As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Processos do AWS ParallelCluster
Esta seção se aplica somente aos clusters de HPC que são implantados com um dos programadores de trabalhos tradicionais compatíveis (SGE, Slurm ou Torque). Quando usado com esses programadores, o AWS ParallelCluster gerencia o provisionamento e a remoção do nó de computação interagindo tanto com o Grupo de Auto Scaling como com o programador de tarefas subjacente.
Para clusters de HPC baseados no AWS Batch, o AWS ParallelCluster conta com os recursos fornecidos pelo AWS Batch para o gerenciamento do nó de computação.
nota
A partir da versão 2.11.5, AWS ParallelCluster não suporta o uso de programadores SGE ou Torque. Você pode continuar usando-os nas versões até a 2.11.4, inclusive, mas eles não estão qualificados para futuras atualizações ou suporte para solução de problemas das equipes de serviço AWS e de suporte AWS.
SGE and Torque integration processes
nota
Esta seção se aplica somente ao AWS ParallelCluster versões até e incluindo a versão 2.11.4. A partir da versão 2.11.5, AWS ParallelCluster não oferece suporte ao uso de programadores SGE e Torque, Amazon SNS e Amazon SQS.
Visão geral
O ciclo de vida de um cluster começa após ele ser criado por um usuário. Normalmente, um cluster é criado a partir da interface de linha de comando (CLI). Após sua criação, um cluster existirá até ser excluído. Os daemons do AWS ParallelCluster são executados nos nós de cluster, principalmente para gerenciar a elasticidade do cluster de HPC. O diagrama a seguir mostra um fluxo de trabalho do usuário e o ciclo de vida do cluster. As seções a seguir descrevem os daemons do AWS ParallelCluster que são usados para gerenciar o cluster.
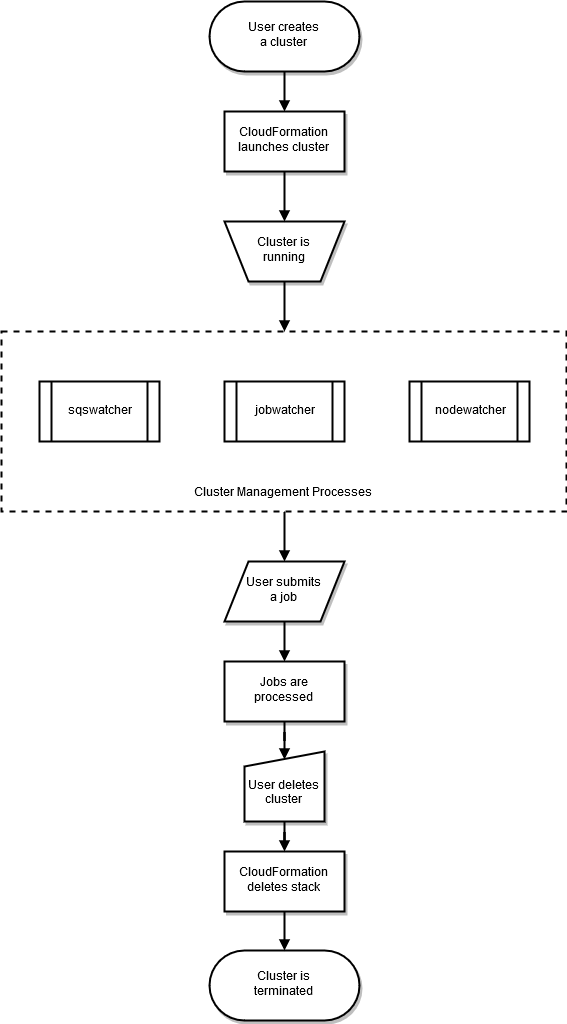
Com programadores SGE e Torque, o AWS ParallelCluster usa os processos nodewatcher, jobwatcher, e sqswatcher.
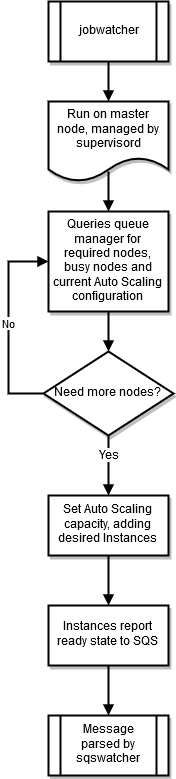
jobwatcher
Quando um cluster está em execução, um processo de propriedade do usuário raiz monitora o programador configurado (SGE ou Torque). A cada minuto, ele avalia a fila para decidir quando aumentar a escala.
