As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Tutorial: Visualizando chamadas de suporte ao cliente com OpenSearch serviços e painéis OpenSearch
Este capítulo é uma descrição completa da seguinte situação: uma empresa recebe um determinado número de chamadas de suporte ao cliente e quer analisá-las. O que é o assunto de cada chamada? Quantas eram positivas? Quantas eram negativas? Como os gerentes podem pesquisar ou revisar as transcrições dessas chamadas?
Um fluxo de trabalho manual pode envolver funcionários ouvindo gravações, anotando o assunto de cada chamada e decidindo se a interação do cliente foi positiva.
Esse processo seria extremamente trabalhoso. Supondo um tempo médio de 10 minutos por chamada, cada funcionário escutaria apenas 48 chamadas por dia. Independentemente do viés humano, os dados que eles geram seriam altamente precisos, mas a quantidade de dados seria mínima: apenas o assunto da chamada e um booliano para saber se o cliente estava ou não satisfeito. Qualquer coisa mais complexa, como uma transcrição completa, tomaria uma quantidade imensa de tempo.
Usando o Amazon S3
Embora você possa usar esse passo a passo no estado em que se encontra, a intenção é gerar ideias sobre como enriquecer seus documentos JSON antes de indexá-los no Service. OpenSearch
Custos estimados
Em geral, executar as etapas desta demonstração devem custar menos de US$ 2. A demonstração usa os seguintes recursos:
-
Bucket do S3 com menos de 100 MB transferidos e armazenados
Para saber mais, consulte Definição de preços do Amazon S3
. -
OpenSearch Domínio de serviço com uma
t2.mediuminstância e 10 GiB de armazenamento EBS por várias horasPara saber mais, consulte Amazon OpenSearch Service Pricing
. -
Várias chamadas para o Amazon Transcribe
Para saber mais, consulte Preços do Amazon Transcribe
. -
Várias chamadas de processamento de linguagem natural para o Amazon Comprehend
Para saber mais, consulte Preços do Amazon Comprehend
.
Tópicos
Etapa 1: Configurar os pré-requisitos
Para continuar, você deve ter os recursos a seguir.
| Pré-requisito | Description |
|---|---|
| Bucket do Amazon S3. | Para saber mais, consulte Creating a Bucket (Criar um bucket) no Manual do usuário do Amazon Simple Storage Service. |
| OpenSearch Domínio do serviço | O destino dos dados. Para obter mais informações, consulte Criação OpenSearch de domínios de serviço. |
Se você ainda não tiver esses recursos, poderá criá-los usando os seguintes comandos do AWS CLI :
aws s3 mb s3://my-transcribe-test --region us-west-2
aws opensearch create-domain --domain-name my-transcribe-test --engine-version OpenSearch_1.0 --cluster-config InstanceType=t2.medium.search,InstanceCount=1 --ebs-options EBSEnabled=true,VolumeType=standard,VolumeSize=10 --access-policies '{"Version": "2012-10-17","Statement":[{"Effect":"Allow","Principal":{"AWS":"arn:aws:iam::123456789012:root"},"Action":"es:*","Resource":"arn:aws:es:us-west-2:123456789012:domain/my-transcribe-test/*"}]}' --region us-west-2
nota
Esses comandos usam a região us-west-2, mas você pode usar qualquer região compatível com o Amazon Comprehend. Para saber mais, consulte o Referência geral da AWS.
