As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como o Amazon MSK Replicator funciona
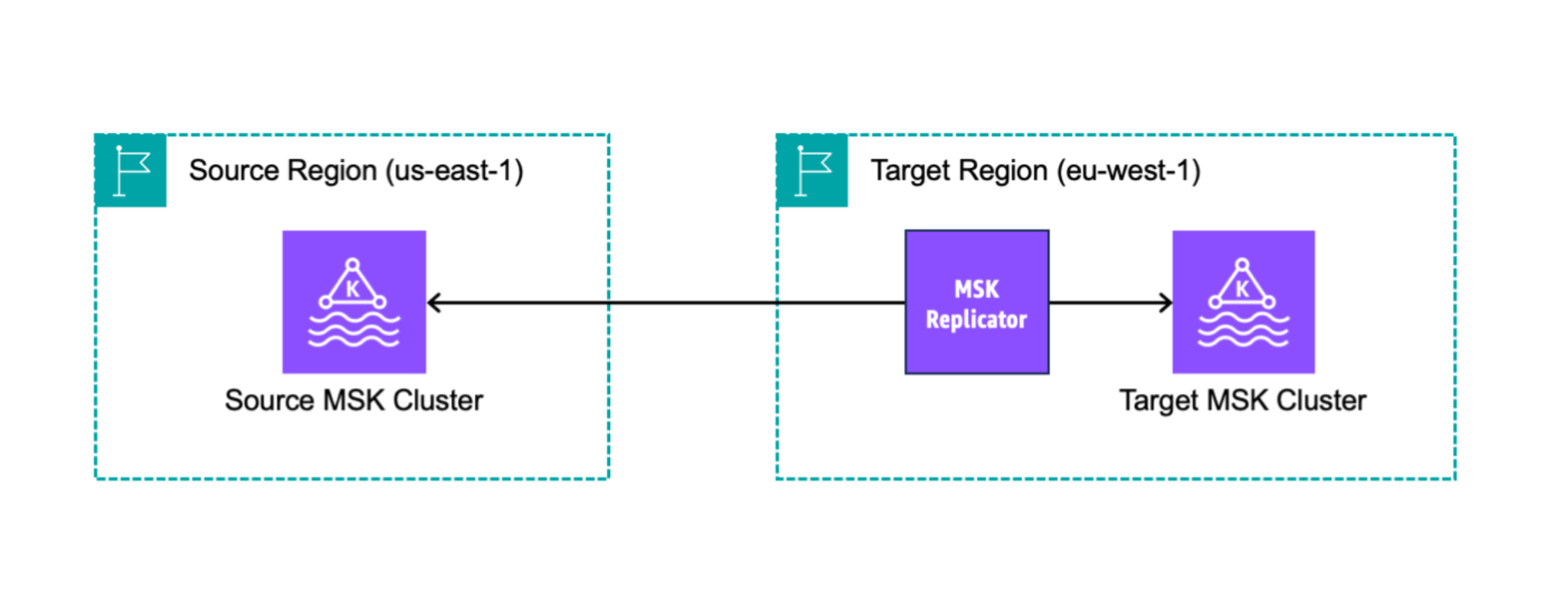
Para começar a usar o MSK Replicator, você precisa criar um novo replicador na região do seu cluster de AWS destino. MSKO Replicator copia automaticamente todos os dados do cluster na AWS região primária chamada origem para o cluster na região de destino chamada destino. Os clusters de origem e de destino podem estar na mesma região ou em AWS regiões diferentes. Você precisará criar o cluster de destino se ele não existir.
Quando você cria um replicador, o MSK Replicator implanta todos os recursos necessários na AWS região do cluster de destino para otimizar a latência da replicação de dados. A latência de replicação varia com base em muitos fatores, incluindo a distância da rede entre as AWS regiões dos seus MSK clusters, a capacidade de taxa de transferência dos clusters de origem e de destino e o número de partições nos clusters de origem e de destino. MSKO Replicator escala automaticamente os recursos subjacentes para que você possa replicar dados sob demanda sem precisar monitorar ou escalar a capacidade.
