As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Monitoramento OpenSearch de métricas de cluster com a Amazon CloudWatch
O Amazon OpenSearch Service publica dados de seus domínios na Amazon. CloudWatch CloudWatch permite recuperar estatísticas sobre esses pontos de dados como um conjunto ordenado de dados de séries temporais, conhecido como métricas. OpenSearch O serviço envia a maioria das métricas CloudWatch em intervalos de 60 segundos. Se você usar volumes magnéticos do EBS ou de uso geral, as métricas do volume do EBS serão atualizadas somente a cada cinco minutos. Todas as métricas cumulativas (por exemplo, ThreadpoolWriteRejected e ThreadpoolSearchRejected) estão na memória e perderão o estado. As métricas serão redefinidas durante a queda do nó, a rejeição do nó, a substituição do nó e a blue/green implantação. Para obter mais informações sobre a Amazon CloudWatch, consulte o Guia CloudWatch do usuário da Amazon.
O console OpenSearch de serviço exibe uma série de gráficos com base nos dados brutos de CloudWatch. Dependendo de suas necessidades, talvez você prefira visualizar os dados do cluster em CloudWatch vez dos gráficos no console. O serviço mantém as métricas arquivadas por duas semanas e depois as descarta. As métricas são fornecidas sem custo adicional, mas CloudWatch ainda cobram pela criação de painéis e alarmes. Para obter mais informações, consulte os CloudWatchpreços da Amazon
OpenSearch O serviço publica as seguintes métricas para CloudWatch:
Visualizando métricas em CloudWatch
CloudWatch as métricas são agrupadas primeiro pelo namespace do serviço e depois pelas várias combinações de dimensões em cada namespace.
Para visualizar métricas usando o CloudWatch console
-
Abra o CloudWatch console em https://console.aws.amazon.com/cloudwatch/
. -
No painel de navegação à esquerda, localize Métricas e escolha Todas as métricas. Selecione o namespace ES.
-
Escolha uma dimensão para visualizar as métricas correspondentes. As métricas para nós individuais estão na dimensão
ClientId, DomainName, NodeId. As métricas de cluster estão na dimensãoPer-Domain, Per-Client Metrics. Algumas métricas de nó são agregadas no nível do cluster e, portanto, incluídas em ambas as dimensões. As métricas de fragmentos estão na dimensãoClientId, DomainName, NodeId, ShardRole.
Para ver uma lista de métricas usando o AWS CLI
Execute este comando: .
aws cloudwatch list-metrics --namespace "AWS/ES"
Interpretando prontuários de saúde em serviço OpenSearch
Para visualizar métricas no OpenSearch Serviço, use as guias Integridade do cluster e Integridade da instância. A guia Integridade da instância usa gráficos de caixa para fornecer visibilidade rápida da integridade de cada nó: OpenSearch
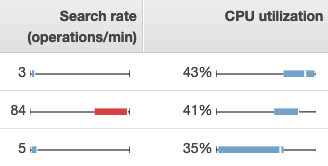
-
Cada caixa colorida mostra a faixa de valores do nó ao longo do período de tempo especificado.
-
As caixas azuis representam valores que são consistentes com outros nós. As caixas vermelhas representam exceções.
-
A linha branca dentro de cada caixa de seleção mostra o valor atual do nó.
-
As “caixas estreitas” em cada lado de cada caixa mostram os valores mínimo e máximo de todos os nós ao longo do período de tempo.
Se você fizer alterações de configuração para seu domínio, a lista de instâncias individuais nas guias Integridade do cluster e Integridade da instância geralmente duplicarão de tamanho por um breve período antes de retornar para o número correto. Para obter uma explicação sobre esse comportamento, consulte Fazendo alterações de configuração no Amazon OpenSearch Service.
Métricas de cluster
O Amazon OpenSearch Service fornece as seguintes métricas para clusters.
| Métrica | Description |
|---|---|
ClusterStatus.green |
Um valor 1 indica que todos os fragmentos de índice estão alocados a nós no cluster. Estatística relevante: máximo |
ClusterStatus.yellow |
Um valor 1 indica que os fragmentos principais de todos os índices estão alocados a nós no cluster, mas os fragmentos de réplica de pelo menos um índice não estão. Para saber mais, consulte Status de cluster amarelo. Estatística relevante: máximo |
ClusterStatus.red |
Um valor 1 indica que os fragmentos principais e de réplica de pelo menos um índice não estão alocados a nós no cluster. Para saber mais, consulte Status de cluster vermelho. Estatística relevante: máximo |
Shards.active |
O número total de fragmentos ativos primários e de réplica. Estatística relevante: máximo, soma |
Shards.unassigned |
O número de fragmentos que não estão alocados a nós no cluster. Estatística relevante: máximo, soma |
Shards.delayedUnassigned |
O número de fragmentos cuja alocação de nó foi atrasada pelas configurações de tempo limite. Estatística relevante: máximo, soma |
Shards.activePrimary |
O número de fragmentos primários ativos. Estatística relevante: máximo, soma |
Shards.initializing |
O número de fragmentos que estão em inicialização. Estatísticas relevantes: soma |
Shards.relocating |
O número de fragmentos que estão em relocação. Estatísticas relevantes: soma |
Nodes |
O número de nós no cluster OpenSearch de serviços, incluindo nós mestres dedicados e nós quentes. Para obter mais informações, consulte Fazendo alterações de configuração no Amazon OpenSearch Service. Estatística relevante: máximo |
SearchableDocuments |
O número total de documentos pesquisáveis em todos os nós de dados no cluster. Estatísticas relevantes: mínimo, máximo, média |
DeletedDocuments |
O número total de documentos marcados para exclusão em todos os nós de dados no cluster. Esses documentos não aparecem mais nos resultados da pesquisa, mas OpenSearch apenas removem documentos excluídos do disco durante a mesclagem de segmentos. Essa métrica aumenta após solicitações e diminuições de exclusão após fusões de segmento. Estatísticas relevantes: mínimo, máximo, média |
CPUUtilization |
A porcentagem de utilização da CPU para nós de dados no cluster. Maximum (Máximo) mostra o nó com a maior utilização da CPU. Average (Médio) representa todos os nós no cluster. Esta métrica também está disponível para nós individuais. Estatísticas relevantes: máximo, média |
FreeStorageSpace |
O espaço livre para nós de dados no cluster. O console OpenSearch de serviço exibe esse valor em GiB. O CloudWatch console da Amazon o exibe em MiB. nota
Estatísticas relevantes: mínima, máxima, média, soma |
ClusterUsedSpace |
O total de espaço usado para o cluster. Você deve deixar o período em um minuto para receber um valor preciso. O console OpenSearch de serviço exibe esse valor em GiB. O CloudWatch console da Amazon o exibe em MiB. Estatísticas relevantes: mínimo, máximo |
ClusterIndexWritesBlocked |
Indica se o cluster está aceitando ou bloqueando solicitações de gravação recebidas. Um valor de 0 significa que o cluster está aceitando solicitações. Um valor de 1 significa que ele está bloqueando solicitações. Alguns fatores comuns são: Estatística relevante: máximo |
JVMMemoryPressure |
A porcentagem máxima do heap Java usada para todos os nós de dados no cluster. OpenSearch O serviço usa metade da RAM de uma instância para o heap Java, até um tamanho de heap de 32 GiB. Você pode dimensionar instâncias verticalmente até 64 GiB de RAM, sendo que nesse ponto você poderá dimensionar horizontalmente adicionando instâncias. Consulte CloudWatch Alarmes recomendados para o Amazon Service OpenSearch. Estatística relevante: máximo notaA lógica dessa métrica foi alterada no software de serviço R20220323. Para saber mais, consulte as notas de lançamento. |
OldGenJVMMemoryPressure |
A porcentagem máxima do heap do Java usada para a “geração antiga” em todos os nós de dados no cluster. Essa métrica também está disponível a nível de nós. Estatística relevante: máximo |
AutomatedSnapshotFailure |
O número de snapshots automatizados com falha para o cluster. Um valor de Estatísticas relevantes: mínimo, máximo |
CPUCreditBalance |
Os créditos de CPU ainda disponíveis para nós de dados no cluster. Um crédito de CPU oferece a performance de um núcleo de CPU completo por um minuto. Para saber mais, consulte Créditos de CPU no Guia do desenvolvedor do Amazon EC2. Essa métrica está disponível somente para os tipos de instância T2 Estatísticas relevantes: mínimo |
OpenSearchDashboardsHealthyNodes |
Uma verificação de saúde para OpenSearch painéis. Se mínimo, máximo e média forem todos iguais a 1, o Dashboards está se comportando normalmente. Se você tiver 10 nós com máximo de 1, mínimo de 0 e média de 0,7, isso significa que 7 nós (70%) são íntegros e 3 nós (30%) não são íntegros. Estatísticas relevantes: mínimo, máximo, média |
OpensearchDashboardsReportingFailedRequestSysErrCount |
O número de solicitações para gerar relatórios de OpenSearch painéis que falharam devido a problemas no servidor ou limitações de recursos. Estatísticas relevantes: soma |
OpensearchDashboardsReportingFailedRequestUserErrCount |
O número de solicitações para gerar relatórios de OpenSearch painéis que falharam devido a problemas do cliente. Estatísticas relevantes: soma |
OpensearchDashboardsReportingRequestCount |
O número total de solicitações para gerar relatórios de OpenSearch painéis. Estatísticas relevantes: soma |
OpensearchDashboardsReportingSuccessCount |
O número de solicitações bem-sucedidas para gerar relatórios de OpenSearch painéis. Estatísticas relevantes: soma |
KMSKeyError |
Um valor de 1 indica que a AWS KMS chave usada para criptografar dados em repouso foi desativada. Para restaurar o domínio de operações normais, reabilite a chave. O console exibe essa métrica somente para domínios que criptografam dados em repouso. Estatísticas relevantes: mínimo, máximo |
KMSKeyInaccessible |
Um valor de 1 indica que a AWS KMS chave usada para criptografar dados em repouso foi excluída ou revogada em suas concessões ao OpenSearch Serviço. Você não pode recuperar os domínios que estejam nesse estado. Mas, se tiver um snapshot manual, você poderá usá-lo para migrar os dados do domínio para um novo domínio. O console exibe essa métrica somente para domínios que criptografam dados em repouso. Estatísticas relevantes: mínimo, máximo |
InvalidHostHeaderRequests |
O número de solicitações HTTP feitas ao OpenSearch cluster que incluíram um cabeçalho de host inválido (ou ausente). As solicitações válidas incluem o nome do host do domínio como valor do cabeçalho do host. OpenSearch O serviço rejeita solicitações inválidas de domínios de acesso público que não tenham uma política de acesso restritiva. Recomendamos aplicar uma política de acesso restritiva a todos os domínios. Se você visualizar grandes valores para esta métrica, confirme que os clientes do OpenSearch incluem o nome de host do domínio (e não, por exemplo, seu endereço IP) em suas solicitações. Estatísticas relevantes: soma |
OpenSearchRequests (previously
ElasticsearchRequests) |
O número de solicitações feitas ao OpenSearch cluster. Estatísticas relevantes: soma |
TLSNegotiationError |
O número de tentativas malsucedidas de handshake de TLS entre clientes e o endpoint do domínio. Essa métrica é incrementada quando um cliente tenta se conectar usando uma versão TLS ou conjunto de cifras não suportado. Estatísticas relevantes: soma |
2xx, 3xx, 4xx, 5xx |
O número de solicitações a um domínio que resultaram no determinado código de resposta HTTP (2xx, 3xx, 4xx, 5xx). Estatísticas relevantes: soma |
ThroughputThrottle |
Indica se os discos estão sob controle de utilização ou não. O controle de utilização ocorre quando o throughput combinado de Para obter informações sobre o throughput de instâncias, consulte Instâncias otimizadas para Amazon EBS. Para obter informações sobre o throughput de volume, consulte os tipos de volume do Amazon EBS Estatísticas relevantes: mínimo, máximo |
IopsThrottle |
Indica se o número de input/output operações por segundo (IOPS) no domínio foi reduzido ou não. O controle de utilização ocorre quando o IOPS do nó de dados viola o limite máximo permitido do volume do EBS ou da instância EC2 do nó de dados. Para obter informações sobre o IOPSS de instâncias, consulte Instâncias otimizadas para Amazon EBS. Para obter informações sobre o IOPS de volume, consulte os tipos de volume do Amazon EBS Estatísticas relevantes: mínimo, máximo |
HighSwapUsage |
Um valor 1 indica que a troca devido a falhas da página provavelmente causou picos no uso do disco subjacente durante um período específico. Estatística relevante: máximo |
Métricas de nó principal dedicado
O Amazon OpenSearch Service fornece as seguintes métricas para nós mestres dedicados.
| Métrica | Description |
|---|---|
MasterCPUUtilization |
A porcentagem máxima de recursos da CPU usados pelos nós principais dedicados. Recomendamos aumentar o tamanho do tipo de instância quando essa métrica atingir 60%. Estatística relevante: máximo |
MasterFreeStorageSpace |
Essa métrica não é relevante e pode ser ignorada. O serviço não usa nós principais como nós de dados. |
MasterJVMMemoryPressure |
A porcentagem máxima do heap Java usada para todos os nós principais dedicados no cluster. Recomendamos a mudança para um tipo de instância maior quando essa métrica atingir 85%. Estatística relevante: máximo notaA lógica dessa métrica foi alterada no software de serviço R20220323. Para saber mais, consulte as notas de lançamento. |
MasterOldGenJVMMemoryPressure |
A porcentagem máxima do heap do Java usada para a “geração antiga” por nó principal. Estatística relevante: máximo |
MasterCPUCreditBalance |
Os créditos de CPU ainda disponíveis para nós principais dedicados no cluster. Um crédito de CPU oferece a performance de um núcleo de CPU completo por um minuto. Para saber mais, consulte Créditos de CPU no Guia do desenvolvedor do Amazon EC2. Essa métrica está disponível somente para os tipos de instância T2 Estatísticas relevantes: mínimo |
MasterReachableFromNode |
Uma verificação de integridade exceções Falhas significam que o nó principal está inacessível a partir do nó de origem. Geralmente são o resultado de um problema de conectividade de rede ou de AWS dependência. Estatística relevante: máximo |
MasterSysMemoryUtilization |
O percentual de memória do nó principal que está em uso. Estatística relevante: máximo |
Métricas do nó Coordenador dedicado
O Amazon OpenSearch Service fornece as seguintes métricas para nós coordenadores dedicados.
| Métrica | Description |
|---|---|
CoordinatorCPUUtilization |
A porcentagem máxima de recursos da CPU usados pelos nós coordenadores dedicados. Recomendamos aumentar o tamanho do tipo de instância quando essa métrica atingir 80%. Estatística relevante: máximo |
CoordinatorJVMMemoryPressure |
A porcentagem máxima do heap Java usada para todos os nós coordenadores dedicados no cluster. Recomendamos a mudança para um tipo de instância maior quando essa métrica atingir 85%. Estatística relevante: máximo |
CoordinatorOldGenJVMMemoryPressure |
A porcentagem máxima do heap do Java usada para a “geração antiga” por nó principal. Estatística relevante: máximo |
CoordinatorSysMemoryUtilization |
A porcentagem de memória do nó coordenador que está em uso. Estatística relevante: máximo |
CoordinatorFreeStorageSpace |
Essa métrica indica que o serviço não usa nós coordenadores como nós de dados. |
Métricas de volume do EBS
O Amazon OpenSearch Service fornece as seguintes métricas para volumes do EBS.
| Métrica | Description |
|---|---|
ReadLatency |
A latência, em segundos, para operações de leitura em volumes do EBS. Esta métrica também está disponível para nós individuais. Estatísticas relevantes: mínimo, máximo, média |
WriteLatency |
A latência, em segundos, para operações de gravação em volumes do EBS. Esta métrica também está disponível para nós individuais. Estatísticas relevantes: mínimo, máximo, média |
ReadThroughput |
O throughput, em bytes por segundo, para operações de leitura em volumes do EBS. Esta métrica também está disponível para nós individuais. Estatísticas relevantes: mínimo, máximo, média |
ReadThroughputMicroBursting |
O throughput, em bytes por segundo, para operações de leitura em volumes do EBS quando a microintermitência Estatísticas relevantes: mínimo, máximo, média |
WriteThroughput |
O throughput, em bytes por segundo, para operações de gravação em volumes do EBS. Esta métrica também está disponível para nós individuais. Estatísticas relevantes: mínimo, máximo, média |
WriteThroughputMicroBursting |
O throughput, em bytes por segundo, para operações de gravação em volumes do EBS quando a microintermitência Estatísticas relevantes: mínimo, máximo, média |
DiskQueueDepth |
O número de solicitações pendentes de entrada e saída (I/O) para um volume do EBS. Estatísticas relevantes: mínimo, máximo, média |
ReadIOPS |
O número de operações de entrada e saída (I/O) por segundo para operações de leitura em volumes do EBS. Esta métrica também está disponível para nós individuais. Estatísticas relevantes: mínimo, máximo, média |
ReadIOPSMicroBursting |
O número de operações de entrada e saída (I/O) por segundo para operações de leitura em volumes do EBS quando o microbursting Estatísticas relevantes: mínimo, máximo, média |
WriteIOPS |
O número de operações de entrada e saída (I/O) por segundo para operações de gravação em volumes do EBS. Esta métrica também está disponível para nós individuais. Estatísticas relevantes: mínimo, máximo, média |
WriteIOPSMicroBursting |
O número de operações de entrada e saída (I/O) por segundo para operações de gravação em volumes do EBS quando o microbursting Estatísticas relevantes: mínimo, máximo, média |
BurstBalance |
A porcentagem de créditos de entrada e saída (I/O) restantes no balde de estouro para um volume do EBS. Um valor de 100 significa que o volume acumulou o número máximo de créditos. Se essa porcentagem cair abaixo de 70%, consulte O saldo de intermitência do EBS está baixo. O saldo intermitente permanece em 0 para domínios com tipos de volume gp3 e domínios com volume gp2 cujo tamanho de volume seja superior a 1000 GiB. Estatísticas relevantes: mínimo, máximo, média |
VolumeStalledIOcheck |
O status dos volumes do EBS para determinar quando eles estão danificados. A métrica é um valor binário que retorna um status 0 (aprovado) ou 1 (reprovado) dependendo do volume do EBS poder realizar as operações de entrada e saída. Estatísticas relevantes: mínimo, máximo, média |
Métricas de instância
O Amazon OpenSearch Service fornece as seguintes métricas para cada instância em um domínio. OpenSearch O serviço também agrega essas métricas de instância para fornecer informações sobre a integridade geral do cluster. Você pode verificar esse comportamento usando a estatística Contagem de amostras no console. Cada métrica na tabela a seguir tem estatísticas relevantes para o nó e o cluster.
Importante
Versões diferentes do Elasticsearch usam grupos de threads diferentes para processar chamadas para a API _index. As versões 1.5 e 2.3 do Elasticsearch usam o grupo de threads de índice. Elasticsearch 5. x, 6.0 e 6.2 usam o pool de threads em massa. OpenSearch e o Elasticsearch 6.3 e versões posteriores usam o pool de threads de gravação. Atualmente, o console OpenSearch de serviço não inclui um gráfico para o pool de threads em massa.
Use GET _cluster/settings?include_defaults=true para verificar o grupo de threads e os tamanhos de fila para seu cluster.
| Métrica | Description |
|---|---|
FetchLatency |
A diferença de tempo total, em milissegundos, obtida por todas as operações de busca de fragmento em um nó entre o minuto N e o minuto (N-1). Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máximo |
FetchRate |
O número total de operações de busca de fragmentos por minuto para todos os fragmentos em um nó de dados. Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máxima, soma |
ScrollTotal |
O número total de operações de rolagem de fragmentos por minuto para todos os fragmentos em um nó de dados. Estatísticas de nós relevantes: médio, máximo Estatísticas do cluster relevante: média, máxima, soma |
ScrollCurrent |
O número de operações de rolagem de fragmentos que estão em execução no momento. Estatísticas de nós relevantes: médio, máximo Estatísticas do cluster relevante: média, máxima, soma |
OpenContexts |
O número de contextos de pesquisa abertos. Estatísticas de nós relevantes: médio, máximo Estatísticas do cluster relevante: média, máxima, soma |
ThreadCount |
O número total de threads atualmente sendo utilizados pelo OpenSearch processo. Estatísticas de nós relevantes: médio, máximo Estatísticas do cluster relevante: média, máxima, soma |
ShardReactivateCount |
O número total de vezes que todos os fragmentos foram ativados a partir de um estado ocioso. Estatísticas do nó relevante: soma, máximo Estatísticas do cluster relevante: soma, máximo |
ConcurrentSearchRate |
O número total de solicitações de pesquisa usando a pesquisa simultânea de segmentos por minuto para todos os fragmentos em um nó de dados. Uma única chamada para a API Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máxima, soma |
ConcurrentSearchLatency |
A diferença no tempo total, em milissegundos, obtida por todas as pesquisas usando a pesquisa simultânea de segmentos em um nó entre minuto N e minuto ()N-1. Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máximo |
IndexingLatency |
A diferença no tempo total, em milissegundos, obtida por todas as operações de indexação em um nó entre o minuto N e o minuto ()N-1. Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máximo |
IndexingRate |
O número de operações de indexação por minuto. Uma única chamada para a API Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máxima, soma |
SearchLatency |
A diferença no tempo total, em milissegundos, obtida por todas as pesquisas em um nó entre o minuto N e o minuto (N-1). Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máximo |
SearchRate |
O número total de solicitações de pesquisa por minuto para todos os fragmentos em um nó de dados. Uma única chamada para a API Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máxima, soma |
SegmentCount |
O número de segmentos em um nó de dados. Quanto mais segmentos você tiver, maior será a duração de cada pesquisa. OpenSearch ocasionalmente mescla segmentos menores em um maior. Estatísticas de nós relevantes: máximo, média Estatísticas do cluster relevante: soma, máximo, média |
SysMemoryUtilization |
O percentual de memória da instância que está em uso. Valores altos para essa métrica são normais e geralmente não representam um problema com seu cluster. Para obter um melhor indicador de possíveis problemas de performance e estabilidade, consulte a métrica Estatísticas do nó relevante: mínimo, máximo, média Estatísticas relevantes de cluster: mínimo, máximo, média, soma |
JVMGCYoungCollectionCount |
O número de vezes que a coleta de lixo “nova geração” foi executada. Um grande número de execuções crescente é uma parte normal das operações do cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
JVMGCYoungCollectionTime |
A quantidade de tempo, em milissegundos, que o cluster gastou executando a coleta de lixo “nova geração”. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
JVMGCOldCollectionCount |
O número de vezes que a coleta de lixo “geração antiga” foi executada. Em um cluster com recursos suficientes, esse número deve permanecer pequeno e com crescimento com pouca frequência. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
JVMGCOldCollectionTime |
A quantidade de tempo, em milissegundos, que o cluster gastou executando a coleta de lixo “geração antiga”. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
OpenSearchDashboardsConcurrentConnections |
O número de conexões simultâneas ativas com os OpenSearch painéis. Se esse número continuar a crescer, considere escalar seu cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
OpenSearchDashboardsHealthyNode |
Uma verificação de saúde para o nó individual dos OpenSearch painéis. Um valor de 1 indica comportamento normal. Um valor de 0 indica que Dashboards está inacessível. Estatísticas do nó relevante: mínimo Estatísticas relevantes de cluster: mínimo, máximo, média, soma |
OpenSearchDashboardsHeapTotal |
A quantidade de memória de pilha alocada aos OpenSearch painéis em MiB. Diferentes tipos de instância do EC2 podem afetar a alocação exata de memória. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
OpenSearchDashboardsHeapUsed |
A quantidade absoluta de memória de pilha usada pelos OpenSearch painéis em MiB. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
OpenSearchDashboardsHeapUtilization |
A porcentagem máxima de memória de pilha disponível usada pelos OpenSearch painéis. Se esse valor aumentar acima de 80%, considere escalar seu cluster. Estatísticas do nó relevante: máximo Estatísticas relevantes de cluster: mínimo, máximo, média, soma |
OpenSearchDashboardsOS1MinuteLoad |
A média de carga de CPU de um minuto para OpenSearch painéis. A carga da CPU deve, idealmente, permanecer abaixo de 1,00. Embora picos temporários não sejam um problema, recomendamos aumentar o tamanho do tipo de instância se essa métrica estiver consistentemente acima de 1,00. Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máximo |
OpenSearchDashboardsRequestTotal |
A contagem total de solicitações HTTP feitas aos OpenSearch painéis. Se o sistema estiver lento ou você observar números elevados de solicitações de painéis, considere aumentar o tamanho do tipo de instância. Estatísticas de nós relevantes: soma Estatísticas do cluster relevante: soma |
OpenSearchDashboardsResponseTimesMaxInMillis |
O tempo máximo, em milissegundos, necessário para que os OpenSearch painéis respondam a uma solicitação. Se as solicitações demorarem consistentemente muito tempo para retornar resultados, considere aumentar o tamanho do tipo de instância. Estatísticas do nó relevante: máximo Estatísticas de cluster relevantes máximo, média |
SearchTaskCancelled |
O número de cancelamentos do nó coordenador. Estatísticas de nós relevantes: soma Estatísticas do cluster relevante: soma |
SearchShardTaskCancelled |
O número de cancelamentos de nós de dados. Estatísticas de nós relevantes: soma Estatísticas do cluster relevante: soma, |
ThreadpoolForce_mergeQueue |
O número de tarefas na fila no grupo de thread de união de força. Se o tamanho da fila é consistentemente alto, considere escalonar seu cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
ThreadpoolForce_mergeRejected |
O número de tarefas rejeitadas no grupo de thread de união de força. Se esse número continuar a crescer, considere escalonar seu cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma |
ThreadpoolForce_mergeThreads |
O tamanho do grupo de threads de união de força. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma |
ThreadpoolIndexQueue |
O número de tarefas na fila no grupo de thread de índice. Se o tamanho da fila é consistentemente alto, considere escalonar seu cluster. O tamanho máximo da fila de índice é de 200. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
ThreadpoolIndexRejected |
O número de tarefas rejeitadas no grupo de thread de índice. Se esse número continuar a crescer, considere escalonar seu cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma |
ThreadpoolIndexThreads |
O tamanho do grupo de threads de índice. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma |
ThreadpoolSearchQueue |
O número de tarefas na fila no grupo de thread de pesquisa. Se o tamanho da fila é consistentemente alto, considere escalonar seu cluster. O tamanho da fila de pesquisa máximo é 1.000. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
ThreadpoolSearchRejected |
O número de tarefas rejeitadas no grupo de thread de pesquisa. Se esse número continuar a crescer, considere escalonar seu cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma |
ThreadpoolSearchThreads |
O tamanho do grupo de threads de pesquisa. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma |
Threadpoolsql-workerQueue |
O número de tarefas na fila no grupo de threads de pesquisa SQL. Se o tamanho da fila é consistentemente alto, considere escalonar seu cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
Threadpoolsql-workerRejected |
O número de tarefas rejeitadas no grupo de threads de pesquisa SQL. Se esse número continuar a crescer, considere escalonar seu cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma |
Threadpoolsql-workerThreads |
O tamanho do grupo de threads de pesquisa SQL. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma |
ThreadpoolBulkQueue |
O número de tarefas na fila no grupo de thread em massa. Se o tamanho da fila é consistentemente alto, considere escalonar seu cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
ThreadpoolBulkRejected |
O número de tarefas rejeitadas no grupo de thread em massa. Se esse número continuar a crescer, considere escalonar seu cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma |
ThreadpoolBulkThreads |
O tamanho do grupo de threads em massa. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma |
ThreadpoolIndexSearcherQueue |
O número de tarefas na fila no grupo de threads de buscador de índice. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
ThreadpoolIndexSearcherRejected |
O número de tarefas rejeitadas no grupo de thread de buscador de índice. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma |
ThreadpoolIndexSearcherThreads |
O tamanho do grupo de threads de buscador de pesquisa. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma |
ThreadpoolWriteThreads |
O tamanho do grupo de threads de gravação. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma |
ThreadpoolWriteQueue |
O número de tarefas na fila no grupo de threads de gravação. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma |
ThreadpoolWriteRejected |
O número de tarefas rejeitadas no grupo de threads de gravação. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma notaComo o tamanho padrão da fila de gravação foi aumentado de 200 para 10000 na versão 7.1, essa métrica não é mais o único indicador de rejeições do Serviço. OpenSearch Use as métricas |
CoordinatingWriteRejected |
O número total de rejeições ocorreu no nó de coordenação devido à pressão de indexação desde a última inicialização do processo de OpenSearch serviço. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma Esta métrica está disponível na versão 7.1 e posteriores. |
PrimaryWriteRejected |
O número total de rejeições ocorreu nos fragmentos primários devido à pressão de indexação desde a última inicialização do processo de OpenSearch serviço. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma Esta métrica está disponível na versão 7.1 e posteriores. |
ReplicaWriteRejected |
O número total de rejeições ocorreu nos fragmentos de réplica devido à pressão de indexação desde a última OpenSearch inicialização do processo de serviço. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma Esta métrica está disponível na versão 7.1 e posteriores. |
WorkloadManagementEnabled |
Indica se o atributo de gerenciamento da workload está habilitado. Um valor de 1 significa que está habilitado e um valor de 0 significa que está Estatísticas do nó relevante: máximo, mínimo Estatísticas do cluster relevante: média, soma Esta métrica está disponível na versão 7.1 e posteriores. |
SoftQueryGroupCount |
Número de grupos de consulta no modo flexível no domínio. Estatísticas de nós relevantes: médio, máximo Estatísticas do cluster relevante: média, máxima, soma Esta métrica está disponível na versão 7.1 e posteriores. |
EnforcedQueryGroupCount |
Número de grupos de consulta no modo imposto no domínio. Estatísticas de nós relevantes: médio, máximo Estatísticas do cluster relevante: média, máxima, soma Esta métrica está disponível na versão 7.1 e posteriores. |
Métricas quentes
O Amazon OpenSearch Service fornece as seguintes métricas para arquitetura Multi-tier de armazenamento e UltraWarm
nota
As métricas relacionadas à indexação quente são aplicáveis somente à arquitetura de Multi-tier armazenamento
| Métrica | Description |
|---|---|
WarmIndexingLatency
|
A diferença no tempo total, em milissegundos, obtida por todas as operações de indexação em um nó quente entre o minuto N e o minuto ()N-1. Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máximo |
WarmIndexingRate
|
O número de operações de indexação em aquecimento por minuto. Uma única chamada para a API Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máxima, soma |
WarmThreadpoolIndexingQueue
|