Etapa 2: Copiar código de exemplo
-
Copie e cole o código de exemplo Python 3 a seguir em um novo arquivo chamado
call-center.py:import boto3 import datetime import json import requests from requests_aws4auth import AWS4Auth import time import urllib.request # Variables to update audio_file_name = '' # For example, 000001.mp3 bucket_name = '' # For example, my-transcribe-test domain = '' # For example, https://search-my-transcribe-test-12345.us-west-2.es.amazonaws.com index = 'support-calls' type = '_doc' region = 'us-west-2' # Upload audio file to S3. s3_client = boto3.client('s3') audio_file = open(audio_file_name, 'rb') print('Uploading ' + audio_file_name + '...') response = s3_client.put_object( Body=audio_file, Bucket=bucket_name, Key=audio_file_name ) # # Build the URL to the audio file on S3. # # Only for the us-east-1 region. # mp3_uri = 'https://' + bucket_name + '.s3.amazonaws.com/' + audio_file_name # Get the necessary details and build the URL to the audio file on S3. # For all other regions. response = s3_client.get_bucket_location( Bucket=bucket_name ) bucket_region = response['LocationConstraint'] mp3_uri = 'https://' + bucket_name + '.s3-' + bucket_region + '.amazonaws.com/' + audio_file_name # Start transcription job. transcribe_client = boto3.client('transcribe') print('Starting transcription job...') response = transcribe_client.start_transcription_job( TranscriptionJobName=audio_file_name, LanguageCode='en-US', MediaFormat='mp3', Media={ 'MediaFileUri': mp3_uri }, Settings={ 'ShowSpeakerLabels': True, 'MaxSpeakerLabels': 2 # assumes two people on a phone call } ) # Wait for the transcription job to finish. print('Waiting for job to complete...') while True: response = transcribe_client.get_transcription_job(TranscriptionJobName=audio_file_name) if response['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break else: print('Still waiting...') time.sleep(10) transcript_uri = response['TranscriptionJob']['Transcript']['TranscriptFileUri'] # Open the JSON file, read it, and get the transcript. response = urllib.request.urlopen(transcript_uri) raw_json = response.read() loaded_json = json.loads(raw_json) transcript = loaded_json['results']['transcripts'][0]['transcript'] # Send transcript to Comprehend for key phrases and sentiment. comprehend_client = boto3.client('comprehend') # If necessary, trim the transcript. # If the transcript is more than 5 KB, the Comprehend calls fail. if len(transcript) > 5000: trimmed_transcript = transcript[:5000] else: trimmed_transcript = transcript print('Detecting key phrases...') response = comprehend_client.detect_key_phrases( Text=trimmed_transcript, LanguageCode='en' ) keywords = [] for keyword in response['KeyPhrases']: keywords.append(keyword['Text']) print('Detecting sentiment...') response = comprehend_client.detect_sentiment( Text=trimmed_transcript, LanguageCode='en' ) sentiment = response['Sentiment'] # Build the Amazon OpenSearch Service URL. id = audio_file_name.strip('.mp3') url = domain + '/' + index + '/' + type + '/' + id # Create the JSON document. json_document = {'transcript': transcript, 'keywords': keywords, 'sentiment': sentiment, 'timestamp': datetime.datetime.now().isoformat()} # Provide all details necessary to sign the indexing request. credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, 'opensearchservice', session_token=credentials.token) # Index the document. print('Indexing document...') response = requests.put(url, auth=awsauth, json=json_document, headers=headers) print(response) print(response.json()) -
Atualize as primeiras seis variáveis.
-
Instale os pacotes exigidos usando os seguintes comandos:
pip install boto3 pip install requests pip install requests_aws4auth -
Coloque seu MP3 no mesmo diretório
call-center.pye execute o script. Uma saída de exemplo se segue:$ python call-center.py Uploading 000001.mp3... Starting transcription job... Waiting for job to complete... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Still waiting... Detecting key phrases... Detecting sentiment... Indexing document... <Response [201]> {u'_type': u'call', u'_seq_no': 0, u'_shards': {u'successful': 1, u'failed': 0, u'total': 2}, u'_index': u'support-calls4', u'_version': 1, u'_primary_term': 1, u'result': u'created', u'_id': u'000001'}
call-center.py executa uma série de operações:
-
O script carrega um arquivo de áudio (nesse caso, um MP3, mas o Amazon Transcribe suporta vários formatos) para seu bucket do S3.
-
Ele envia o URL do arquivo de áudio para o Amazon Transcribe e aguarda até que o trabalho de transcrição termine.
O tempo para concluir o trabalho de transcrição depende do tamanho do arquivo de áudio. Considere minutos, não segundos.
dica
Para melhorar a qualidade da transcrição, você pode configurar um vocabulário personalizado para o Amazon Transcribe.
-
Depois que o trabalho de transcrição for concluído, o script extrairá a transcrição, a deixará com 5.000 caracteres e a enviará para o Amazon Comprehend para uma análise de palavras-chave e sentimento.
-
Por fim, o script adiciona a transcrição completa, as palavras-chave, o sentimento e o registro de data e hora atual a um documento JSON e o indexa no Service. OpenSearch
dica
LibriVox
(Opcional) Etapa 3: Indexar dados de exemplo
Se você não tiver várias gravações de chamadas à disposição — e quem tem? — poderá indexar os documentos de exemplo em sample-calls.zip, os quais são comparáveis àqueles produzidos pelo call-center.py.
