Não estamos mais atualizando o serviço Amazon Machine Learning nem aceitando novos usuários para ele. Essa documentação está disponível para usuários existentes, mas não estamos mais atualizando-a. Para obter mais informações, consulte O que é o Amazon Machine Learning.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Dividir dados
O objetivo fundamental de um modelo de ML é fazer previsões precisas com base em instâncias de dados futuras além daquelas usadas para treinar modelos. Antes de usar um modelo de ML para fazer previsões, precisamos avaliar o desempenho das previsões do modelo. Para estimar a qualidade das previsões de um modelo de ML com dados não analisados, podemos reservar, ou dividir, uma parte dos dados para os quais já sabemos a resposta como um substituto para dados futuros e avaliar se o modelo de ML prevê respostas corretas para os dados. Você divide a fonte de dados em uma parte para a fonte de dados de treinamento e outra para a fonte de dados de avaliação.
O Amazon ML oferece três opções para dividir os dados:
-
Pre-split os dados - Você pode dividir os dados em dois locais de entrada de dados, antes de carregá-los no Amazon Simple Storage Service (Amazon S3) e criar duas fontes de dados separadas com eles.
-
Divisão sequencial do Amazon ML: você pode instruir o Amazon ML a dividir os dados sequencialmente quando criar as fontes de dados de treinamento e de avaliação.
-
Divisão aleatória do Amazon ML: você pode instruir o Amazon ML a dividir os dados usando um método aleatório propagado ao criar as fontes de dados de treinamento e de avaliação.
Pre-splitting Seus dados
Se você deseja ter controle explícito sobre os dados das fontes de dados de avaliação e treinamento, divida-os em locais de dados separados e crie fontes de dados separadas para os locais de entrada e de avaliação.
Dividir dados sequencialmente