O número de tarefas na fila no grupo de thread de índice. Se o tamanho da fila é consistentemente alto, considere escalonar seu cluster. O tamanho máximo da fila de índice é de 200. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, máxima, soma |
WarmThreadpoolIndexingRejected
|
O número de tarefas rejeitadas no grupo de thread de índice. Se esse número continuar a crescer, considere escalonar seu cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma |
WarmThreadpoolIndexingThreads
|
O tamanho do grupo de threads de índice. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma |
WarmCPUUtilization |
A porcentagem de uso da CPU para nós quentes no cluster. Maximum (Máximo) mostra o nó com a maior utilização da CPU. A média representa todos os nós quentes no cluster. Essa métrica também está disponível para nós Warm individuais. Estatísticas relevantes: máximo, média |
WarmFreeStorageSpace |
A quantidade de espaço de armazenamento de alta atividade livre em MiB. Como o Warm usa o Amazon S3 em vez de discos conectados, essa Estatísticas relevantes: soma |
WarmSearchableDocuments |
O número total de documentos pesquisáveis em todos os índices warm no cluster. Você deve deixar o período em um minuto para receber um valor preciso. Estatísticas relevantes: soma |
WarmSearchLatency
|
A diferença no tempo total, em milissegundos, obtida por todas as pesquisas em um Warm entre o minuto N e o minuto (N-1). Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máximo |
WarmSearchRate
|
O número total de solicitações de pesquisa por minuto para todos os fragmentos em um nó Warm. Uma única chamada para a API Estatísticas do nó relevante: média Estatísticas do cluster relevante: média, máxima, soma |
WarmStorageSpaceUtilization |
A quantidade total de espaço de armazenamento de alta atividade, em MiB, que o cluster está usando. Estatística relevante: máximo |
HotStorageSpaceUtilization
|
A quantidade total de espaço de armazenamento de atividade muito alta que o cluster está usando. Estatística relevante: máximo |
WarmSysMemoryUtilization |
A porcentagem de memória do nó de alta atividade que está em uso. Estatística relevante: máximo |
HotToWarmMigrationQueueSize
|
O número de índices aguardando no momento para a migração do armazenamento quente para o armazenamento warm. Estatística relevante: máximo |
WarmToHotMigrationQueueSize
|
O número de índices aguardando no momento para a migração do armazenamento warm para o armazenamento quente. Estatística relevante: máximo |
HotToWarmMigrationFailureCount
|
O número total de migrações de atividade muito alta para alta atividade que falharam. Essa métrica está disponível somente para UltraWarm nós. Estatísticas relevantes: soma |
HotToWarmMigrationForceMergeLatency
|
A latência média da etapa de forçar mesclagem do processo de migração. Se esse estágio sempre demorar muito, considere aumentar. Essa métrica está disponível somente para UltraWarm nós. Estatística relevante: média |
HotToWarmMigrationSnapshotLatency
|
A latência média da etapa de snapshot do processo de migração. Se esse estágio demorar muito de forma consistente, certifique-se de que os fragmentos estejam adequadamente dimensionados e distribuídos por todo o cluster. Essa métrica está disponível somente para UltraWarm nós. Estatística relevante: média |
HotToWarmMigrationProcessingLatency
|
A latência média de migrações de atividade muito alta para alta atividade bem-sucedidas, nãoincluindo tempo gasto na fila. Esse valor é a soma do tempo necessário para concluir os estágios de forçar mesclagem, snapshot e realocação de fragmentos do processo de migração. Essa métrica está disponível somente para UltraWarm nós. Estatística relevante: média |
HotToWarmMigrationSuccessCount
|
O número total de migrações de atividade muito alta para alta atividade bem-sucedidas. Estatísticas relevantes: soma |
HotToWarmMigrationSuccessLatency
|
A latência média de migrações de atividade muito alta para alta atividade bem-sucedidas, incluindo tempo gasto na fila. Estatística relevante: média |
WarmThreadpoolSearchThreads |
O tamanho do pool de tópicos de pesquisa do Warm. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: média, soma |
WarmThreadpoolSearchRejected |
O número de tarefas rejeitadas no pool de tópicos de pesquisa do Warm. Se esse número aumentar continuamente, considere adicionar mais nós quentes. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma |
WarmThreadpoolSearchQueue |
O número de tarefas em fila no pool de tópicos de pesquisa do Warm. Se o tamanho da fila for consistentemente alto, considere adicionar mais nós quentes. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
WarmJVMMemoryPressure |
A porcentagem máxima do heap Java usada para os nós Warm. Estatística relevante: máximo notaA lógica dessa métrica foi alterada no software de serviço R20220323. Para saber mais, consulte as notas de lançamento. |
WarmOldGenJVMMemoryPressure |
A porcentagem máxima do heap Java usada para a “geração antiga” por nó Warm. Estatística relevante: máximo |
WarmJVMGCYoungCollectionCount |
O número de vezes que a coleta de lixo da “geração jovem” foi executada em nós Warm. Um grande número de execuções crescente é uma parte normal das operações do cluster. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
WarmJVMGCYoungCollectionTime |
A quantidade de tempo, em milissegundos, que o cluster gastou realizando a coleta de lixo da “geração jovem” nos nós do Warm. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
WarmJVMGCOldCollectionCount |
O número de vezes que a coleta de lixo da “velha geração” foi executada em nós Warm. Em um cluster com recursos suficientes, esse número deve permanecer pequeno e com crescimento com pouca frequência. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
WarmConcurrentSearchRate |
O número total de solicitações de pesquisa usando a pesquisa simultânea por segmento por minuto para todos os fragmentos em um nó Warm. Uma única chamada para a API Estatísticas do nó relevante: média Estatísticas do cluster relevante: soma, máximo, média |
WarmConcurrentSearchLatency |
A diferença no tempo total, em milissegundos, obtida por todas as pesquisas usando a pesquisa simultânea de segmentos em um nó quente entre o minuto N e o minuto ()N-1. Estatísticas do nó relevante: média Estatísticas de cluster relevantes máximo, média |
WarmThreadpoolIndexSearcherQueue |
O número de tarefas em fila no pool de threads do Warm index searcher. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, máximo, média |
WarmThreadpoolIndexSearcherRejected |
O número de tarefas rejeitadas no pool de tópicos do Warm index searcher. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma |
WarmThreadpoolIndexSearcherThreads |
O tamanho do pool de tópicos do Warm Index Searcher. Estatísticas do nó relevante: máximo Estatísticas do cluster relevante: soma, média |
Métricas de armazenamento de baixa atividade
O Amazon OpenSearch Service fornece as seguintes métricas para armazenamento a frio.
| Métrica | Description |
|---|---|
ColdStorageSpaceUtilization
|
A quantidade total de espaço de armazenamento de baixa atividade, em MiB, que o cluster está usando. Estatísticas relevantes: máx. |
ColdToWarmMigrationFailureCount |
O número total de migrações de baixa atividade para alta atividade que falharam. Estatísticas relevantes: soma |
ColdToWarmMigrationLatency |
A quantidade de tempo necessária para que as migrações de baixa atividade para alta atividade sejam concluídas. Estatística relevante: média |
ColdToWarmMigrationQueueSize |
O número de índices aguardando no momento para a migração do armazenamento frio para o armazenamento warm. Estatística relevante: máximo |
ColdToWarmMigrationSuccessCount
|
O número total de migrações de baixa atividade para alta atividade bem-sucedidas. Estatísticas relevantes: soma |
WarmToColdMigrationFailureCount
|
O número total de migrações de alta atividade para baixa atividade que falharam. Estatísticas relevantes: soma |
WarmToColdMigrationLatency |
A quantidade de tempo necessária para que as migrações de alta atividade para baixa atividade sejam concluídas. Estatística relevante: média |
WarmToColdMigrationQueueSize |
O número de índices aguardando atualmente para migrar do armazenamento warm para o armazenamento frio. Estatística relevante: máximo |
WarmToColdMigrationSuccessCount |
O número total de migrações de alta atividade para baixa atividade bem-sucedidas. Estatísticas relevantes: soma |
OpenSearch Métricas de instâncias otimizadas (OR1)
O Amazon OpenSearch Service fornece as seguintes métricas para instâncias OR1.