Replicação de dados
Por padrão, o MSK Replicator copia todos os dados de forma assíncrona do deslocamento mais recente nas partições de tópicos do cluster de origem para o cluster de destino. Se a configuração “Detectar e copiar novos tópicos” estiver ativada, o MSK Replicator detectará e copiará automaticamente novos tópicos ou partições de tópicos para o cluster de destino. No entanto, pode levar até 30 segundos para que o Replicator detecte e crie os novos tópicos ou partições de tópicos no cluster de destino. Qualquer mensagem produzida no tópico de origem antes da criação do tópico no cluster de destino não será replicada. Como alternativa, você pode configurar seu replicador durante a criação para iniciar a replicação a partir do primeiro deslocamento nas partições de tópicos do cluster de origem, se quiser replicar as mensagens existentes em seus tópicos para o cluster de destino.
MSKO Replicator não armazena seus dados. Os dados são consumidos do seu cluster de origem, armazenados em buffer na memória e gravados no cluster de destino. O buffer é limpo automaticamente quando os dados são gravados com sucesso ou falham após novas tentativas. Toda a comunicação e os dados entre o MSK Replicator e seus clusters são sempre criptografados em trânsito. Todas as API chamadas MSK do ReplicatorDescribeClusterV2, como,CreateTopic, DescribeTopicDynamicConfiguration são capturadas em AWS CloudTrail. Os registros do seu MSK corretor também refletirão o mesmo.
MSKO Replicator cria tópicos no cluster de destino com um fator de replicador de 3. Se necessário, você pode modificar o fator de replicação diretamente no cluster de destino.
Replicação de metadados
MSKO Replicator também suporta a cópia dos metadados do cluster de origem para o cluster de destino. Os metadados incluem configuração de tópicos, listas de controle de acesso (ACLs) e compensações de grupos de consumidores. Assim como a replicação de dados, a replicação de metadados também acontece de forma assíncrona. Para um melhor desempenho, o MSK Replicator prioriza a replicação de dados sobre a replicação de metadados.
A tabela a seguir é uma lista das listas de controle de acesso (ACLs) que o MSK Replicator copia.
| Operation | Pesquisa | APIspermitido |
|---|---|---|
|
Alter |
Tópico |
CreatePartitions |
|
AlterConfigs |
Tópico |
AlterConfigs |
|
Criar |
Tópico |
CreateTopics, Metadados |
|
Delete |
Tópico |
DeleteRecords, DeleteTopics |
|
Descrever |
Tópico |
ListOffsets, Metadados,, OffsetFetch OffsetForLeaderEpoch |
|
DescribeConfigs |
Tópico |
DescribeConfigs |
|
Leitura |
Tópico |
Busque,, OffsetCommit TxnOffsetCommit |
|
Escreva (somente negue) |
Tópico |
Produzir, AddPartitionsToTxn |
MSKO replicador copia o tipo de LITERAL padrão ACLs somente para o tipo de recurso Topic. PREFIXEDo tipo de padrão ACLs e outro tipo de recurso não ACLs são copiados. MSKO replicador também não exclui ACLs no cluster de destino. Se você excluir um ACL no cluster de origem, também deverá excluir no cluster de destino ao mesmo tempo. Para obter mais detalhes sobre os ACLs recursos, padrões e operações do Kafka, consulte https://kafka.apache.org/documentation/#security_authz_cli.
MSKO Replicator replica somente o KafkaACLs, que o controle de IAM acesso não usa. Se seus clientes estiverem usando controle de IAM acesso para ler/gravar em seus MSK clusters, você também precisará configurar as IAM políticas relevantes no cluster de destino para um failover contínuo. Isso também vale para configurações de replicação de nomes de tópicos prefixados e idênticos.
Como parte da sincronização de offsets de grupos de consumidores, o MSK Replicator otimiza para seus consumidores no cluster de origem, que estão lendo de uma posição próxima à ponta do stream (final da partição do tópico). Se seus grupos de consumidores estiverem atrasados no cluster de origem, você poderá observar um atraso maior para esses grupos de consumidores no destino em comparação com a origem. Isso significa que, após o failover para o cluster de destino, seus consumidores reprocessarão mais mensagens duplicadas. Para reduzir esse atraso, seus consumidores no cluster de origem precisariam se atualizar e começar a consumir a partir da ponta do stream (final da partição do tópico). À medida que seus consumidores se atualizarem, o MSK Replicator reduzirá automaticamente o atraso.
