEUEDeIN_PROGRESScontinuarão até atingirem um estado terminal. Esse é o comportamento final padrão, a menos que você selecioneCANCELouFORCE_CANCEL.
-
-
CANCEL-
CANCELinterrompe a distribuição do documento de trabalho em todos os dispositivos restantes no grupo de destino do trabalho. Além disso, todas as execuções de trabalhosQUEUEDserão canceladas, enquanto todas as execuções de trabalhoIN_PROGRESScontinuarão até atingirem um estado terminal.
-
-
FORCE_CANCEL-
FORCE_CANCELinterrompe a distribuição do documento de trabalho em todos os dispositivos restantes no grupo de destino do trabalho. Além disso, todas as execuções de trabalhosQUEUEDeIN_PROGRESSserão canceladas.
-
nota
Para selecionar umendbehavior, você deve selecionar um endtime
Duração máxima
A duração máxima de um trabalho agendado deve ser menor ou igual a dois anos, independentemente do startTime e endTime.
A tabela a seguir lista cenários comuns de duração de um trabalho agendado:
| Número de exemplo de trabalho agendado | startTime | endTime | Duração máxima |
|---|---|---|---|
|
1 |
Imediatamente após a criação inicial do trabalho. |
Um ano após a criação inicial do trabalho. |
Um ano |
|
2 |
Um mês após a criação inicial do trabalho. |
13 meses após a criação inicial do trabalho. |
Um ano |
|
3 |
Um ano após a criação inicial do trabalho. |
Dois anos após a criação inicial do trabalho. |
Um ano |
|
4 |
Imediatamente após a criação inicial do trabalho. |
Dois anos após a criação inicial do trabalho. |
Dois anos |
Janela de manutenção recorrente
A janela de manutenção é uma configuração opcional dentro da configuração de agendamento das AWS Management Console e SchedulingConfig dentro das CreateJobTemplate APIs CreateJob e. Você pode configurar uma janela de manutenção recorrente com uma hora de início, duração e frequência predeterminadas (diária, semanal ou mensal) em que a janela de manutenção ocorre. As janelas de manutenção só se aplicam a trabalhos contínuos. A duração máxima de uma janela de manutenção recorrente é de 23 horas e 50 minutos.
O diagrama a seguir ilustra os estados do status de trabalho para vários cenários de trabalho programados com uma janela de manutenção opcional:
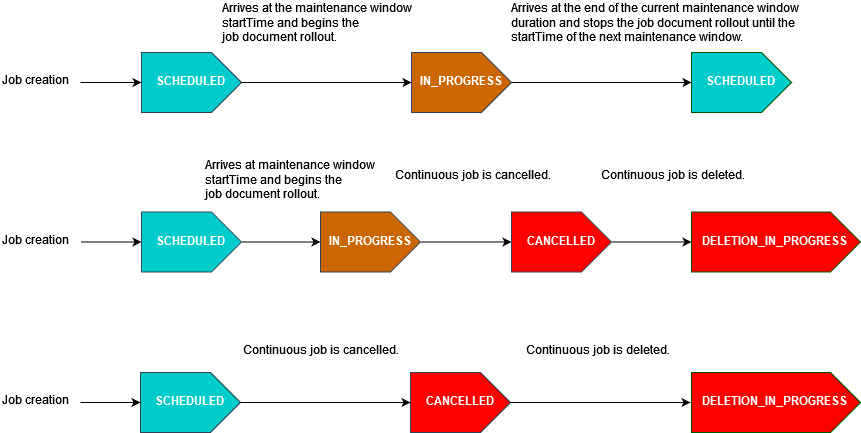
Para obter mais informações sobre o status de trabalho, consulte Trabalhos e estados de execução de trabalhos.
nota
Se um trabalho chegar ao endTime durante uma janela de manutenção, ele será atualizado de IN_PROGRESS para COMPLETED. Além disso, todas as execuções de trabalho restantes seguirão endBehavior do trabalho.
Expressão cron
Para trabalhos agendados que distribuem o documento de trabalho durante uma janela de manutenção com uma frequência personalizada, a frequência personalizada é inserida usando uma expressão cron. Uma expressão cron têm seis campos obrigatórios, que são separados por um espaço em branco.
