As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Integração dos pipelines OpenSearch de ingestão da Amazon com outros serviços e aplicativos
Para ingerir dados com sucesso em um pipeline de OpenSearch ingestão da Amazon, você deve configurar seu aplicativo cliente (a fonte) para enviar dados para o endpoint do pipeline. Sua fonte pode ser clientes como os registros do Fluent Bit, o OpenTelemetry Collector ou um simples bucket S3. A configuração exata é diferente para cada cliente.
As diferenças importantes durante a configuração da fonte (em comparação com o envio de dados diretamente para um domínio de OpenSearch serviço ou coleção OpenSearch sem servidor) são o nome do AWS serviço (osis) e o endpoint do host, que deve ser o endpoint do pipeline.
Criar o endpoint de ingestão
Para ingerir dados em um pipeline, envie-os para o endpoint de ingestão. Para localizar a URL de ingestão, navegue até a página Configurações do pipeline e copie a URL de ingestão.
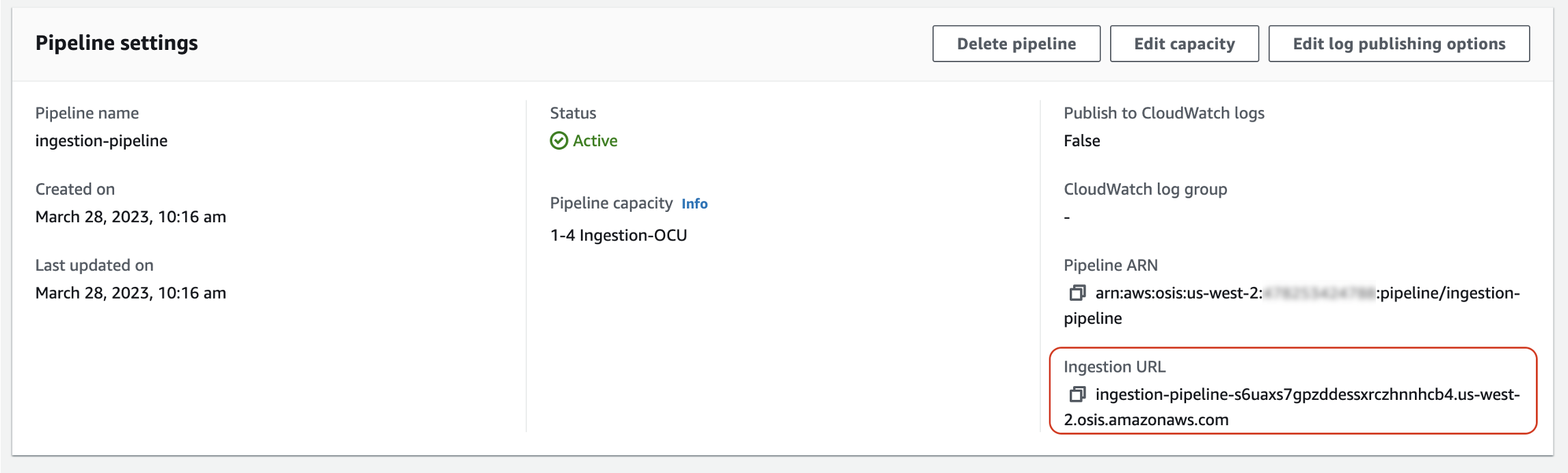
Para criar o endpoint de ingestão completo para fontes baseadas em pull, como OTel rastreamento
Por exemplo, digamos que a configuração do pipeline tem o seguinte caminho de ingestão:

O endpoint de ingestão completo, que você especifica na configuração do seu cliente, terá o seguinte formato: https://.ingestion-pipeline-abcdefg.us-east-1.osis.amazonaws.com/my/test_path
Criação de uma função de ingestão
Todas as solicitações de OpenSearch ingestão devem ser assinadas com o Signature versão 4. No mínimo, a função que assina a solicitação deve receber permissão para a osis:Ingest ação, o que permite que ela envie dados para um pipeline OpenSearch de ingestão.
Por exemplo, a política a seguir AWS Identity and Access Management (IAM) permite que a função correspondente envie dados para um único pipeline:
nota
Para usar a função em todos os pipelines, substitua o ARN no elemento Resource por um caractere curinga (*).
Concessão de acesso de ingestão entre contas
nota
Você só pode fornecer acesso de ingestão entre contas para pipelines públicos, não para pipelines de VPC.
Talvez seja necessário ingerir dados em um pipeline de outro Conta da AWS, como uma conta que hospeda seu aplicativo de origem. Se a entidade principal que está gravando em um pipeline estiver em uma conta diferente do próprio pipeline, você precisará configurar a entidade principal para confiar em outro perfil do IAM para ingerir dados no pipeline.
Como configurar permissões de ingestão entre contas
-
Crie a função de ingestão com
osis:Ingestpermissão (descrita na seção anterior) dentro da Conta da AWS mesma função do pipeline. Para obter instruções, consulte Como criar perfis do IAM. -
Vincule uma política de confiança à função de ingestão que permita que uma entidade principal em outra conta a assuma:
-
Na outra conta, configure seu aplicativo cliente (por exemplo, Fluent Bit) para assumir a função de ingestão. Para que isso funcione, a conta do aplicativo deve conceder permissões ao usuário ou à função do aplicativo para assumir a função de ingestão.
O exemplo a seguir de política baseada em identidade permite que a entidade principal anexada assuma o
ingestion-rolea partir da conta do pipeline:
O aplicativo cliente pode então usar a AssumeRoleoperação para assumir ingestion-role e ingerir dados no pipeline associado.
Próximas etapas
Depois de exportar seus dados para um pipeline, você pode consultá-los no domínio OpenSearch Service que está configurado como um coletor para o pipeline. Os seguintes recursos podem ajudá-lo a começar:
