As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Etiquetas SSML suportadas
O Amazon Polly é compatível com as seguintes tags SSML:
| Ação | Etiqueta SSML | Disponibilidade com vozes neurais | Disponibilidade com vozes de formato longo | Disponibilidade com vozes generativas |
|---|---|---|---|---|
|
<break> |
Disponibilidade total |
Disponibilidade total |
Disponibilidade total |
|
| <emphasis> |
Não disponível |
Não disponível |
Não disponível |
|
| <lang> |
Disponibilidade total |
Disponibilidade total |
Disponibilidade total |
|
| <mark> |
Disponibilidade total |
Disponibilidade total |
Disponibilidade total |
|
|
<p> |
Disponibilidade total |
Disponibilidade total |
Disponibilidade total |
|
|
<phoneme> |
Disponibilidade total |
Disponibilidade total |
Indisponível |
|
|
<prosody> |
Disponibilidade parcial |
Disponibilidade parcial |
Indisponível |
|
|
<prosody amazon:max-duration> |
Não disponível |
Não disponível |
Não disponível |
|
|
<s> |
Disponibilidade total |
Disponibilidade total |
Disponibilidade total |
|
|
<say-as> |
Disponibilidade parcial |
Disponibilidade parcial |
Disponibilidade parcial |
|
|
<speak> |
Disponibilidade total |
Disponibilidade total |
Disponibilidade total |
|
|
<sub> |
Disponibilidade total |
Disponibilidade total |
Disponibilidade total |
|
|
<w> |
Disponibilidade total |
Disponibilidade total |
Disponibilidade total |
|
|
<amazon:auto-breaths> |
Não disponível |
Não disponível |
Não disponível |
|
| <amazon:domain name="news"> |
Selecionar somente vozes neurais |
Não disponível |
Não disponível |
|
|
<amazon:effect name="drc"> |
Disponibilidade total |
Disponibilidade total |
Indisponível |
|
|
<amazon:effect phonation="soft"> |
Não disponível |
Não disponível |
Não disponível |
|
|
<amazon : efeito > vocal-tract-length |
Não disponível |
Não disponível |
Não disponível |
|
|
<amazon:effect name="whispered"> |
Não disponível |
Não disponível |
Não disponível |
nota
Se você usar tags SSML incompatíveis no formato padrão, neural ou de forma longa, receberá um erro.
Identificar um texto aprimorado por SSML
<speak>
Essa tag é suportada pelos formatos TTS generativo, longo, neural e padrão.
A tag <speak> é o elemento raiz de todos os textos SSML do Amazon Polly. Todos os textos aprimorados por SSML devem estar entre tags <speak>.
<speak>Mary had a little lamb.</speak>Adicionar uma pausa
<break>
Essa tag é suportada pelos formatos TTS generativo, longo, neural e padrão.
Para adicionar uma pausa ao texto, use a tag <break>. Você pode definir uma pausa com base na intensidade (equivalente à pausa após uma vírgula, uma frase ou um parágrafo), ou configurá-la para um determinado período em segundos ou milissegundos. Se você não especificar um atributo para determinar o tamanho da pausa, o Amazon Polly usará o padrão, que é <break
strength="medium"/>, que adiciona uma pausa do tamanho de uma pausa após uma vírgula.
Valores de atributo strength:
-
none: nenhuma pausa. Usenonepara remover uma pausa comum, como a que ocorre depois de um ponto final. -
x-weak: tem a mesma função denone; nenhuma pausa. -
weak: define uma pausa com a mesma duração da pausa após uma vírgula. -
medium: tem a mesma função deweak. -
strong: define uma pausa com a mesma duração da pausa após uma frase. -
x-strong: define uma pausa com a mesma duração da pausa após um parágrafo.
Valores de atributo time:
-
[number]s10s. -
[number]ms10000ms.
Por exemplo: .
<speak>
Mary had a little lamb <break time="3s"/>Whose fleece was white as snow.
</speak>Se você não usar um atributo com a tag break, o resultado variará dependendo do texto:
-
Se não houver mais nenhuma pontuação ao lado da tag
break, ela criará uma<break strength="medium"/>(pausa de duração de vírgula). -
Se a tag estiver ao lado de uma vírgula, ela atualizará a tag para uma
<break strength="strong"/>(pausa de duração de frase). -
Se a tag estiver ao lado de um ponto final, ela atualizará a tag para uma
<break strength="x-strong"/>(pausa de duração de parágrafo).
Enfatizar palavras
<emphasis>
Essa tag é compatível somente com o formato TTS padrão.