Sintaxe
cron(fields)
| Campo | Valores | Curingas |
|---|---|---|
|
minutos |
0-59 |
, - * / |
|
Horas |
0-23 |
, - * / |
|
D ay-of-month |
1-31 |
, - * ? / L W |
|
Mês |
1-12 ou JAN-DEZ |
, - * / |
|
D ay-of-week |
1-7 ou DOM-SÁB |
, - * ? L # |
|
Ano |
1970-2199 |
, - * / |
Curingas
-
A , (vírgula) curinga inclui valores adicionais. No campo Mês, JAN, FEV, MAR incluiria janeiro, fevereiro e março.
-
O - (traço) curinga especifica intervalos. No campo Dia, 1-15 incluiria dias 1 a 15 do mês especificado.
-
O * (asterisco) curinga inclui todos os valores no campo. No campo Horas, * incluiria cada hora. Você não pode usar * nos ay-of-week campos D ay-of-month e D. Se você usá-lo em um deles, utilize ? no outro.
-
A / (barra) curinga especifica incrementos. No campo Minutos, você pode inserir 1/10 para especificar cada décimo minuto a partir do primeiro minuto da hora (por exemplo, o 11º, 21º e 31º minuto, etc.).
-
O curinga ? (interrogação) especifica um ou outro. No ay-of-month campo D, você poderia inserir 7 e, se não se importasse em que dia da semana era o 7º, você poderia inserir? no ay-of-week campo D.
-
O curinga L nos ay-of-week campos D ay-of-month ou D especifica o último dia do mês ou da semana.
-
O
Wcaractere curinga no ay-of-month campo D especifica um dia da semana. No ay-of-month campo D,3Wespecifica o dia da semana mais próximo do terceiro dia do mês. -
O caractere curinga # no ay-of-week campo D especifica uma determinada instância do dia da semana especificado em um mês. Por exemplo, 3#2 seria a segunda terça-feira do mês: o 3 refere-se a terça-feira, porque é o terceiro dia de cada semana, e o 2 refere-se ao segundo dia desse tipo dentro do mês.
nota
Se você usar um caractere '#', poderá definir somente uma expressão no day-of-week campo. Por exemplo, o valor
"3#1,6#3"não é válido porque é interpretado como duas expressões.
Restrições
-
Você não pode especificar os ay-of-week campos D ay-of-month e D na mesma expressão cron. Se você especificar um valor (ou um *) em um dos campos, deverá usar um ? no outro.
Exemplos
Consulte os exemplos de strings cron a seguir ao usar uma expressão cron para o startTime de uma janela de manutenção recorrente.
| Minutos | Horas | Dia do mês | Mês | Dia da semana | Ano | Significado |
|---|---|---|---|---|---|---|
| 0 | 10 | * | * | ? | * |
Executada às 10h (UTC) todos os dias |
| 15 | 12 | * | * | ? | * |
Executada às 12h15 (UTC) todos os dias |
| 0 | 18 | ? | * | SEG-SEX | * |
Executada às 18h (UTC) de segunda a sexta |
| 0 | 8 | 1 | * | ? | * |
Executada às 8h (UTC) todo o primeiro dia do mês |
Lógica final da duração da janela de manutenção recorrente
Quando a distribuição de um trabalho durante uma janela de manutenção atinge o final da duração da ocorrência da janela de manutenção atual, as seguintes ações ocorrerão:
-
O trabalho encerrará todas as distribuições do documento de trabalho em todos os dispositivos restantes em seu grupo de destino. A operação será retomada no
startTimeda próxima janela de manutenção. -
Todas as execuções de trabalhos com um status de
QUEUEDpermanecerãoQUEUEDaté ostartTimeda próxima ocorrência da janela de manutenção. Na próxima janela, eles podem alternar paraIN_PROGRESSquando o dispositivo estiver pronto para começar a executar as ações especificadas no documento do trabalho. -
Todas as execuções de trabalhos com um status de
IN_PROGRESScontinuarão realizando as ações especificadas no documento do trabalho até atingirem um estado terminal. Qualquer nova tentativa, conforme especificado emJobExecutionsRetryConfig, ocorrerá nostartTimeda próxima janela de manutenção.