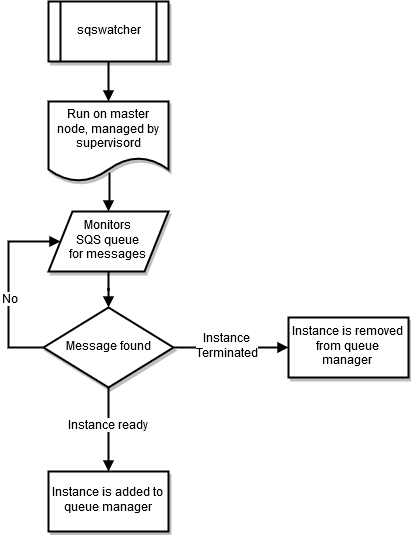
sqswatcher
O processo sqswatcher monitora mensagens do Amazon SQS que são enviadas por ajuste de escala automático, a fim de notificar você sobre as alterações de estado no cluster. Quando uma instância fica online, ela envia uma mensagem "instância pronta" ao Amazon SQS. Essa mensagem é capturada por sqs_watcher, em execução no nó principal. Essas mensagens são usadas para notificar o gerenciador da fila quando novas instâncias ficam online ou são encerradas, para que elas possam ser adicionadas ou removidas da fila.
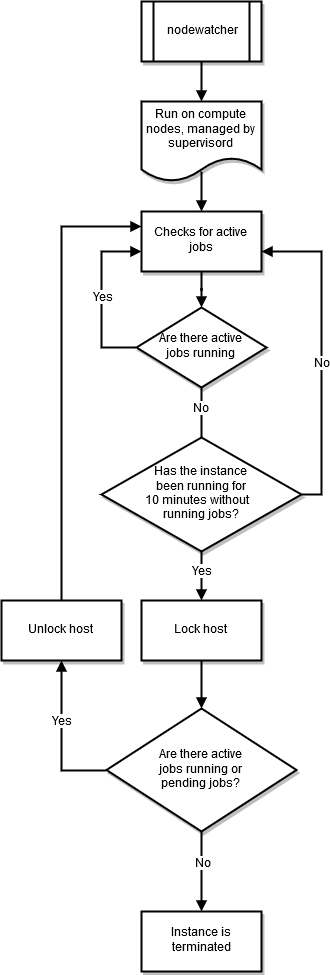
nodewatcher
O processo nodewatcher é executado em cada nó da frota de computação. Após o período de scaledown_idletime, conforme definido pelo usuário, a instância é encerrada.
Slurm integration processes
Com programadores Slurm, o AWS ParallelCluster usa os processos clustermgtd e computemgt.
clustermgtd
Clusters executados em modo heterogêneo (indicado pela especificação de um valor queue_settings) têm um processo daemon (clustermgtd) de gerenciamento de cluster executado no nó principal. Estas tarefas são executadas pelo daemon de gerenciamento de cluster.
-
Limpeza de partições inativas
-
Gerenciamento de capacidade estática: certifique-se de que a capacidade estática esteja sempre ativa e saudável
-
Programador de sincronização com o Amazon EC2.
-
Limpeza de instâncias órfãs
-
Restaura o status do nó do programador quando ocorre encerramento do Amazon EC2 fora do fluxo de trabalho de suspensão
-
Gerenciamento de instâncias não íntegras do Amazon EC2 (falha nas verificações de integridade do Amazon EC2)
-
Gerenciamento de eventos de manutenção programados
-
Gerenciamento de nós não íntegros do Scheduler (falha nas verificações de integridade do Scheduler)
computemgtd
Clusters executados em modo heterogêneo (indicado pela especificação de um valor queue_settings) têm um processo daemon (computemgtd) de gerenciamento de computação executado em cada nó de computação. A cada cinco (5) minutos, o daemon de gerenciamento de computação confirma que o nó principal pode ser alcançado e está íntegro. Se passarem cinco (5) minutos durante os quais o nó principal não puder ser alcançado ou não estiver íntegro, o nó de computação será encerrado.