Uma maneira simples de dividir dados de entrada para treinamento e avaliação é selecionar subconjuntos não sobrepostos dos dados, preservando a ordem dos registros de dados. Essa abordagem é útil se você deseja avaliar os modelos de ML com dados de uma determinada data ou dentro de um determinado período. Por exemplo, digamos que você tem dados sobre o envolvimento de clientes referentes aos últimos cinco meses e deseja usar esses dados históricos para prever o envolvimento de clientes no próximo mês. O uso do início do período para treinamento e dos dados do final do período para avaliação pode produzir uma estimativa mais exata da qualidade do modelo do que o uso de dados de registros extraídos de todo o período.
A figura a seguir mostra exemplos de quando você deve usar uma estratégia de divisão sequencial ou uma estratégia aleatória.
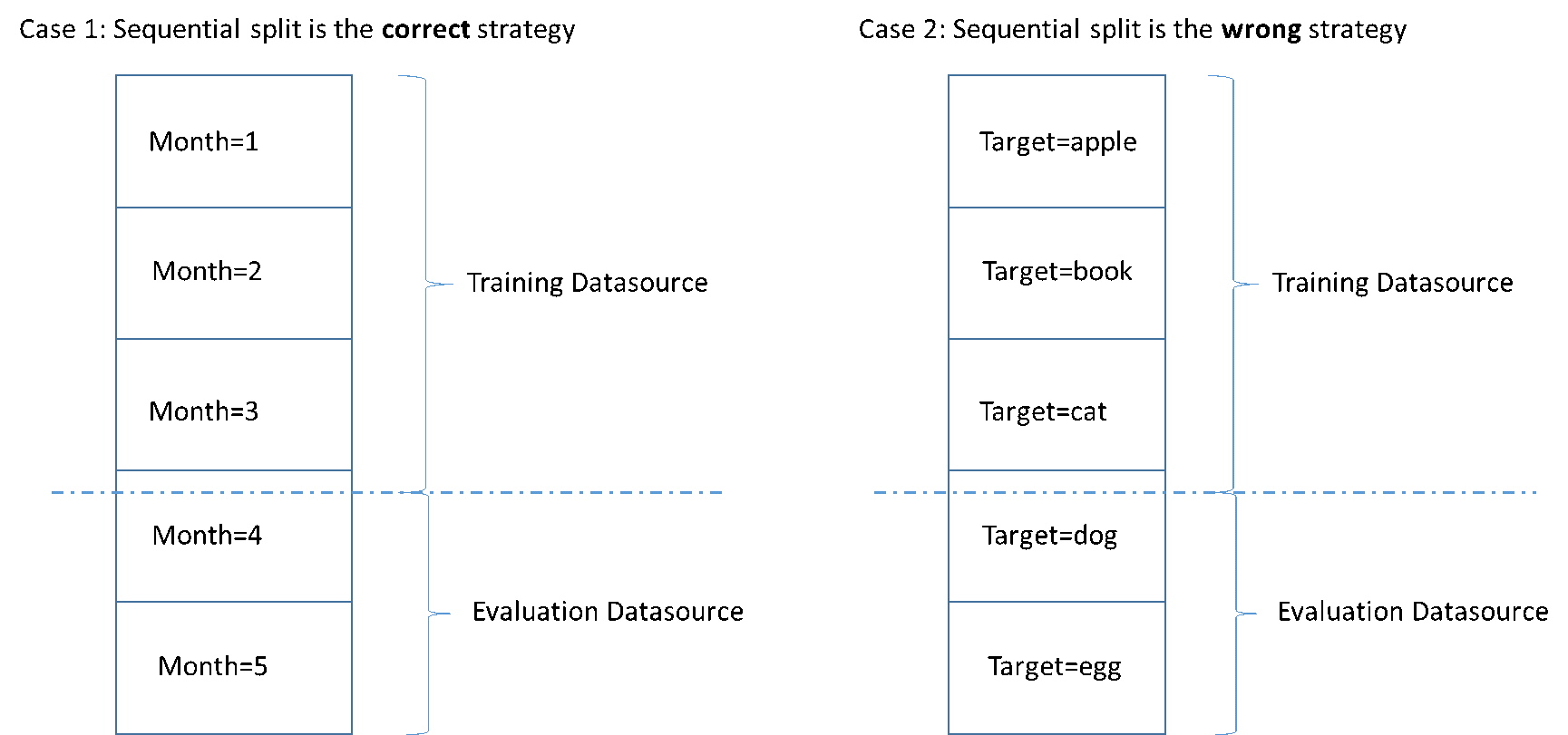
Quando você cria uma fonte de dados, pode optar por dividi-la sequencialmente. O Amazon ML usa os primeiros 70 por cento de seus dados para treinamento e os 30 por cento restantes para avaliação. Essa é a abordagem padrão quando você usa o console do Amazon ML para dividir dados.
Dividir dados aleatoriamente
A divisão aleatória dos dados de entrada em fontes de dados de treinamento e avaliação garante que a distribuição dos dados seja semelhante nas fontes de dados de avaliação e treinamento. Escolha esta opção quando você não precisa preservar a ordem dos dados de entrada.
O Amazon ML usa um método propagado pseudoaleatório de geração de números para dividir os dados. A propagação se baseia em parte em um valor de string de entrada e parcialmente no conteúdo dos dados propriamente ditos. Por padrão, o console do Amazon ML usa o local do S3 dos dados de entrada como a string. Os usuários da API podem fornecer uma string personalizada. Isso significa que dados os mesmos bucket do S3 e dados, o Amazon ML divide os dados da mesma maneira sempre. Para alterar o modo como o Amazon ML divide os dados, você pode usar a API CreateDatasourceFromS3, CreateDatasourceFromRedshift ou CreateDatasourceFromRDS e fornecer um valor para a string de propagação. Ao usar essas APIs para criar fontes de dados separadas para treinamento e avaliação, é importante usar o mesmo valor de string de propagação para as duas fontes de dados e o sinalizador complementar para uma fonte de dados a fim de garantir que não haja sobreposição entre os dados de treinamento e de avaliação.