Para enfatizar palavras, use a tag <emphasis>. Quando há ênfase de palavras, a taxa e o volume da fala mudam. Uma ênfase maior significa que o texto será falado pelo Amazon Polly em um volume mais alto e velocidade mais lenta. Uma ênfase menor significa que a fala será mais tranquila e mais lenta. Para especificar o grau de ênfase, use o atributo level.
Valores de atributo level:
-
Strong: aumenta o volume e desacelera a taxa da fala para que ela soe mais alta e mais lentamente. -
Moderate: aumenta o volume e diminui a taxa da fala, mas menos do questrong.Moderateé o padrão. -
Reduced: diminui o volume e aumenta a taxa da fala. A fala é mais suave e mais rápida.
nota
A taxa e o volume normais de uma voz ficam entre os níveis moderate e reduced.
Por exemplo: .
<speak> I already told you I <emphasis level="strong">really like</emphasis> that person. </speak>
Especificar outro idioma para palavras específicas
<lang>
Essa tag é suportada pelos formatos TTS generativo, longo, neural e padrão.
Especifique outro idioma para uma determinada palavra, frase ou frase com a tag <lang>. Frases e palavras em idioma estrangeiro geralmente são ditas com melhor sonoridade quando são inseridas dentro de um par de tags <lang>. Para especificar o idioma, use o atributo xml:lang. Para obter uma lista completa dos idiomas disponíveis, consulte Idiomas no Amazon Polly.
A menos que você aplique a tag <lang>, todas as palavras no texto de entrada serão faladas no idioma da voz especificada no voice-id. Se você aplicar a tag <lang>, as palavras serão faladas no idioma selecionado.
Por exemplo, se voice-id for Joanna (que fala inglês dos EUA), o Amazon Polly falará a seguinte frase na voz dela sem sotaque francês:
<speak>
Je ne parle pas français.
</speak>Se você usar a voz da Joanna com a tag <lang>, o Amazon Polly falará a frase com a voz dela em francês com sotaque americano:
<speak>
<lang xml:lang="fr-FR">Je ne parle pas français.</lang>.
</speak>Como Joanna não é uma voz nativa do Francês, a pronúncia se baseia no idioma nativo dela, que é o Inglês dos EUA. Por exemplo, apesar da pronúncia perfeita em Francês ter uma vibrante uvular /R/ na palavra français, a voz em Inglês dos EUA da Joanna pronuncia esse fonema como o som /r/ correspondente.
Se você usar o voice-id de Giorgio, que fala italiano, com o seguinte texto, o Amazon Polly falará a frase na voz dele com pronúncia italiana:
<speak>
Mi piace Bruce Springsteen.
</speak>Se você usar a mesma voz com a tag <lang>, o Amazon Polly pronunciará Bruce Springsteen em Inglês com sotaque italiano:
<speak>
Mi piace <lang xml:lang="en-US">Bruce Springsteen.</lang>
</speak>Essa tag também pode ser usada como substituto da DefaultLangCodeopção opcional ao sintetizar a fala. No entanto, isso requer que você formate o texto usando SSML.
Colocar uma tag personalizada no texto
<mark>
Essa tag é suportada pelos formatos TTS generativo, longo, neural e padrão.
Para colocar uma tag personalizada no texto, use a tag <mark>. O Amazon Polly não realiza nenhuma ação na tag, mas retorna a localização dela nos metadados do SSML. Essa tag pode ter qualquer nome que você desejar, desde que ela mantenha o seguinte formato:
<mark name="tag_name"/>Por exemplo, se o nome da tag for "animal" e o texto de entrada for:
<speak>
Mary had a little <mark name="animal"/>lamb.
</speak>O Amazon Polly poderá retornar os seguintes metadados de SSML:
{"time":767,"type":"ssml","start":25,"end":46,"value":"animal"}Adicionar uma pausa entre parágrafos
<p>
Essa tag é suportada pelos formatos TTS generativo, longo, neural e padrão.
Para adicionar uma pausa entre parágrafos no texto, use a tag <p>. O uso dessa tag fornece uma pausa maior do que aquelas geralmente colocadas por falantes nativos em vírgulas ou final de frases. Use a tag <p> para incluir o parágrafo:
<speak>
<p>This is the first paragraph. There should be a pause after this text is spoken.</p>
<p>This is the second paragraph.</p>
</speak>Isso é equivalente a especificar uma pausa usando <break strength="x-strong"/>.
Usar a pronúncia fonética
<phoneme>
Essa tag é compatível com os formatos TTS de forma longa, padrão e neural.
Para que o Amazon Polly use a pronúncia fonética em um texto específico, use a tag <phoneme>.
