Não estamos mais atualizando o serviço Amazon Machine Learning nem aceitando novos usuários para ele. Essa documentação está disponível para usuários existentes, mas não estamos mais atualizando-a. Para obter mais informações, consulte O que é o Amazon Machine Learning.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Insights de dados
O Amazon ML calcula estatísticas descritivas nos dados de entrada que podem ser usadas para entender seus dados.
Estatísticas descritivas
O Amazon ML calcula as seguintes estatísticas descritivas para diferentes tipos de atributo:
Numeric:
-
Histogramas de distribuição
-
Número de valores inválidos
-
Valores mínimo, mediano, médio e máximo
Binários e categóricos:
-
Contagem (de valores distintos por categoria)
-
Histograma de distribuição de valores
-
Valores mais frequentes
-
Contagens de valores exclusivos
-
Porcentagem de valor real (somente binário)
-
Palavras mais proeminentes
-
Palavras mais frequentes
Texto:
-
Nome do atributo
-
Correlação com o destino (se um destino estiver definido)
-
Total de palavras
-
Palavras exclusivas
-
Intervalo de número de palavras em uma linha
-
Intervalo de comprimentos de palavra
-
Palavras mais proeminentes
Acessar insights de dados no console do Amazon ML
No console do Amazon ML, você pode escolher o nome ou o ID de qualquer fonte de dados para visualizar a página Insights de dados correspondente. Essa página fornece métricas e visualizações que permitem conhecer os dados de entrada associados à fonte de dados, incluindo as seguintes informações:
-
Resumo dos dados
-
Distribuições de destino
-
Valores ausentes
-
Valores inválidos
-
Estatísticas resumidas de variáveis por tipo de dados
-
Distribuições de variáveis por tipo de dados
As seções a seguir descrevem as métricas e visualizações em mais detalhes.
Resumo dos dados
O relatório de resumo de dados de uma fonte de dados exibe informações resumidas, incluindo o ID da fonte de dados, o nome, onde ele foi concluído, o status atual, o atributo de destino, as informações dos dados de entrada (local bucket do S3, formato de dados, número de registros processados e número de registros inválidos encontrados durante o processamento), bem como o número de variáveis por tipo de dados.
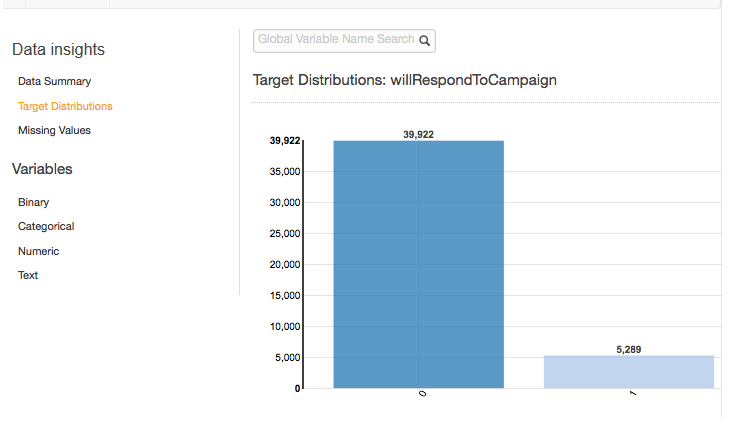
Distribuições de destino
O relatório de distribuições de destino mostra a distribuição do atributo de destino da fonte de dados. No exemplo a seguir, há 39.922 observações em que o atributo will RespondToCampaign target é igual a 0. Esse é o número de clientes que não responderam à campanha de e-mail. Há 5.289 observações em que will é igual a RespondToCampaign 1. Esse é o número de clientes que responderam à campanha de e-mail.
Valores ausentes
O relatório de valores ausentes lista os atributos nos dados de entrada para os quais há valores ausentes. Somente atributos com tipos de dados numéricos podem ter valores ausentes. Como os valores podem afetar a qualidade do treinamento de um modelo de ML, recomendamos que os valores ausentes sejam fornecidos, se possível.