| Métrica | Description |
|---|---|
RemoteStorageUsedSpace
|
A quantidade total de espaço do Amazon S3, em MiB, que o cluster está usando. Estatísticas relevantes: soma |
RemoteStorageWriteRejected |
O número total de solicitações rejeitadas nos fragmentos primários devido à pressão de armazenamento e replicação remotos. Isso é calculado a partir da última inicialização do processo de OpenSearch serviço. Estatísticas relevantes: soma |
ReplicationLagMaxTime |
A quantidade de tempo, em milissegundos, que os fragmentos de réplica ficam atrasados em relação aos fragmentos primários. Estatística relevante: máximo |
Métricas otimizadas do motor
O Amazon OpenSearch Service fornece as seguintes métricas para domínios que executam o mecanismo otimizado (análise de log). Para obter mais informações, consulte Otimizado para análise de registros.
| Métrica | Description |
|---|---|
NativeMemoryPressure |
A porcentagem de memória nativa (fora da pilha) em uso no nó. Essa métrica é análoga Estatística relevante: máximo |
NativeRuntimeResidentMemory |
A quantidade de memória residente, em bytes, consumida pelo mecanismo de análise nativo no nó. Aplicável aos nós quente, quente e coordenador. Estatísticas relevantes: máximo, média |
NativeSearchRuntimeCPUUtilization |
A utilização da CPU, como porcentagem, do mecanismo de execução de DataFusion consultas no nó. Aplicável aos nós quente, quente e coordenador. Estatísticas relevantes: máximo, média |
ThreadpoolNativeSearchCPUQueue |
O número de tarefas em fila no pool de threads da CPU de pesquisa nativa. Se o tamanho da fila é consistentemente alto, considere escalonar seu cluster. Aplicável aos nós quente, quente e coordenador. Estatística relevante: máximo |
ThreadpoolNativeSearchCPUThreads |
O tamanho do pool de threads da CPU de pesquisa nativa. Aplicável aos nós quente, quente e coordenador. Estatística relevante: máximo |
nota
As métricas a seguir não se aplicam aos domínios otimizados porque os OpenSearch painéis não estão disponíveis:
OpenSearchDashboardsHealthyNodesOpensearchDashboardsReportingFailedRequestSysErrCountOpensearchDashboardsReportingFailedRequestUserErrCountOpensearchDashboardsReportingRequestCountOpensearchDashboardsReportingSuccessCount
Métricas de alerta
O Amazon OpenSearch Service fornece as seguintes métricas para alertas.
| Métrica | Description |
|---|---|
AlertingDegraded |
Um valor de 1 significa que o índice de alerta é vermelho ou um ou mais nós não estão na programação. Um valor de 0 indica comportamento normal. Estatística relevante: máximo |
AlertingIndexExists |
Um valor de 1 significa que o índice Estatística relevante: máximo |
AlertingIndexStatus.green |
A integridade do índice. Um valor de 1 significa verde. Um valor de 0 significa que o índice não existe ou não está verde. Estatística relevante: máximo |
AlertingIndexStatus.red |
A integridade do índice. Um valor de 1 significa vermelho. Um valor de 0 significa que o índice não existe ou não está vermelho. Estatística relevante: máximo |
AlertingIndexStatus.yellow |
A integridade do índice. Um valor de 1 significa amarelo. Um valor de 0 significa que o índice não existe ou não está amarelo. Estatística relevante: máximo |
AlertingNodesNotOnSchedule |
Um valor de 1 significa que alguns trabalhos não estão sendo executados de acordo com a programação. Um valor de 0 significa que todos os trabalhos de alerta estão sendo executados de acordo com a programação (ou que não existem trabalhos de alerta). Verifique o console OpenSearch de serviços ou faça uma Estatística relevante: máximo |
AlertingNodesOnSchedule |
Um valor de 1 significa que todos os trabalhos de alerta estão em execução de acordo com a programação (ou que não existem trabalhos de alerta). Um valor de 0 significa que alguns trabalhos não estão sendo executados de acordo com a programação. Estatística relevante: máximo |
AlertingScheduledJobEnabled |
Um valor de 1 significa que a configuração do cluster Estatística relevante: máximo |
Métricas de detecção de anomalias
O Amazon OpenSearch Service fornece as seguintes métricas para detecção de anomalias.
| Métrica | Description |
|---|---|
ADPluginUnhealthy |
Um valor de 1 significa que o plug-in de detecção de anomalias não está funcionando corretamente, seja por causa de um alto número de falhas, seja porque um dos índices que ele usa é vermelho. Um valor de 0 indica que o plug-in está funcionando conforme esperado. Estatística relevante: máximo |
ADExecuteRequestCount |
O número de solicitações para detectar anomalias. Estatísticas relevantes: soma |
ADExecuteFailureCount
|
O número de solicitações com falha para detecção de anomalias. Estatísticas relevantes: soma |
ADHCExecuteFailureCount |
O número de solicitações de detecção de anomalias para detectores de alta cardinalidade que falharam. Estatísticas relevantes: soma |
ADHCExecuteRequestCount |
O número de solicitações de detecção de anomalias para detectores de alta cardinalidade. Estatísticas relevantes: soma |
ADAnomalyResultsIndexStatusIndexExists |
Um valor de 1 significa que o índice para o qual o alias Estatística relevante: máximo |
ADAnomalyResultsIndexStatus.red |
Um valor de 1 significa que o índice para o qual o alias Estatística relevante: máximo |
ADAnomalyDetectorsIndexStatusIndexExists |
Um valor de 1 significa que o índice Estatística relevante: máximo |
ADAnomalyDetectorsIndexStatus.red |
Um valor de 1 significa que o índice Estatística relevante: máximo |
ADModelsCheckpointIndexStatusIndexExists |
Um valor de 1 significa que o índice Estatística relevante: máximo |
ADModelsCheckpointIndexStatus.red |
Um valor de 1 significa que o índice Estatística relevante: máximo |
Métricas de pesquisa assíncrona
O Amazon OpenSearch Service fornece as seguintes métricas para pesquisa assíncrona.