Use essa configuração para criar um critério para cancelar um trabalho quando uma porcentagem limite de dispositivos atender a esses critérios. Por exemplo, você pode usar essa configuração para cancelar um trabalho nos seguintes casos:
-
Quando uma porcentagem mínima de dispositivos não recebe as notificações de execução do trabalho, como quando seu dispositivo é incompatível com uma atualização via ondas de rádio. Nesse caso, seu dispositivo pode relatar um status
REJECTED. -
Quando uma porcentagem mínima de dispositivos relata falhas na execução de trabalhos, como quando seu dispositivo encontra uma desconexão ao tentar baixar o documento de trabalho de um URL do Amazon S3. Nesses casos, seu dispositivo deve estar programado para relatar o status
FAILUREao AWS IoT. -
Quando um status
TIMED_OUTé relatado porque a execução do trabalho expira para uma porcentagem limite de dispositivos após o início das execuções do trabalho. -
Quando há várias falhas de nova tentativa. Quando você adiciona uma configuração de nova tentativa, cada nova tentativa pode gerar cobranças adicionais para sua Conta da AWS. Nesses casos, o cancelamento do trabalho pode cancelar execuções de trabalhos em fila e evitar novas tentativas para essas execuções. Para obter mais informações sobre a configuração de nova tentativa e como usá-la com a configuração de anulação, consulte Configurações de novas tentativas e de tempo limite de execuções de trabalhos.
Você pode configurar uma condição de cancelamento do trabalho usando o AWS IoT console ou a API AWS IoT Jobs.
Configurações de novas tentativas e de tempo limite de execuções de trabalhos
Use a configuração de tempo limite de execução do trabalho para enviar a você Notificações de trabalhos quando a execução de um trabalho estiver em andamento por mais tempo do que a duração definida. Use a configuração de repetição da execução do trabalho para repetir a execução quando o trabalho falhar ou atingir o tempo limite.
O tempo limite do trabalho permite que você receba uma notificação sempre que uma execução de trabalho ficar paralisada no estado IN_PROGRESS por um período inesperadamente longo. Quando o trabalho estiver IN_PROGRESS, você poderá monitorar o progresso da execução do trabalho.
Temporizadores para tempos limite de trabalhos
Há dois tipos de temporizadores: em andamento e de etapa.
Temporizadores em andamento
Ao criar um trabalho ou um modelo de trabalho, você pode especificar um valor para o temporizador em andamento que esteja entre 1 minuto e 7 dias. Você pode atualizar o valor desse temporizador até o início da execução do trabalho. Depois que o temporizador é iniciado, ele não pode ser atualizado e o valor do temporizador se aplica a todas as execuções do trabalho. Sempre que a execução de uma tarefa permanece no IN_PROGRESS status por mais tempo do que esse intervalo, a execução da tarefa falha e muda para o TIMED_OUT status do terminal. AWS IoT também publica uma notificação MQTT.
Temporizador de etapas
Você também pode definir um temporizador de etapa que se aplique somente à execução do trabalho que você deseja atualizar. Esse temporizador não tem efeito sobre o temporizador em andamento. Cada vez que você atualizar uma execução de trabalho, é possível definir um novo valor para o temporizador de etapa. Você também pode criar um novo temporizador de etapa ao iniciar a próxima execução de trabalho pendente de um objeto. Se a execução de trabalho permanecer com o status IN_PROGRESS por mais tempo que o intervalo do temporizador de etapa, ela falhará e alternará para o status TIMED_OUT terminal.
nota
Você pode definir o cronômetro em andamento usando o AWS IoT console ou a API AWS IoT Jobs. Para especificar o temporizador da etapa, use a API.
Como funcionam os temporizadores para o tempo limite de trabalho
A seguir, uma ilustração de como os tempos limite em andamento e de etapa interagem um com o outro em um período de tempo limite de 20 minutos.