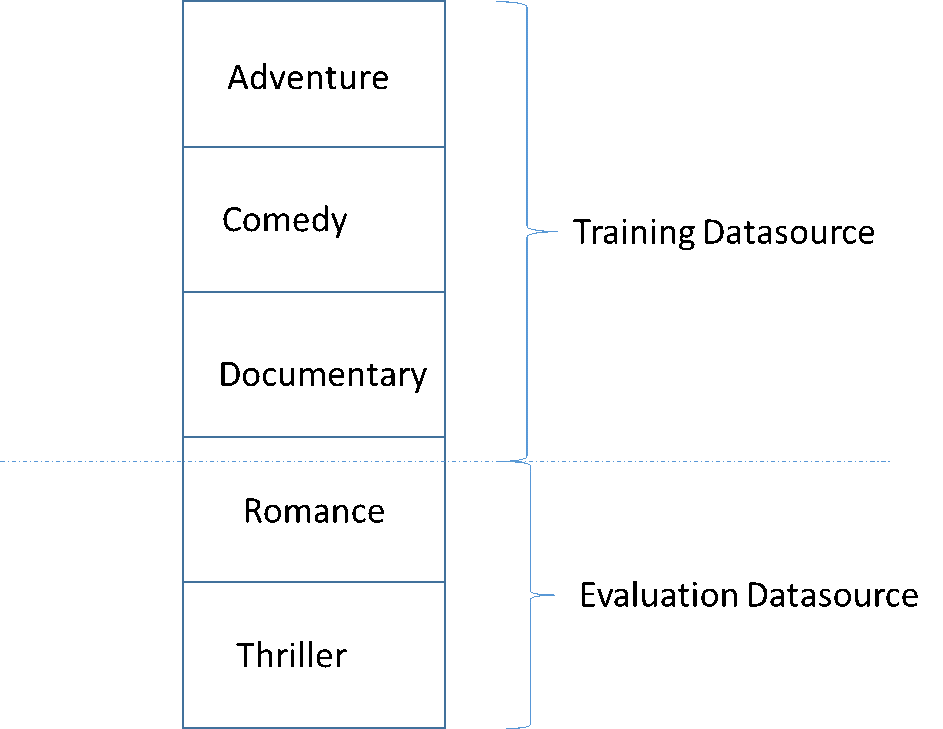
Uma armadilha comum no desenvolvimento de um modelo de ML de alta qualidade é avaliar o modelo de ML com dados que não são semelhantes àqueles usados para treinamento. Por exemplo, digamos que você esteja usando ML para prever o gênero de filmes e seus dados de treinamento contêm filmes dos gêneros Aventura, Comédia e Documentário. Contudo, os dados de avaliação contêm apenas dados dos gêneros Romance e Suspense. Nesse caso, o modelo de ML não aprendeu informações sobre os gêneros Romance e Suspense, e a avaliação não avaliou a qualidade do aprendizado do modelo sobre padrões referentes aos gêneros Aventura, Comédia e Documentário. Como resultado, as informações sobre gênero são inúteis e a qualidade das previsões do modelo de ML para todos os gêneros está comprometida. O modelo e a avaliação são muito diferentes (têm estatísticas descritivas muito diferentes) para serem úteis. Isso pode acontecer quando os dados de entrada são classificados por uma das colunas no conjunto de dados e, em seguida, divididos sequencialmente.
Se as fontes de dados de avaliação e treinamento tiverem distribuições de dados diferentes, você verá um alerta de avaliação na avaliação do modelo. Para obter mais informações sobre alertas de avaliação, consulte Alertas de avaliação.
Você não precisará usar a divisão aleatória no Amazon ML se já tiver randomizado os dados de entrada, por exemplo, embaralhando aleatoriamente os dados de entrada no Amazon S3 ou usando uma função random() de consulta SQL do Amazon Redshift ou uma função rand() de consulta SQL do MySQL ao criar as fontes de dados. Nesses casos, você pode contar com a opção de divisão sequencial para criar fontes de dados de treinamento e avaliação com distribuições semelhantes.