Estatísticas de nó coordenador de pesquisa assíncrona (por nó coordenador)
| Métrica | Description |
|---|---|
AsynchronousSearchSubmissionRate |
O número de pesquisas assíncronas enviadas no último minuto. |
AsynchronousSearchInitializedRate |
O número de pesquisas assíncronas inicializadas no último minuto. |
AsynchronousSearchRunningCurrent |
O número de pesquisas assíncronas atualmente em execução. |
AsynchronousSearchCompletionRate |
O número de pesquisas assíncronas concluídas com êxito no último minuto. |
AsynchronousSearchFailureRate |
O número de pesquisas assíncronas que foram concluídas e falharam no último minuto. |
AsynchronousSearchPersistRate |
O número de pesquisas assíncronas que persistiram no último minuto. |
AsynchronousSearchPersistFailedRate |
O número de pesquisas assíncronas que falharam ao persistir no último minuto. |
AsynchronousSearchRejected |
O número total de pesquisas assíncronas rejeitadas desde o momento de ativação do nó. |
AsynchronousSearchCancelled |
O número total de pesquisas assíncronas canceladas desde o momento de ativação do nó. |
AsynchronousSearchMaxRunningTime |
A duração da pesquisa assíncrona de execução mais longa em um nó no último minuto. |
Estatísticas de cluster de pesquisa assíncrona
| Métrica | Description |
|---|---|
AsynchronousSearchStoreHealth |
A integridade da loja no índice persistente (RED/non-RED) no último minuto. |
AsynchronousSearchStoreSize |
O tamanho do índice do sistema em todos os fragmentos no último minuto. |
AsynchronousSearchStoredResponseCount |
O número de respostas armazenadas no índice do sistema no último minuto. |
Auto-Tune métricas
O Amazon OpenSearch Service fornece as seguintes métricas para Auto-Tune.
| Métrica | Description |
|---|---|
AutoTuneChangesHistoryHeapSize |
O histórico de alterações em MiB para valores de ajuste do tamanho da pilha. |
AutoTuneChangesHistoryJVMYoungGenArgs |
O histórico de alterações dos argumentos da JVM. YongGen |
AutoTuneFailed |
Um booleano que indica se a Auto-Tune alteração falhou. |
AutoTuneSucceeded |
Um booleano que indica se a Auto-Tune alteração foi bem-sucedida. |
AutoTuneValue |
O histórico de alterações da fila (contagem) e o histórico de alterações dos ajustes do cache (em MiB) para alterações sem interrupções. |
Multi-AZ com métricas de espera
O Amazon OpenSearch Service fornece as seguintes métricas para o modo Multi-AZ de espera.
Node-level métricas para nós de dados em zonas de disponibilidade ativas
| Métrica | Description |
|---|---|
CPUUtilization |
A porcentagem de utilização da CPU para nós de dados no cluster. Maximum (Máximo) mostra o nó com a maior utilização da CPU. Average (Médio) representa todos os nós no cluster. Esta métrica também está disponível para nós individuais. |
FreeStorageSpace |
O espaço livre para nós de dados no cluster. O console OpenSearch de serviço exibe esse valor em GiB. O CloudWatch console da Amazon o exibe em MiB. |
JVMMemoryPressure |
A porcentagem máxima do heap Java usada para todos os nós de dados no cluster. OpenSearch O serviço usa metade da RAM de uma instância para o heap Java, até um tamanho de heap de 32 GiB. Você pode dimensionar instâncias verticalmente até 64 GiB de RAM, sendo que nesse ponto você poderá dimensionar horizontalmente adicionando instâncias. Consulte CloudWatch Alarmes recomendados para o Amazon Service OpenSearch. |
SysMemoryUtilization |
O percentual de memória da instância que está em uso. Valores altos para essa métrica são normais e geralmente não representam um problema com seu cluster. Para obter um melhor indicador de possíveis problemas de performance e estabilidade, consulte a métrica JVMMemoryPressure. |
IndexingLatency |
A diferença no tempo total, em milissegundos, obtida por todas as operações de indexação em um nó entre o minuto N e o minuto ()N-1. |
IndexingRate |
O número de operações de indexação por minuto. |
SearchLatency |
A diferença no tempo total, em milissegundos, obtida por todas as pesquisas em um nó entre o minuto N e o minuto (N-1). |
SearchRate |
O número total de solicitações de pesquisa por minuto para todos os fragmentos em um nó de dados. |
ThreadpoolSearchQueue |
O número de tarefas na fila no grupo de thread de pesquisa. Se o tamanho da fila é consistentemente alto, considere escalonar seu cluster. O tamanho da fila de pesquisa máximo é 1.000. |
ThreadpoolWriteQueue |
O número de tarefas na fila no grupo de threads de gravação. |
ThreadpoolSearchRejected |
O número de tarefas rejeitadas no grupo de thread de pesquisa. Se esse número continuar a crescer, considere escalonar seu cluster. |
ThreadpoolWriteRejected |
O número de tarefas rejeitadas no grupo de threads de gravação. |
Cluster-level métricas para clusters em zonas de disponibilidade ativas
| Métrica | Description |
|---|---|
DataNodes |
O número total de fragmentos ativos e em espera. |
DataNodesShards.active |
O número total de fragmentos ativos primários e de réplica. |
DataNodesShards.unassigned |
O número de fragmentos que não estão alocados a nós no cluster. |
DataNodesShards.initializing |
O número de fragmentos que estão em inicialização. |
DataNodesShards.relocating |
O número de fragmentos que estão em relocação. |
Métricas de alternação da zona de disponibilidade
Se ActiveReads., então a zona está ativa. Se Availability-Zone = 1ActiveReads., então a zona está em modo de espera.Availability-Zone =
0
Métricas pontuais
O Amazon OpenSearch Service fornece as seguintes métricas para pesquisas pontuais (PIT).
Estatísticas de nó coordenador de PIT (por nó coordenador)
| Métrica | Description |
|---|---|
CurrentPointInTime |
O número de contextos de pesquisa PIT ativos no nó. |
TotalPointInTime |
O número de contextos de pesquisa de PIT expirados desde o momento de ativação do nó. |
AvgPointInTimeAliveTime |
A média de manutenção ativa dos contextos de pesquisa de PIT desde o momento de ativação do nó. |
HasActivePointInTime |
Um valor de 1 indica que há contextos PIT ativos nos nós desde o tempo de atividade do nó. Um valor de zero significa que não há. |
HasUsedPointInTime |
Um valor de 1 indica que há contextos PIT expirados nos nós desde o tempo de atividade do nó. Um valor de zero significa que não há. |
Métricas de SQL
O Amazon OpenSearch Service fornece as seguintes métricas para suporte a SQL.
| Métrica | Description |
|---|---|
SQLFailedRequestCountByCusErr |
O número de solicitações com falha para a API Estatísticas relevantes: soma |
SQLFailedRequestCountBySysErr |
O número de solicitações com falha para a API Estatísticas relevantes: soma |
SQLRequestCount |
O número de solicitações para a API Estatísticas relevantes: soma |
SQLDefaultCursorRequestCount |
Semelhante a Estatísticas relevantes: soma |
SQLUnhealthy |
Um valor de 1 indica que, em resposta a determinadas solicitações, o plug-in do SQL está retornando códigos de resposta 5xx ou passando DSL de consulta inválida para o OpenSearch. Outras solicitações devem continuar a ter êxito. Um valor de 0 indica que não há falhas recentes. Se você vir um valor sustentado de 1, solucione o problema das solicitações que seus clientes estão fazendo ao plug-in. Estatística relevante: máximo |
Métricas de k-NN
O Amazon OpenSearch Service inclui as seguintes métricas para o plug-in k-near neighbor (k-NN).