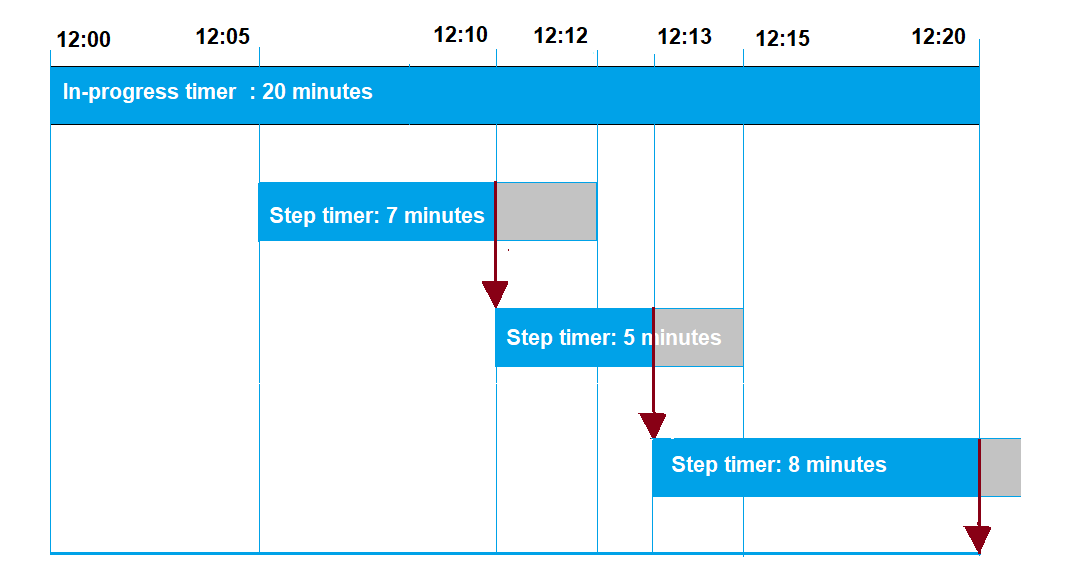
A seguir, são mostradas as diferentes etapas:
-
12:00
Um novo trabalho é criado e um temporizador em andamento de vinte minutos é iniciado ao criar um trabalho. O temporizador em andamento começa a ser executado e a execução do trabalho muda para o status
IN_PROGRESS. -
12h05
Um novo temporizador de etapa com um valor de 7 minutos é criado. A execução do trabalho agora expirará às 12h12.
-
12h10
Um novo temporizador de etapa com um valor de 5 minutos é criado. Quando um novo temporizador de etapa é criado, o temporizador de etapa anterior é descartado e a execução do trabalho agora atingirá o tempo limite às 12h15.
-
12h13
Um novo temporizador de etapa com um valor de 9 minutos é criado. O temporizador de etapa anterior é descartado e a execução do trabalho agora atingirá o tempo limite às 12h20, pois o temporizador em andamento expira às 12h20. O temporizador de etapa não pode exceder o limite absoluto do temporizador em andamento.
Você pode usar a configuração de repetição para repetir a execução do trabalho quando um determinado conjunto de critérios for atendido. Uma nova tentativa pode ser feita quando um trabalho atinge o tempo limite ou quando o dispositivo falha. Para repetir a execução devido a uma falha de tempo limite, você deve habilitar a configuração de tempo limite.
Como usar a configuração de repetição
Siga as etapas a seguir para repetir essa configuração:
-
Determine se deve usar a configuração de repetição para
FAILED,TIMED_OUTou ambos os critérios de falha. Para oTIMED_OUT -
Para o status
FAILED, verifique se a falha na execução do trabalho pode ser repetida. Se for possível repetir, programe seu dispositivo para relatar um statusFAILUREao AWS IoT. A seção a seguir descreve mais sobre falhas que podem ser repetidas e não repetidas. -
Especifique o número de novas tentativas a serem usadas para cada tipo de falha usando as informações anteriores. Para um único dispositivo, você pode especificar até dez novas tentativas para os dois tipos de falha combinados. As tentativas de repetição são interrompidas automaticamente quando uma execução é bem-sucedida ou quando atinge o número especificado de tentativas.
-
Adicione uma configuração de anulação para cancelar o trabalho se houver repetidas falhas de repetição para evitar cobranças adicionais com um grande número de tentativas de repetição.
nota
Quando um trabalho chega ao final de uma ocorrência recorrente da janela de manutenção, todas as execuções do trabalho IN_PROGRESS continuarão executando as ações identificadas no documento do trabalho até chegarem ao estado terminal. Se a execução de um trabalho atingir um estado terminal FAILED ou TIMED_OUT fora de uma janela de manutenção, uma nova tentativa ocorrerá na próxima janela se as tentativas não forem esgotadas. No próximo startTime da ocorrência da janela de manutenção, uma nova execução de trabalho será criada e entrará em um estado de status QUEUED até que o dispositivo esteja pronto para começar.
Configuração de repetição e anulação
Cada tentativa de nova tentativa incorre em cobranças adicionais para você. Conta da AWS Para evitar cobranças adicionais devido a falhas repetidas de tentativas, recomendamos adicionar uma configuração de anulação. Para obter mais informações sobre a definição de preço, consulte Preços do AWS IoT Device Management
Você pode encontrar várias falhas de repetição quando uma porcentagem alta de seus dispositivos atinge o tempo limite ou relata uma falha. Nesse caso, você pode usar a configuração de anulação para cancelar o trabalho e evitar qualquer execução de trabalho na fila ou novas tentativas.
nota
Quando os critérios de anulação são atendidos para cancelar a execução de um trabalho, somente as execuções de trabalhos QUEUED são canceladas. Nenhuma tentativa de repetição do dispositivo na fila será feita. No entanto, as execuções de trabalhos atuais que tenham um status IN_PROGRESS não serão canceladas.