Configuração do nome do tópico
MSKO Replicator tem dois modos de configuração de nomes de tópicos: prefixados (padrão) ou replicação de nomes de tópicos idênticos.
Replicação de nomes de tópicos prefixados
Por padrão, o MSK Replicator cria novos tópicos no cluster de destino com um prefixo gerado automaticamente adicionado ao nome do tópico do cluster de origem, como. <sourceKafkaClusterAlias>.topic Isso serve para distinguir os tópicos replicados de outros no cluster de destino e evitar a replicação circular de dados entre os clusters.
Por exemplo, o MSK Replicator replica dados em um tópico chamado “tópico” do cluster de origem para um novo tópico no cluster de destino chamado < sourceKafkaCluster Alias>.topic. Você pode encontrar o prefixo que será adicionado aos nomes dos tópicos no cluster de destino no campo sourceKafkaClusterAlias usando DescribeReplicator API ou na página de detalhes do Replicador no console. MSK O prefixo no cluster de destino é < sourceKafkaCluster Alias>.
Para garantir que seus consumidores possam reiniciar o processamento de forma confiável a partir do cluster em espera, você precisa configurar seus consumidores para ler os dados dos tópicos usando um operador curinga. .* Por exemplo, seus consumidores precisariam consumir usando. *topic1em ambas as AWS regiões. Esse exemplo também incluiria um tópico comofootopic1, portanto, ajuste o operador curinga de acordo com suas necessidades.
Você deve usar o MSK Replicator, que adiciona um prefixo quando quiser manter os dados do replicador em um tópico separado no cluster de destino, como para configurações de cluster ativo-ativo.
Replicação idêntica de nomes de tópicos
Como alternativa à configuração padrão, o Amazon MSK Replicator permite que você crie um replicador com replicação de tópicos definida como Replicação de nomes de tópicos idênticos (mantenha o mesmo nome de tópico no console). Você pode criar um novo replicador na AWS região que tenha seu MSK cluster de destino. Tópicos replicados com nomes idênticos permitem que você evite reconfigurar clientes para ler tópicos replicados.
A replicação idêntica de nomes de tópicos (mantenha o mesmo nome de tópicos no console) tem as seguintes vantagens:
Permite que você mantenha nomes de tópicos idênticos durante o processo de replicação, além de evitar automaticamente o risco de ciclos de replicação infinitos.
Simplifica a configuração e a operação de arquiteturas de streaming de vários clusters, pois você pode evitar a reconfiguração de clientes para ler os tópicos replicados.
Para arquiteturas de cluster ativo-passivo, a funcionalidade idêntica de replicação de nomes de tópicos também simplifica o processo de failover, permitindo que os aplicativos façam o failover perfeito para um cluster em espera sem exigir nenhuma alteração no nome do tópico ou reconfiguração do cliente.
Pode ser usado para consolidar mais facilmente dados de vários MSK clusters em um único cluster para agregação de dados ou análise centralizada. Isso exige que você crie replicadores separados para cada cluster de origem e para o mesmo cluster de destino.
Pode simplificar a migração de dados de um MSK cluster para outro replicando dados para tópicos com nomes idênticos no cluster de destino.
O Amazon MSK Replicator usa cabeçalhos Kafka para evitar automaticamente que os dados sejam replicados de volta ao tópico de origem, eliminando o risco de ciclos infinitos durante a replicação. Um cabeçalho é um par de valores-chave que pode ser incluído com a chave, o valor e o timestamp em cada mensagem do Kafka. MSKO Replicator incorpora identificadores para cluster e tópico de origem no cabeçalho de cada registro que está sendo replicado. MSKO Replicator usa as informações do cabeçalho para evitar loops infinitos de replicação. Você deve verificar se seus clientes conseguem ler os dados replicados conforme o esperado.
