Não estamos mais atualizando o serviço Amazon Machine Learning nem aceitando novos usuários para ele. Essa documentação está disponível para usuários existentes, mas não estamos mais atualizando-a. Para obter mais informações, consulte O que é o Amazon Machine Learning.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Etapa 2: Criar uma fonte de dados de treinamento
Após fazer upload do conjunto de dados banking.csv para o local do Amazon Simple Storage Service (Amazon S3), você o usará para criar uma fonte de dados de treinamento. Uma fonte de dados é um objeto do Amazon Machine Learning (Amazon ML) que contém o local dos dados de entrada e metadados importantes sobre os dados de entrada. O Amazon ML usa a fonte de dados para operações como o treinamento e a avaliação do modelo de ML.
Para criar uma fonte de dados, forneça os seguintes dados:
-
O local dos dados no Amazon S3 e a permissão para acessar esses dados
-
O esquema, que inclui os nomes dos atributos nos dados e o tipo de cada atributo (numérico, texto, categórico ou binário)
-
O nome do atributo que contém a resposta que o Amazon ML deve reconhecer para fazer a previsão: o atributo de destino
nota
Na verdade, a fonte de dados não armazena os dados, ele apenas faz referência a eles. Evite mover ou alterar os arquivos armazenados no Amazon S3. Se você movê-los ou alterá-los, o Amazon ML não poderá acessá-los para criar um modelo de ML, gerar avaliações ou gerar previsões.
Para criar a fonte de dados de treinamento
Abra o console do Amazon Machine Learning em https://console.aws.amazon.com/machinelearning/
. -
Escolha Começar.
nota
Este tutorial assume que esta é a primeira vez que você está usando Amazon ML. Se você tiver usado o Amazon ML anteriormente, use a lista suspensa Criar novo no painel do Amazon ML para criar uma nova fonte de dados.
-
Na página Conceitos básicos do Amazon Machine Learning, escolha Iniciar.

-
Na página Input Data (Dados de entrada), em Where is your data located (Onde os dados estão localizados)?, verifique se S3 está selecionado.

-
Em S3 Location (Local do S3), digite o local completo do arquivo
banking.csvda Etapa 1: Preparar os dados. Por exemplo:your-bucket/banking.csv. O Amazon ML insere s3:// no início do nome do bucket. -
Em Datasource Name (Nome da fonte de dados), digite
Banking Data 1.
-
Escolha Verificar.
-
Na caixa de diálogo S3 permissions (Permissões do S3), escolha Yes (Sim).

-
Se o Amazon ML puder acessar e ler o arquivo de dados no local do S3, você verá uma página semelhante à seguinte. Analise as propriedades e escolha Continue (Continuar).

Em seguida, estabeleça um esquema. Um esquema são as informações de que o Amazon ML precisa para interpretar os dados de entrada de um modelo de ML, incluindo nomes de atributos, os tipos de dados atribuídos e os nomes dos atributos especiais. Há duas maneiras de fornecer o Amazon ML com um esquema:
-
Forneça um arquivo de esquema separado ao fazer upload dos dados do Amazon S3.
-
Permita que o Amazon ML faça a inferência dos tipos de atributo e crie um esquema para você.
Neste tutorial, solicitaremos que o Amazon ML faça a inferência do esquema.
Para obter mais informações sobre como criar um arquivo de esquema separado, consulte Criar um esquema de dados para o Amazon ML.
Para permitir que o Amazon ML faça a inferência do esquema
-
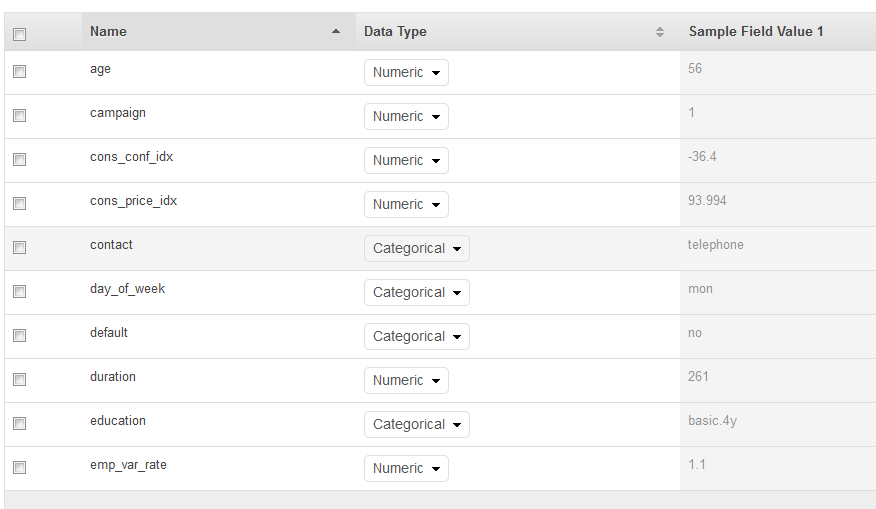
Na página Esquema, o Amazon ML mostra o esquema que inferiu. Analise os tipos de dados que o Amazon ML inferiu para os atributos. É importante que os atributos recebam o tipo de dados correto para que o Amazon ML possa inserir os dados corretamente e habilitar o processamento de recurso correto nos atributos.
-
Os atributos que têm apenas dois estados possíveis, como yes (sim) ou no (não), devem ser marcados como Binary (Binários).
-
Os atributos que são números ou strings usados para denotar uma categoria devem ser marcados como Categorical (Categóricos).
-
Os atributos que são quantidades numéricas para as quais o pedido é significativo devem ser marcados como Numeric (Numéricos).
-
Os atributos que são strings que você deseja tratar como palavras delimitadas por espaços devem ser marcados como Text (Texto).
-
-
Neste tutorial, o Amazon ML identificou corretamente os tipos de dados de todos os atributos, portanto, escolha Continuar.
Em seguida, selecione um atributo de destino.
Lembre-se de que o destino é o atributo que o modelo de ML precisa reconhecer para fazer a previsão. O atributo y indica se um indivíduo se inscreveu em uma campanha no passado: 1 (sim) ou 0 (não).
nota
Escolha um atributo de destino somente se você pretende usar a fonte de dados para o treinamento e a avaliação dos modelos de ML.
Para selecionar y como atributo de destino
-
No canto inferior direito da tabela, escolha a seta única para avançar para a última página da tabela, local em que o atributo
yserá exibido.
-
Na coluna Target (Destino), selecione
y.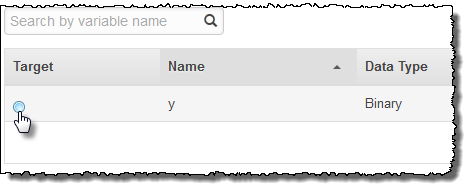
O Amazon ML confirma que y foi selecionado como destino.
-
Escolha Continuar.
-
Na página Row ID (ID da linha), em Does your data contain an identifier? (Os dados contêm um identificador?), verifique se No (Não), o padrão, está selecionado.
-
Escolha Review (Rever) e, em seguida, escolha Continue (Continuar).
Agora que tem uma fonte de dados de treinamento, você está pronto para criar o modelo.