Durante o treinamento do modelo de ML, se o atributo de destino está ausente, o Amazon ML rejeita o registro correspondente. Se o atributo de destino está presente no registro, mas um valor para outro atributo numérico está ausente, o Amazon ML ignora o valor não encontrado. Nesse caso, o Amazon ML cria um atributo substituto e o define como 1 para indicar que ele está ausente. Isso permite que o Amazon ML aprenda padrões a partir da ocorrência de valores ausentes.
Valores inválidos
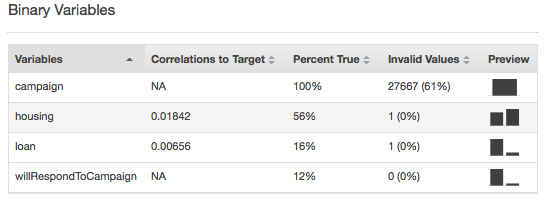
Valores inválidos só podem ocorrer com os tipos de dados binários e numéricos. Para encontrar valores inválidos, visualize as estatísticas resumidas de variáveis nos relatórios de tipo de dados. Nos exemplos a seguir, há um valor inválido no atributo numérico de duração e dois valores inválidos no tipo de dados binários (um no atributo de moradia e outro no atributo de empréstimo).

Variable-Target Correlação
Após a criação de uma fonte de dados, o Amazon ML pode avaliar a fonte de dados e identificar a correlação, ou impacto, entre as variáveis e o destino. Por exemplo, o preço de um produto pode ter um impacto significativo em seu sucesso de vendas, enquanto as dimensões do produto podem ter pouco poder preditivo.
Em geral, as melhores práticas aconselham incluir em seus dados de treinamento o máximo de variáveis possível. No entanto, o ruído introduzido pela inclusão de muitas variáveis com pouco poder preditivo pode afetar negativamente a qualidade e a precisão do modelo de ML.
Você pode melhorar o desempenho das previsões do seu modelo removendo variáveis que têm pouco impacto quando você treinar o modelo. Você pode definir quais variáveis ficam disponíveis para o processo de machine learning em uma receita, que é um mecanismo de transformação do Amazon ML. Para saber mais sobre receitas, consulte Transformação de dados para Machine Learning.
Estatísticas resumidas de atributos por tipo de dados
No relatório de insights de dados, você pode visualizar estatísticas resumidas de atributos por estes tipos de dados:
-
Binário
-
Categóricos
-
Numérico
-
Texto
As estatísticas resumidas para o tipo de dados binários mostram todos os atributos binários. A coluna Correlations to target (Correlações com o destino) mostra as informações compartilhadas entre a coluna de destino e a coluna de atributos. A coluna Percent true (Porcentagem verdadeira) mostra a porcentagem de observações que têm o valor 1. A coluna Invalid values (Valores inválidos) mostra o número de valores inválidos, bem como a porcentagem de valores inválidos para cada atributo. A coluna Preview (Visualizar) fornece um link para uma distribuição gráfica de cada atributo.
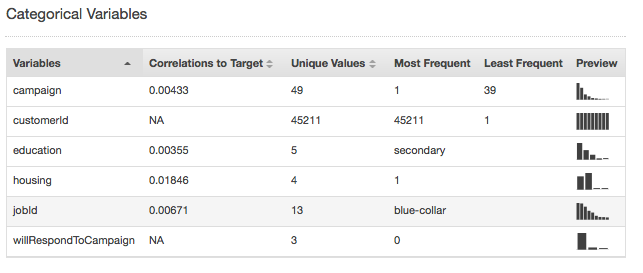
As estatísticas resumidas para o tipo de dados Categórico mostram todos os atributos categóricos com o número de valores exclusivos, o valor mais frequente e o valor menos frequente. A coluna Preview (Visualizar) fornece um link para uma distribuição gráfica de cada atributo.
As estatísticas resumidas para o tipo de dados Numérico mostram todos os atributos numéricos com o número de valores ausentes, valores inválidos, intervalo de valores, média e mediana. A coluna Preview (Visualizar) fornece um link para uma distribuição gráfica de cada atributo.
As estatísticas resumidas do tipo de dados Texto mostram todos os atributos de texto, o número total de palavras no atributo, o número de palavras exclusivas no atributo, a variedade de palavras em um atributo, o intervalo de comprimentos de palavras e as palavras mais proeminentes. A coluna Preview (Visualizar) fornece um link para uma distribuição gráfica de cada atributo.