-
Crie um arquivo chamado
bulk-helper.py:import boto3 from opensearchpy import OpenSearch, RequestsHttpConnection import json from requests_aws4auth import AWS4Auth host = '' # For example, my-test-domain.us-west-2.es.amazonaws.com region = '' # For example, us-west-2 service = 'es' bulk_file = open('sample-calls.bulk', 'r').read() credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) search = OpenSearch( hosts = [{'host': host, 'port': 443}], http_auth = awsauth, use_ssl = True, verify_certs = True, connection_class = RequestsHttpConnection ) response = search.bulk(bulk_file) print(json.dumps(response, indent=2, sort_keys=True)) -
Atualize as primeiras duas variáveis para
hosteregion. -
Instale o pacote exigido usando o seguinte comando:
pip install opensearch-py -
Faça download e descompacte sample-calls.zip.
-
Coloque
sample-calls.bulkno mesmo diretório quebulk-helper.pye execute o auxiliar. Uma saída de exemplo se segue:$ python bulk-helper.py { "errors": false, "items": [ { "index": { "_id": "1", "_index": "support-calls", "_primary_term": 1, "_seq_no": 42, "_shards": { "failed": 0, "successful": 1, "total": 2 }, "_type": "_doc", "_version": 9, "result": "updated", "status": 200 } },...], "took": 27 }
Etapa 4: Analisar e visualizar seus dados
Agora que você tem alguns dados no OpenSearch Service, você pode visualizá-los usando OpenSearch painéis.
-
Acesse
