As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Saiba mais sobre conectores
Um conector integra sistemas externos e serviços da Amazon ao Apache Kafka, copiando continuamente dados de streaming de uma fonte de dados para o cluster do Apache Kafka ou copiando continuamente os dados do cluster para um coletor de dados. Antes de entregar os dados a um destino, um conector também pode executar uma lógica leve, como transformação, conversão de formato ou filtragem de dados. Os conectores de origem extraem dados de uma fonte de dados e os enviam para o cluster, enquanto os conectores coletam dados do cluster e os enviam para um coletor de dados.
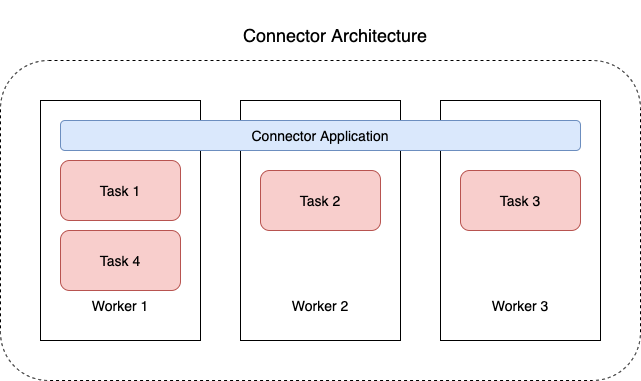
O diagrama a seguir mostra a arquitetura de um conector. Um operador é um processo de máquina virtual Java (JVM) que executa a lógica do conector. Cada operador cria um conjunto de tarefas que são executadas em threads paralelos e fazem o trabalho de copiar os dados. As tarefas não armazenam o estado e, portanto, podem ser iniciadas, interrompidas ou reiniciadas a qualquer momento para fornecer um pipeline de dados resiliente e escalável.