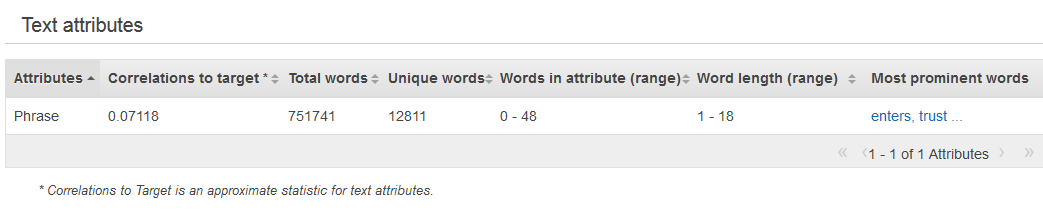
O exemplo a seguir mostra as estatísticas do tipo de dados Texto para uma variável de texto chamada de revisão, com quatro registros.
1. The fox jumped over the fence. 2. This movie is intriguing. 3. 4. Fascinating movie.
As colunas do exemplo mostram as seguintes informações.
-
A coluna Attributes (Atributos) mostra o nome da variável. Neste exemplo, esta coluna mostraria "revisão".
-
A coluna Correlations to target (Correlações com o destino) estará presente somente se um destino for especificado. A correlação mede a quantidade de informações que o atributo fornece sobre o destino. Quanto maior a correlação, mais o atributo informa sobre o destino. A correlação é medida em termos de informações em comum entre uma representação simplificada do atributo de texto e o destino.
-
A coluna Total words (Total de palavras) mostra o número de palavras geradas pela análise léxica de cada registro, delimitando as palavras com espaços em branco. Neste exemplo, esta coluna mostraria "12".
-
A coluna Unique words (Palavras exclusivas) mostra o número de palavras exclusivas de um atributo. Neste exemplo, esta coluna mostraria "10".
-
A coluna Words in attribute (range) (Palavras no atributo (intervalo)) mostra o número de palavras em uma única linha no atributo. Neste exemplo, esta coluna mostraria "0-6".
-
A coluna Word length (range) (Tamanho da palavra (intervalo)) mostra o intervalo do número de caracteres nas palavras. Neste exemplo, esta coluna mostraria "2-11".
-
A coluna Most prominent words (Palavras mais proeminentes) mostra uma lista classificada de palavras que aparecem no atributo. Se houver um atributo de destino, palavras serão classificadas de acordo com sua correlação com o destino, o que significa que as palavras com a mais alta correlação serão listadas primeiro. Se nenhum destino estiver presente nos dados, as palavras serão classificadas de acordo com sua entropia.
Noções básicas sobre distribuição de atributos categóricos e binários
Clicando no link Preview (Visualizar) associado a um atributo categórico ou binário, você pode visualizar a distribuição do atributo bem como os dados de exemplo do arquivo de entrada para cada valor categórico do atributo.
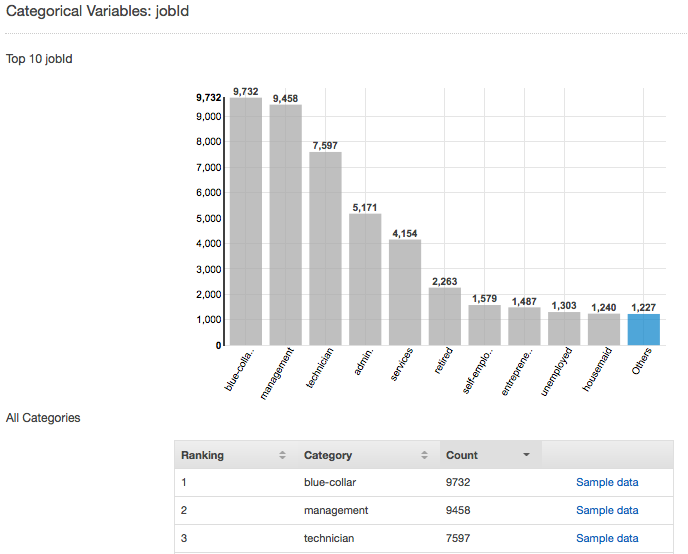
Por exemplo, a captura de tela a seguir mostra a distribuição do atributo categórico jobId. A distribuição exibe os 10 principais valores categóricos, com todos os outros valores agrupados como "outros". Ela classifica cada um dos 10 principais valores categórico com o número de observações no arquivo de entrada que contêm esse valor, bem como um link para visualizar observações de exemplo do arquivo de dados de entrada.