https://search-.domain.region.es.amazonaws.com/_dashboards -
Antes de usar os OpenSearch painéis, você precisa de um padrão de índice. O Dashboard usa padrões de índice para restringir sua análise a um ou mais índices. Para corresponder ao índice
support-callscriado porcall-center.py, vá para Stack Management (Gerenciamento de pilhas), Index Patterns (Padrões de índice) e definir um padrão de índice desupport*. Em seguida, escolha Next step (Próxima etapa). -
Para o nome de campo Filtro de tempo, escolha timestamp.
-
Agora, você pode começar a criar visualizações. Escolha Visualizar e, em seguida, adicione uma nova visualização.
-
Escolha o gráfico de pizza e o padrão de índice
support*. -
A visualização padrão é básica. Portanto, escolha Dividir fatias para criar uma visualização mais interessante.
Em Aggregation, escolha Terms. Em Campo, escolha sentiment.keyword. Em seguida, escolha Aplicar alterações e Salvar.
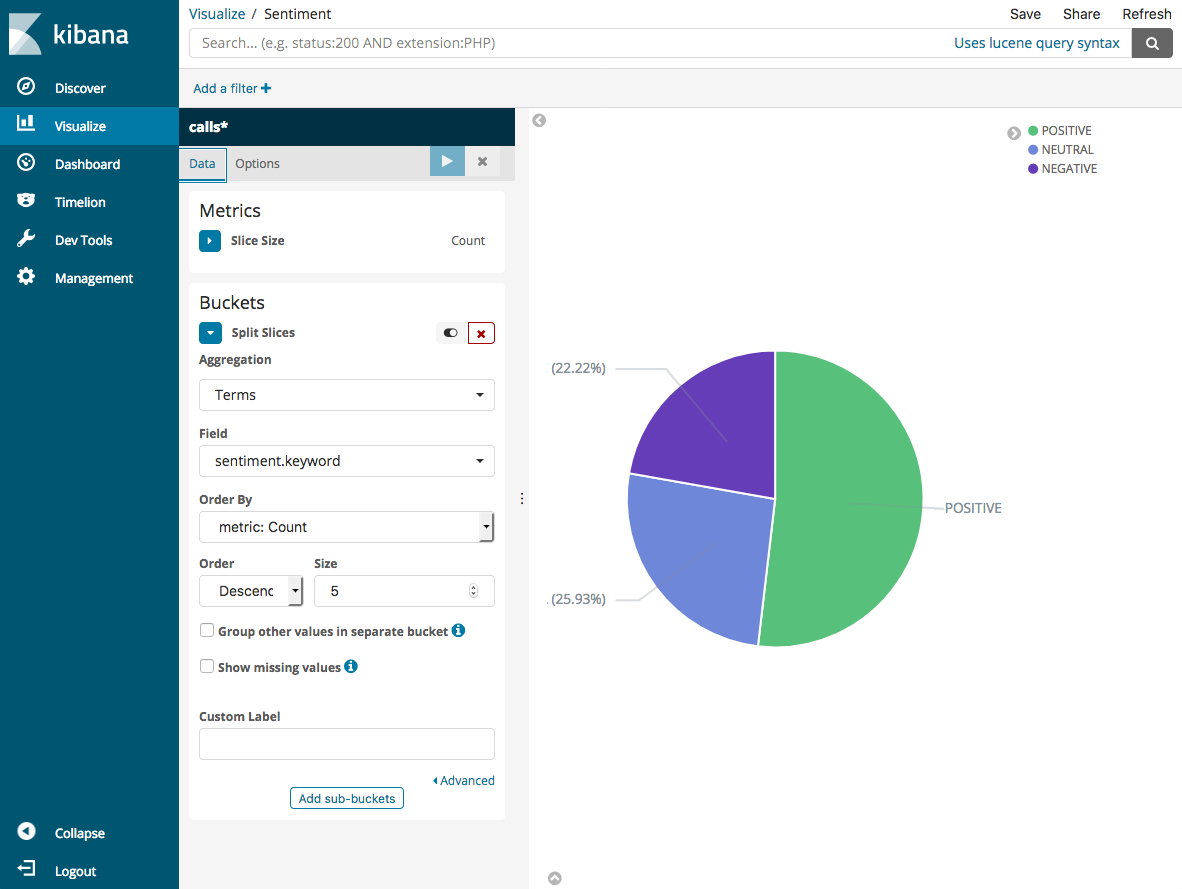
-
Volte para a página Visualizar e adicione outra visualização. Dessa vez, escolha o gráfico de barras horizontais.
-
Selecione Dividir séries.
Em Aggregation, escolha Terms. Em Campo, escolha keywords.keyword e altere Tamanho para 20. Em seguida, escolha Aplicar alterações e Salvar.
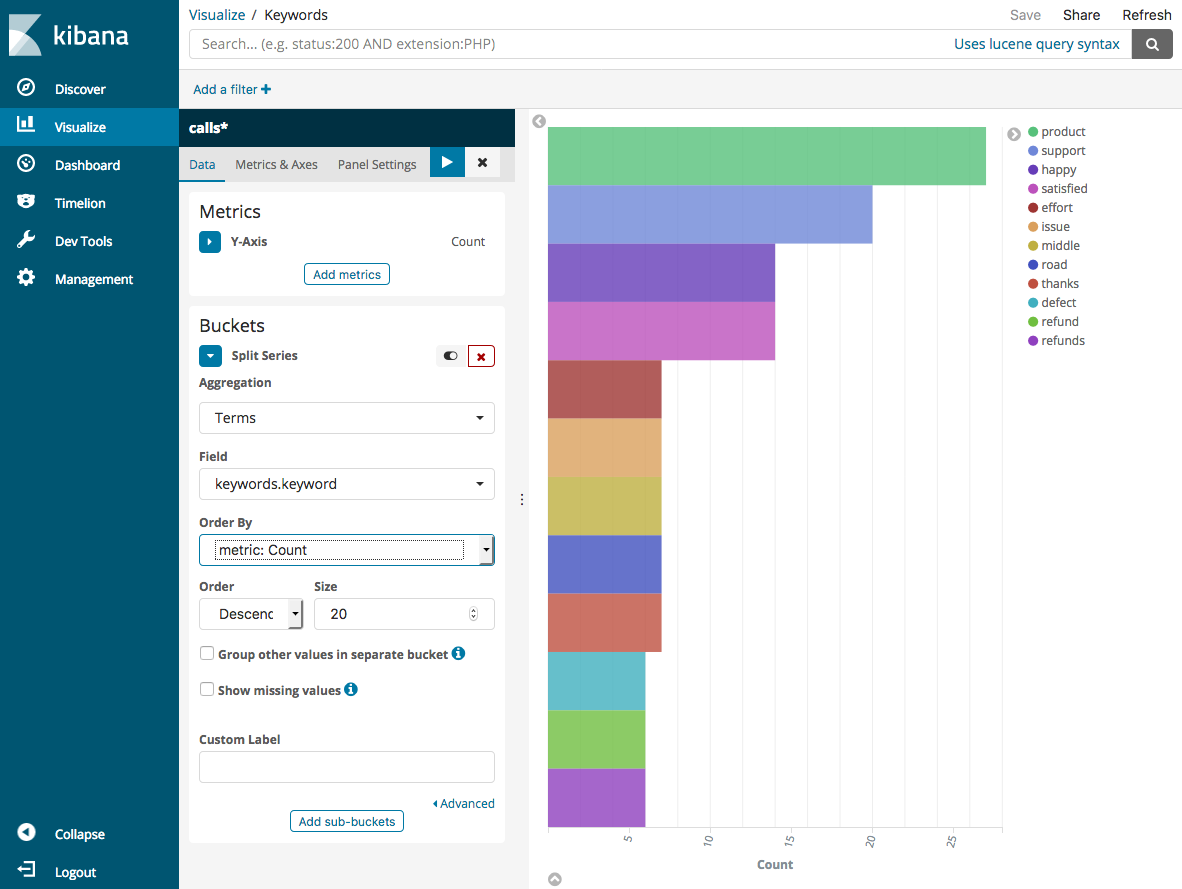
-
Volte para a página Visualizar e adicione uma visualização final, um gráfico de barras verticais.