Dois atributos são necessários com a tag <phoneme>. Eles indicam o alfabeto fonético que o Amazon Polly usa e os símbolos fonéticos da pronúncia corrigida:
-
alphabet-
ipa– indica que o sistema do Alfabeto Fonético Internacional (AFI) será usado. -
x-sampa– indica que o sistema Extended Speech Assessment Methods Phonetic Alphabet (X-SAMPA, Alfabeto fonético estendido de métodos de avaliação da fala) será usado.
-
-
ph-
Especifica os símbolos fonéticos da pronúncia. Para mais informações, consulte Tabelas de fonemas e visemas para os idiomas compatíveis.
-
Com a tag <phoneme>, o Amazon Polly usa a pronúncia especificada pelo atributo ph em vez da pronúncia padrão associada ao idioma da voz selecionada.
Por exemplo, a palavra "pecan" pode ser pronunciada de duas formas. No exemplo a seguir, uma pronúncia personalizada diferente em cada linha é atribuída à palavra "pecan". O Amazon Polly pronuncia "pecan" conforme especificado nos atributos ph, em vez de usar a pronúncia padrão.
Alfabeto Fonético Internacional (AFI)
<speak> You say, <phoneme alphabet="ipa" ph="pɪˈkɑːn">pecan</phoneme>. I say, <phoneme alphabet="ipa" ph="ˈpi.kæn">pecan</phoneme>. </speak>
Extented Speech Assessment Methods Phonetic Alphabet (X-SAMPA, Alfabeto fonético de métodos de avaliação da fala).
<speak> You say, <phoneme alphabet='x-sampa' ph='pI"kA:n'>pecan</phoneme>. I say, <phoneme alphabet='x-sampa' ph='"pi.k{n'>pecan</phoneme>. </speak>
O chinês mandarim usa Pinyin para pronúncia fonética.
Pinyin
<speak> 你说 <phoneme alphabet="x-amazon-pinyin" ph="bo2">薄</phoneme>。 我说 <phoneme alphabet="x-amazon-pinyin" ph="bao2">薄</phoneme>。 </speak>
O japonês usa Yomigana e a pronúncia Kana.
Yomigana
<speak> 名前は<phoneme alphabet="x-amazon-yomigana" ph="ひろかず">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="ヒロカズ">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="Hirokazu">浩一</phoneme>です。 </speak>
Pronúncia Kana
<speak> 名前は<phoneme alphabet="x-amazon-pron-kana" ph="ヒロ'カズ">浩一</phoneme>です。 </speak>
Controlar o volume, a velocidade e o tom da fala
<prosody>
Os atributos das tags de prosódia são totalmente compatíveis com as vozes TTS padrão. As vozes neurais e em formato longo são compatíveis com os atributos volume e rate, mas não com o atributo pitch.
Para controlar o volume, a velocidade ou o tom da voz selecionada, use a tag prosody.
O volume, a taxa e o tom da fala dependem da voz selecionada. Além das diferenças entre vozes em idiomas diferentes, há diferenças entre vozes individuais falando o mesmo idioma. Por isso, embora os atributos sejam semelhantes em todos os idiomas, há variações nítidas entre idiomas e nenhum valor absoluto estará disponível.
A tag prosody tem três atributos, e cada um deles têm vários valores disponíveis para definir o atributo. Todos os atributos usam a mesma sintaxe:
<prosody attribute="value"></prosody>-
volume-
default: redefine o volume como o nível padrão da voz atual. -
silent,x-soft,soft,medium,loud,x-loud: define o volume como um valor predefinido para a voz atual. -
+ndB,-ndB: altera o volume com relação ao nível atual. Um valor de+0dBsignifica nenhuma alteração,+6dBsignifica aproximadamente o dobro do volume atual e-6dBsignifica aproximadamente metade do volume atual.
Por exemplo, você pode definir o volume para um trecho das seguintes maneiras:
<speak> Sometimes it can be useful to <prosody volume="loud">increase the volume for a specific speech.</prosody> </speak>Ou você pode definir assim:
<speak> And sometimes a lower volume <prosody volume="-6dB">is a more effective way of interacting with your audience.</prosody> </speak> -
-
rate-
x-slow,slow,medium,fastex-fastespecificam o tom para um valor predefinido da voz selecionada. -
n%: uma alteração de porcentagem não negativa na taxa da fala. Por exemplo, um valor de 100% significa nenhuma alteração na taxa da fala, 200% significa que a taxa é o dobro da taxa padrão e 50% que taxa é metade da taxa padrão. Esse valor varia de 20 a 200%.