Noções básicas sobre distribuição de atributos numéricos
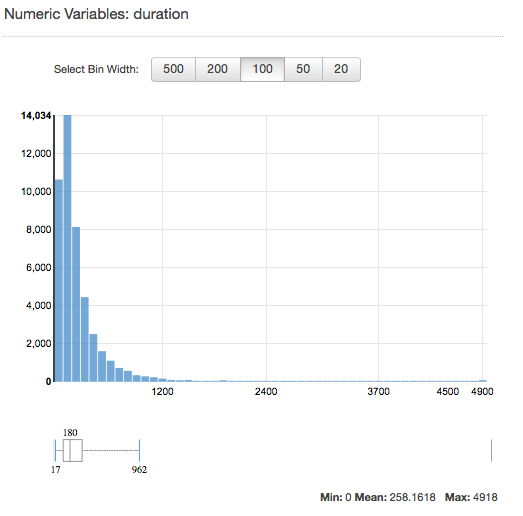
Para visualizar a distribuição de um atributo numérico, clique no link Preview (Visualizar) do atributo. Ao visualizar a distribuição de um atributo numérico, você pode escolher tamanhos de compartimento de 500, 200, 100, 50 ou 20. Quanto maior o tamanho do compartimento, menor será o número de gráficos de barras exibidos. Além disso, a resolução da distribuição será inferior para grandes tamanhos de compartimento. Por outro lado, a definição do tamanho do bucket como 20 aumenta a resolução da distribuição exibida.
Os valores mínimo, médio e máximo também são exibidos, como mostra a captura de tela a seguir.
Noções básicas sobre distribuição de atributos de texto
Para visualizar a distribuição de um atributo de texto, clique no link Preview (Visualizar) do atributo. Ao visualizar a distribuição de um atributo de texto, você verá as seguintes informações.
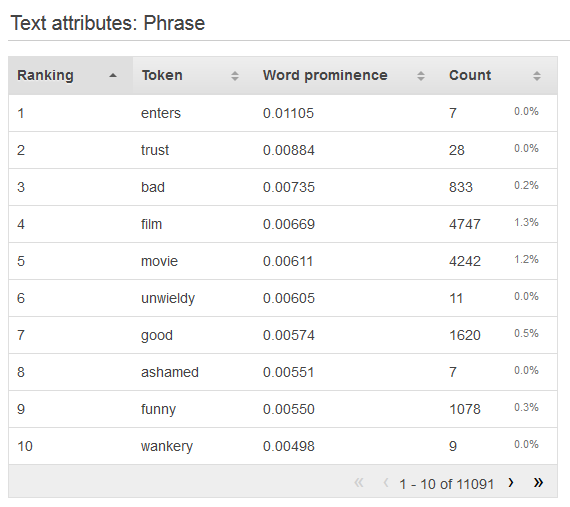
- Classificação
-
Os tokens de texto são classificados de acordo com a quantidade de informações que transmitem, do mais informativo para o menos informativo.
- Token
-
Token mostra a palavra do texto de entrada que é o assunto da linha de estatísticas.
- Proeminência da palavra
-
Se houver um atributo de destino, as palavras serão classificadas de acordo com sua correlação com o destino, de modo que as palavras com a mais alta correlação serão listadas primeiro. Se nenhum destino estiver presente nos dados, as palavras serão classificadas de acordo com sua entropia, ou seja, a quantidade de informações que podem comunicar.
- Contagem numérica
-
A contagem numérica mostra o número de registros de entrada nos quais o token apareceu.
- Contagem percentual
-
A contagem percentual mostra a porcentagem de linhas de dados de entrada nas quais o token apareceu.