-
Selecione Dividir séries. Em Agregação, escolha Histograma de data. Em Campo, escolha timestamp e altere Intervalo para Diariamente.
-
Escolha Métricas e eixos e altere Modo para normal.
-
Escolha Aplicar alterações e Salvar.
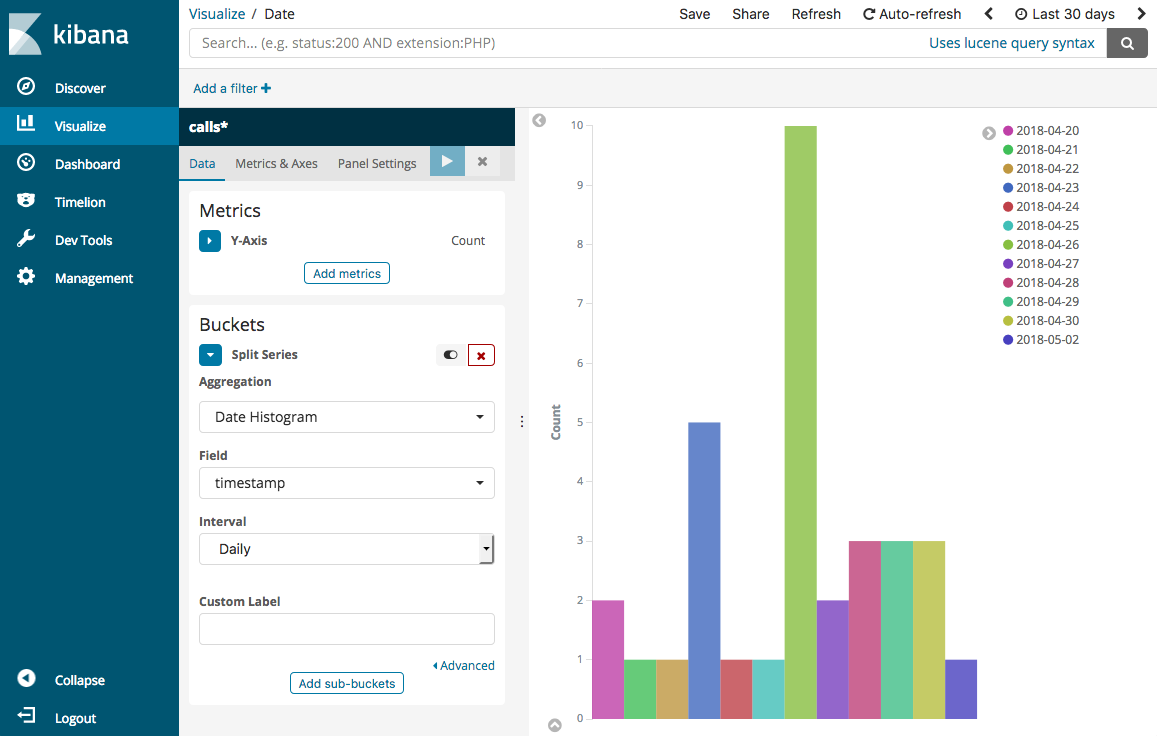
-
Agora que você tem três visualizações, poderá adicioná-las a uma visualização do Dashboards. Escolha Painel, crie um painel e adicione suas visualizações.