Antes de repetir uma execução de trabalho com falha, também recomendamos que você verifique se a falha na execução do trabalho pode ser repetida, conforme descrito na seção a seguir.
Tipo de FAILED repetir em caso de falha
Para tentar repetir no tipo de falha FAILED, seus dispositivos devem ser programados para relatar o status FAILURE de uma falha na execução de um trabalho no AWS IoT. Defina a configuração de repetição com os critérios para repetir as execuções de trabalhos FAILED e especifique o número de novas tentativas a serem executadas. Quando o AWS IoT Jobs detectar o FAILURE status, ele tentará automaticamente repetir a execução do trabalho no dispositivo. As repetições continuam até que a execução do trabalho seja bem-sucedida ou quando atingir o número máximo de tentativas de repetição.
Você pode acompanhar cada tentativa de repetição e o trabalho que está sendo executado nesses dispositivos. Ao rastrear o status da execução, após o número especificado de tentativas, você pode usar seu dispositivo para relatar falhas e iniciar outra tentativa.
Falhas que podem ser repetidas e não repetidas
Sua falha na execução do trabalho pode ser repetida ou não. Cada nova tentativa de repetição pode gerar cobranças em sua Conta da AWS. Para evitar cobranças adicionais decorrentes de várias tentativas, primeiro considere verificar se a falha na execução do trabalho pode ser repetida. Um exemplo de falha que pode ser repetida inclui um erro de conexão que seu dispositivo encontra ao tentar baixar o documento de trabalho de um URL do Amazon S3. Se a falha na execução do trabalho puder ser repetida, programe seu dispositivo para relatar um status FAILURE caso a execução do trabalho falhe. Em seguida, defina a configuração de nova tentativa para repetir as execuções FAILED.
Se a execução não puder ser repetida, para evitar novas tentativas e possivelmente incorrer em cobranças adicionais em sua conta, recomendamos que você programe o dispositivo para relatar um status REJECTED ao AWS IoT. Exemplos de falhas que não podem ser repetidas incluem quando seu dispositivo é incompatível com o recebimento de uma atualização de trabalho ou quando ocorre um erro de memória ao executar um trabalho. Nesses casos, o AWS IoT Jobs não repetirá a execução do trabalho porque ele tentará novamente a execução do trabalho somente quando detectar um FAILED status ou. TIMED_OUT
Depois de determinar que uma falha na execução do trabalho pode ser repetida, se uma tentativa de repetição ainda falhar, considere verificar os logs do dispositivo.
nota
Quando um trabalho com a configuração de agendamento opcional chegar ao seu endTime, o endBehavior selecionado interromperá a distribuição do documento de trabalho em todos os dispositivos restantes no grupo de destino e ditará como proceder com as execuções restantes do trabalho. As tentativas são repetidas se selecionadas por meio da configuração de repetição.
Tipo de TIMEOUT repetir em caso de falha
Se você ativar o tempo limite ao criar um trabalho, o AWS IoT Jobs tentará repetir a execução do trabalho para o dispositivo quando o status mudar de IN_PROGRESS para. TIMED_OUT Essa alteração de status pode ocorrer quando o temporizador em andamento expira ou quando um temporizador de etapa que você especifica está IN_PROGRESS e, em seguida, expira. As repetições continuam até que a execução do trabalho seja bem-sucedida ou quando atingir o número máximo de tentativas de repetição para esse tipo de falha.
Trabalhos contínuos e atualizações de membros de grupos
Para trabalhos contínuos com status de trabalho IN_PROGRESS, o número de tentativas de repetição é redefinido para zero quando há atualizações na associação ao grupo de um objeto. Por exemplo, considere que você especificou cinco tentativas de repetição e três tentativas já foram realizadas. Se um objeto agora for removida do grupo de objetos e depois voltar ao grupo, como acontece com grupos de objetos dinâmicos, o número de tentativas de repetição é redefinido para zero. Agora você pode realizar cinco tentativas de repetição para seu grupo de objetos, em vez das duas tentativas restantes. Além disso, quando um objeto é removida do grupo de objetos, outras tentativas são canceladas.
