As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Opções de configuração para identificadores de dados personalizados
Ao usar identificadores de dados personalizados, você pode definir critérios personalizados para detectar dados confidenciais em objetos do Amazon Simple Storage Service (Amazon S3). Você pode complementar os identificadores de dados gerenciados fornecidos pelo Amazon Macie e detectar dados confidenciais que refletem cenários, propriedade intelectual ou dados proprietários particulares da organização.
Cada identificador de dados personalizado especifica critérios de detecção e, como opção, configurações de severidade das descobertas produzidas pelo identificador. Os critérios de detecção especificam uma expressão regular que define um padrão de texto para corresponder em um objeto do S3. Os critérios também podem especificar sequências de caracteres e uma regra de proximidade que refina os resultados. As configurações de severidade especificam qual severidade atribuir às descobertas. A severidade pode ser baseada no número de ocorrências de texto que correspondem aos critérios de detecção do identificador.
Critérios de detecção
Ao criar um identificador de dados personalizado, você especifica uma expressão regular (regex) que define um padrão de texto para correspondência. Você também pode especificar sequências de caracteres, como palavras e frases, e uma regra de proximidade que refine os resultados. As sequências de caracteres podem ser: palavras-chave, que são palavras ou frases que devem estar próximas ao texto que corresponde ao regex, ou ignorar palavras, que são palavras ou frases para excluir dos resultados.
Para o regex, o Amazon Macie suporta um subconjunto da sintaxe do padrão fornecida pela biblioteca Perl Compatible Regular Expressions (PCRE)
-
Referências anteriores
-
Capturar grupos
-
Padrões condicionais
-
Código incorporado
-
Sinalizadores de padrões globais, como
/i/m, e/x -
Padrões recursivos
-
Afirmações positivas e negativas de largura zero de retrospectiva e prospectiva, como e
?=,?!,?<=e?<!.
A regex pode conter até 512 caracteres.
Para criar um padrão regex eficaz para um identificador de dados personalizado, observe as dicas e recomendações a seguir:
-
Use âncoras (
^ou$) somente se você esperar que o padrão apareça no início ou no final de um arquivo, não no início ou no final de uma linha. -
Por motivos de desempenho, o Macie limita o tamanho dos grupos de repetição vinculados. Por exemplo,
\d{100,1000}não compilará no Macie. Para aproximar essa funcionalidade, você pode usar uma repetição aberta, como.\d{100,} -
Para tornar partes de um padrão insensíveis a maiúsculas e minúsculas, use o constructo
(?i)em vez do sinalizador/i. -
Não há necessidade de otimizar prefixos ou alternâncias manualmente. Por exemplo, mudar
/hello|hi|hey/para/h(?:ello|i|ey)/não melhorará o desempenho. -
Por motivos de desempenho, o Macie limita o número de curingas repetidos. Por exemplo,
a*b*a*não compilará no Macie.
Para se proteger contra expressões malformadas ou de longa duração, o Macie testa automaticamente os padrões regex em uma coleção de texto de amostra quando você cria um identificador de dados personalizado. Se houver um problema com o regex, o Macie retornará um erro descrevendo o que aconteceu.
Além do regex, você pode especificar sequências de caracteres e uma regra de proximidade para refinar os resultados.
- Palavras-chave
-
Estas são sequências de caracteres específicas que devem estar próximas do texto que corresponde ao padrão regex. Os requisitos de proximidade variam de acordo com o formato de armazenamento ou o tipo de arquivo de um objeto S3:
-
Dados colunares estruturados — o Macie inclui um resultado se o texto corresponder ao padrão regex e uma palavra-chave estiver no nome do campo ou coluna que armazena o texto, ou se o texto for precedido por e dentro da distância máxima de correspondência de uma palavra-chave no mesmo campo ou valor de célula. Isso vale para pastas de trabalho do Microsoft Excel, arquivos CSV e arquivos TSV.
-
Dados estruturados baseados em registros — o Macie inclui um resultado se o texto corresponder ao padrão regex e estiver dentro da distância máxima de correspondência de uma palavra-chave. A palavra-chave pode estar no nome de um elemento no caminho para o campo ou matriz que armazena o texto, ou pode preceder e fazer parte do mesmo valor no campo ou matriz que armazena o texto. Isso vale para contêineres de objetos Apache Avro, arquivos Apache Parquet, arquivos JSON e arquivos JSON Lines.
-
Dados não estruturados: o Macie inclui um resultado se o texto corresponder ao padrão regex e for precedido e estiver dentro da distância máxima de correspondência de uma palavra-chave. Isso vale para arquivos Adobe Portable Document Format, documentos do Microsoft Word, mensagens de e-mail e arquivos de texto não binários que não sejam arquivos CSV, JSON, JSON Lines e TSV. Isso inclui quaisquer dados estruturados, como tabelas, nesses tipos de arquivos.
Você pode especificar até 50 palavras-chave. Cada palavra-chave pode conter de 3 a 90 caracteres UTF-8. Palavras-chave não diferenciam maiúsculas de minúsculas.