| Métrica | Description |
|---|---|
KNNCacheCapacityReached |
Per-node métrica para saber se a capacidade do cache foi atingida. Essa métrica só é relevante para pesquisas k-NN aproximadas. Estatística relevante: máximo |
KNNCircuitBreakerTriggered |
Per-cluster métrica para saber se o disjuntor é acionado. Se algum nó retornar um valor 1 para Estatística relevante: máximo |
KNNEvictionCount |
Per-node métrica para o número de gráficos que foram removidos do cache devido a restrições de memória ou tempo ocioso. Remoções explícitas que ocorrem devido à exclusão do índice não são contadas. Essa métrica só é relevante para pesquisas k-NN aproximadas. Estatísticas relevantes: soma |
KNNGraphIndexErrors |
Per-node métrica para o número de solicitações para adicionar o Estatísticas relevantes: soma |
KNNGraphIndexRequests |
Per-node métrica para o número de solicitações para adicionar o Estatísticas relevantes: soma |
KNNGraphMemoryUsage |
Per-node métrica para o tamanho atual do cache (tamanho total de todos os gráficos na memória) em kilobytes. Essa métrica só é relevante para pesquisas k-NN aproximadas. Estatística relevante: média |
KNNGraphMemoryUsagePercentage |
Per-node métrica para a porcentagem de memória nativa usada para gráficos k-NN em relação ao limite do disjuntor (). Estatística relevante: máximo |
KNNGraphQueryErrors |
Per-node métrica para o número de consultas gráficas que produziram um erro. Estatísticas relevantes: soma |
KNNGraphQueryRequests |
Per-node métrica para o número de consultas gráficas. Estatísticas relevantes: soma |
KNNHitCount |
Per-node métrica para o número de acessos ao cache. Um acerto de cache ocorre quando um usuário consulta um gráfico que já está carregado na memória. Essa métrica só é relevante para pesquisas k-NN aproximadas. Estatísticas relevantes: soma |
KNNLoadExceptionCount |
Per-node métrica para o número de vezes que uma exceção ocorreu ao tentar carregar um gráfico no cache. Essa métrica só é relevante para pesquisas k-NN aproximadas. Estatísticas relevantes: soma |
KNNLoadSuccessCount |
Per-node métrica para o número de vezes que o plug-in carregou com sucesso um gráfico no cache. Essa métrica só é relevante para pesquisas k-NN aproximadas. Estatísticas relevantes: soma |
KNNMissCount |
Per-node métrica para o número de perdas de cache. Uma perda de cache ocorre quando um usuário consulta um gráfico que ainda não está carregado na memória. Essa métrica só é relevante para pesquisas k-NN aproximadas. Estatísticas relevantes: soma |
KNNQueryRequests |
Per-node métrica para o número de solicitações de consulta que o plug-in k-NN recebeu. Estatísticas relevantes: soma |
KNNRemoteBuildEnabled |
Valor binário que especifica se o recurso está ativado. Estatísticas relevantes: Binário |
KNNRemoteIndexBuildFailureCount |
Número total de falhas de compilação. Estatísticas relevantes: soma |
KNNRemoteIndexBuildSuccessCount |
Número total de construções bem-sucedidas. Estatísticas relevantes: soma |
KNNScriptCompilationErrors |
Per-node métrica para o número de erros durante a compilação do script. Essa estatística só é relevante para a pesquisa de scripts de pontuação k-NN. Estatísticas relevantes: soma |
KNNScriptCompilations |
Per-node métrica para o número de vezes que o script k-NN foi compilado. Esse valor normalmente deve ser 1 ou 0, mas se o cache que contém os scripts compilados estiver preenchido, o script k-NN poderá ser recompilado. Essa estatística só é relevante para a pesquisa de scripts de pontuação k-NN. Estatísticas relevantes: soma |
KNNScriptQueryErrors |
Per-node métrica para o número de erros durante consultas de script. Essa estatística só é relevante para a pesquisa de scripts de pontuação k-NN. Estatísticas relevantes: soma |
KNNScriptQueryRequests |
Per-node métrica para o número total de consultas de script. Essa estatística só é relevante para a pesquisa de scripts de pontuação k-NN. Estatísticas relevantes: soma |
KNNTotalLoadTime |
O tempo em nanossegundos que o algoritmo k-NN demorou para carregar gráficos no cache. Essa métrica só é relevante para pesquisas k-NN aproximadas. Estatísticas relevantes: soma |
VectorIndexBuildAccelerationOCU |
O número de unidades de OpenSearch computação (OCUs) usadas para acelerar a indexação vetorial. Estatísticas relevantes: soma |
Cross-cluster métricas de pesquisa
O Amazon OpenSearch Service fornece as seguintes métricas para pesquisa entre clusters.
Métricas de domínio de origem
| Métrica | Dimensão | Description |
|---|---|---|
CrossClusterOutboundConnections |
|
Número de nós conectados. Se sua resposta incluir um ou mais domínios ignorados, use essa métrica para rastrear quaisquer conexões não íntegras. Se esse número cair para 0, a conexão não estará íntegra. |
CrossClusterOutboundRequests |
|
Número de solicitações de pesquisa enviadas para o domínio de destino. Use para verificar se a carga de solicitações de pesquisa entre clusters está sobrecarregando seu domínio, correlacione qualquer pico nessa métrica com qualquer pico. JVM/CPU |
Métrica de domínio de destino
| Métrica | Dimensão | Description |
|---|---|---|
CrossClusterInboundRequests |
|
Número de solicitações de conexão de entrada recebidas do domínio de origem. |
Adicione um CloudWatch alarme no caso de você perder uma conexão inesperadamente. Para ver as etapas para criar um alarme, consulte Criar um CloudWatch alarme com base em um limite estático.
Cross-cluster métricas de replicação
O Amazon OpenSearch Service fornece as seguintes métricas para replicação entre clusters.
| Métrica | Description |
|---|---|
ReplicationRate |
A taxa média de operações de replicação por segundo. Essa métrica é semelhante à métrica do |
LeaderCheckPoint |
Para uma conexão específica, a soma dos valores do ponto de verificação líder em todos os índices de replicação. Você pode usar essa métrica para medir a latência de replicação. |
FollowerCheckPoint |
Para uma conexão específica, a soma dos valores do ponto de verificação seguidor em todos os índices de replicação. Você pode usar essa métrica para medir a latência de replicação. |
ReplicationNumSyncingIndices |
O número de índices que têm um status de replicação de |
ReplicationNumBootstrappingIndices |
O número de índices que têm um status de replicação de |
ReplicationNumPausedIndices |
O número de índices que têm um status de replicação de |
ReplicationNumFailedIndices |
O número de índices que têm um status de replicação de |
|
|
O número de solicitações de transporte de replicação no domínio seguidor. Solicitações de transporte são internas e ocorrem sempre que uma operação de API de replicação é chamada. Também ocorrem quando as pesquisas do domínio do seguidor mudam do domínio líder. |
|
|
O número de solicitações de transporte de replicação no domínio líder. Solicitações de transporte são internas e ocorrem sempre que uma operação de API de replicação é chamada. |
AutoFollowNumSuccessStartReplication |
O número de índices seguidores que foram criados com êxito por uma regra de replicação para uma conexão específica. |
AutoFollowNumFailedStartReplication |
O número de índices seguidores que falharam ao serem criados por uma regra de replicação quando havia um padrão de correspondência. Esse problema pode surgir devido a um problema de rede no cluster remoto ou devido a um problema de segurança (ou seja, a função associada não tem permissão para iniciar a replicação). |
AutoFollowLeaderCallFailure |
Se houve alguma consulta com falha entre o índice seguidor e o índice líder para extrair novos dados. Um valor de |
Métricas de Learning to Rank
O Amazon OpenSearch Service fornece as seguintes métricas para Learning to Rank.
| Métrica | Description |
|---|---|
LTRRequestTotalCount |
Contagem total de solicitações de classificação. |
LTRRequestErrorCount |
Contagem total de solicitações malsucedidas. |
LTRStatus.red |
Rastreia se um dos índices necessários para executar o plug-in é vermelho. |
LTRMemoryUsage |
Memória total usada pelo plug-in. |
LTRFeatureMemoryUsageInBytes |
A quantidade de memória, em bytes, usada pelos campos de recursos do Learning to Rank. |
LTRFeaturesetMemoryUsageInBytes |
A quantidade de memória, em bytes, usada por todos os conjuntos de recursos do Learning to Rank. |
LTRModelMemoryUsageInBytes |
A quantidade de memória, em bytes, usada por todos os modelos do Learning to Rank. |
Métricas da Piped Processing Language
O Amazon OpenSearch Service fornece as seguintes métricas para a linguagem de processamento canalizada.
| Métrica | Description |
|---|---|
PPLFailedRequestCountByCusErr |
O número de solicitações com falha para a API |
PPLFailedRequestCountBySysErr |
O número de solicitações com falha para a API |
PPLRequestCount |
O número de solicitações para a API |