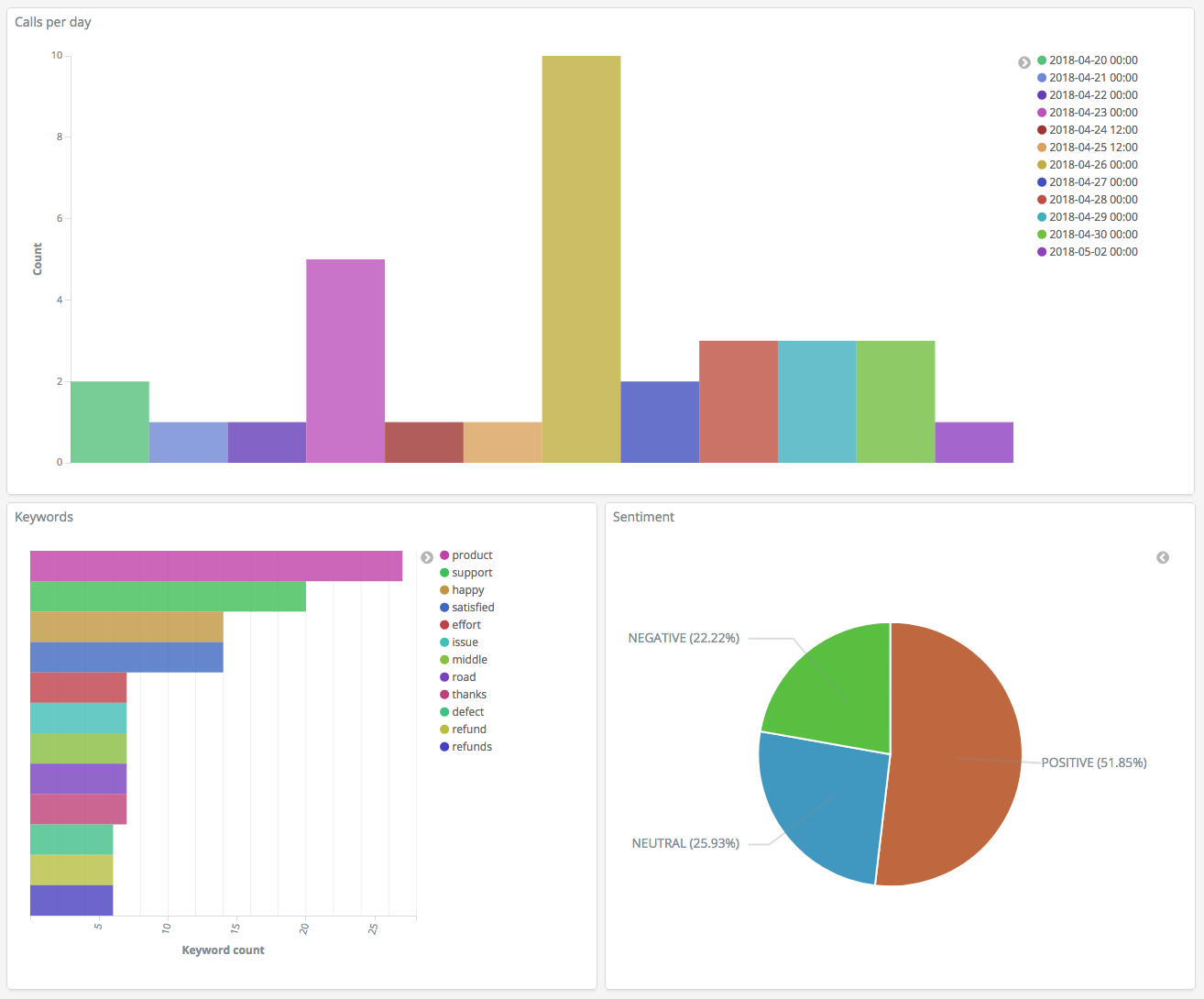
Etapa 5: Limpar recursos e próximas etapas
Para evitar cobranças desnecessárias, exclua o bucket do S3 e o domínio do OpenSearch serviço. Para saber mais, consulte Excluir um bucket no Guia do usuário do Amazon Simple Storage Service e Excluir um domínio de OpenSearch serviço neste guia.
As transcrições exigem muito menos espaço em disco do que MP3 os arquivos. Talvez você consiga reduzir sua janela de MP3 retenção — por exemplo, de três meses de gravações de chamadas para um mês — reter anos de transcrições e ainda economizar nos custos de armazenamento.
Você também pode automatizar o processo de transcrição usando o AWS Step Functions Lambda, adicionar metadados adicionais antes da indexação ou criar visualizações mais complexas para se adequar ao seu caso de uso exato.