-
- Distância máxima de partida
-
Essa é uma regra de proximidade baseada em caracteres para palavras-chave. O Macie usa essa configuração para determinar se uma palavra-chave precede o texto que corresponde ao padrão regex. A configuração define o número máximo de caracteres que podem existir entre o fim de uma palavra-chave completa e o fim do texto que corresponde ao padrão regex. O Macie incluirá um resultado se o texto:
-
Corresponder ao padrão regex,
-
Ocorrer após pelo menos uma palavra-chave completa e
-
Ocorrer dentro da distância especificada da palavra-chave.
Caso contrário, Macie excluirá o texto dos resultados.
Você pode especificar uma distância de 1 a 300 caracteres. A distância padrão é de 50 caracteres. Para obter melhores resultados, essa distância deve ser maior que o número mínimo de caracteres de texto que o regex foi projetado para detectar. Se apenas parte do texto estiver dentro da distância máxima de correspondência de uma palavra-chave, Macie não a incluirá nos resultados.
-
- Ignorar palavras
-
Essas são sequências de caracteres específicas a serem excluídas dos resultados. Se o texto corresponder ao padrão regex, mas contiver uma palavra ignorada, Macie não a incluirá nos resultados.
Você pode especificar até 10 palavras ignoradas. Cada palavra a ser ignorada pode conter de 4 a 90 caracteres UFT-8. Palavras ignoradas diferenciam maiúsculas de minúsculas.
nota
Antes de criar um identificador de dados personalizado, é altamente recomendável testar e refinar seus critérios de detecção com dados de amostra. Como os identificadores de dados personalizados são usados por trabalhos confidenciais de descoberta de dados, você não pode alterar um identificador de dados personalizado depois de criá-lo. Isso ajuda a garantir que você tenha um histórico imutável de descobertas de dados sigilosos e resultados de descoberta para auditorias de privacidade de dados e proteção de dados ou investigações que você realiza.
Você pode testar os critérios de detecção usando o console do Amazon Macie ou a API do Amazon Macie. Para testar os critérios usando o console, use as opções na seção Avaliar ao criar o identificador de dados personalizado. Para testar os critérios de forma programática, use a TestCustomDataIdentifieroperação da API Amazon Macie. Se você estiver usando o AWS Command Line Interface, execute o test-custom-data-identifiercomando para testar os critérios.
Para ver uma demonstração de como as palavras-chave podem ajudar você a encontrar dados confidenciais e evitar falsos positivos, assista ao vídeo a seguir:
Configurações de severidade das descobertas
Ao criar um identificador de dados personalizado, você também pode especificar configurações de severidade personalizadas para descobertas de dados confidenciais produzidas pelo identificador. Por padrão, o Amazon Macie atribui a severidade Média a todas as descobertas produzidas por um identificador de dados personalizado. O Macie atribuirá de forma automática a severidade Média à descoberta resultante se um objeto S3 contiver pelo menos uma ocorrência de texto que corresponda aos critérios de detecção.
Com as configurações de severidade personalizadas, você especifica qual severidade atribuir com base no número de ocorrências de texto que correspondem aos critérios de detecção. Você pode definir limites de ocorrências para até três níveis de severidade: Baixo (menos grave), Médio e Alto (mais grave). Um limite de ocorrências é o número mínimo de correspondências que devem existir em um objeto do S3 para produzir uma descoberta com a gravidade especificada. Se você especificar mais de um limite, os limites deverão estar em ordem crescente por severidade, passando de Baixo para Alto.
Por exemplo, a imagem a seguir mostra as configurações de severidade que especificam três limites de ocorrências, um para cada nível suportado pelo Macie.
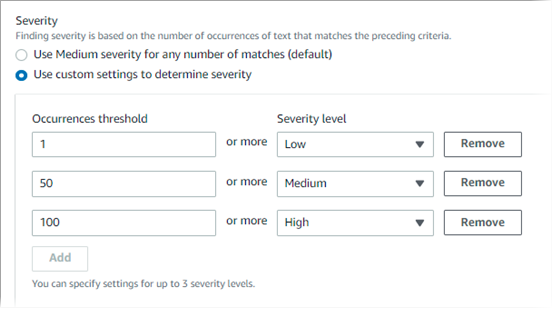
A tabela a seguir indica a gravidade das descobertas que o identificador de dados personalizado produz.
| Limite de ocorrências | Nível de gravidade | Resultado |
|---|---|---|
| 1 | Baixo | Se um objeto do S3 contiver de 1 a 49 ocorrências de texto que correspondam aos critérios de detecção, a gravidade da descoberta resultante será Baixa. |
| 50 | Médio | Se um objeto do S3 contiver de 50 a 99 ocorrências de texto que correspondam aos critérios de detecção, a gravidade da descoberta resultante será Média. |
| 100 | Alta | Se um objeto do S3 contiver 100 ou mais ocorrências de texto que correspondam aos critérios de detecção, a gravidade da descoberta resultante será Alta. |
Você também pode usar as configurações de gravidade para especificar se deseja criar uma descoberta. Se um objeto do S3 contiver menos ocorrências do que o limite mais baixo de ocorrências, o Macie não criará uma descoberta.