Por exemplo, você pode definir a taxa da fala para um trecho das seguintes maneiras:
<speak> For dramatic purposes, you might wish to <prosody rate="slow">slow up the speaking rate of your text.</prosody> </speak>Ou você pode definir assim:
<speak> Although in some cases, it might help your audience to <prosody rate="85%">slow the speaking rate slightly to aid in comprehension.</prosody> </speak> -
-
pitch-
default: redefine o tom como o nível padrão da voz atual. -
x-low,low,medium,high,x-high: Define o tom do valor predefinido para a voz atual. -
+n%ou-n%: Ajusta o tom por uma porcentagem relativa. Por exemplo, um valor de+0%significa nenhuma alteração no tom da linha de base,+5%fornece um tom de linha de base um pouco maior e-5%resulta em um tom de linha de base um pouco menor.
Por exemplo, você pode definir o tom para um trecho das seguintes maneiras:
<speak> Do you like sythesized speech <prosody pitch="high">with a pitch that is higher than normal?</prosody> </speak>Ou você pode definir assim:
<speak> Or do you prefer your speech <prosody pitch="-10%">with a somewhat lower pitch?</prosody> </speak> -
A tag <prosody> deve conter pelo menos um atributo, mas pode incluir mais atributos na mesma tag.
<speak> Each morning when I wake up, <prosody volume="loud" rate="x-slow">I speak quite slowly and deliberately until I have my coffee.</prosody> </speak>
Ela também pode ser combinada com tags aninhadas da seguinte forma:
<speak> <prosody rate="85%">Sometimes combining attributes <prosody pitch="-10%">can change the impression your audience has of a voice</prosody> as well.</prosody> </speak>
Configurar uma duração máxima para fala sintetizada
<prosody amazon:max-duration>
No momento, essa tag é compatível somente com o formato TTS padrão.
Para controlar quanto tempo você deseja que dure uma fala quando ela for sintetizada, use a tag <prosody> com o atributo amazon:max-duration.
A duração da fala sintetizada varia levemente, dependendo da voz selecionada. Isso pode dificultar a correspondência da fala sintetizada com recursos visuais ou outras atividades que exigem uma sincronização precisa. Esse problema é ampliado em aplicativos de tradução, pois o tempo usado para dizer certas frases pode variar amplamente entre diferentes idiomas.
A tag <prosody amazon:max-duration> corresponde a fala sintetizada à quantidade de tempo que você deseja que ela leve (a duração).
Essa tag usa a seguinte sintaxe:
<prosody amazon:max-duration="time duration">Com a tag <prosody amazon:max-duration>, é possível especificar a duração em segundos ou milissegundos:
-
ns -
nms
Por exemplo, o seguinte texto falado tem uma duração máxima de 2 segundos:
<speak>
<prosody amazon:max-duration="2s">
Human speech is a powerful way to communicate.
</prosody>
</speak>Texto colocado dentro da tag não excede a duração especificada. Se a voz ou o idioma escolhido normalmente levam mais tempo do que aquela duração, o Amazon Polly acelera a fala para que ela se encaixe na duração especificada.
Se a duração especificada leva mais tempo do que o necessário para ler o texto em uma velocidade normal, o Amazon Polly lê a fala normalmente. Ele não diminui a velocidade da fala ou adiciona silêncio, portanto o áudio resultante fica mais curto do que o solicitado.
nota
O Amazon Polly aumenta a velocidade não mais do que cinco vezes a velocidade normal. Se o texto for falado mais rápido do que isso, normalmente não fará sentido. Se uma fala não couber na duração especificada, mesmo quando acelerada ao máximo, o áudio será acelerado mas durará mais do que a duração especificada.
É possível incluir uma única frase ou várias frases em uma tag <prosody amazon:max-duration>, e também é possível usar várias tags <prosody amazon:max-duration> em seu texto.
Por exemplo: .
<speak> <prosody amazon:max-duration="2400ms"> Human speech is a powerful way to communicate. </prosody> <break strength="strong"/> <prosody amazon:max-duration="5100ms"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> <break strength="strong"/> <prosody amazon:max-duration="8900ms"> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak>
Usar a tag <prosody amazon:max-duration> pode aumentar a latência quando o Amazon Polly retornar a fala sintetizada. O grau de latência depende da passagem e da duração. Recomendamos usar um texto composto de passagens relativamente curtas.
Limitações
Há limitações em como você usa a tag <prosody
amazon:max-duration> e em como ela funciona com outras tags SSML:
-
O texto dentro de uma tag
<prosody amazon:max-duration>não pode ter mais de 1500 caracteres. -
Não é possível aninhar tags
<prosody amazon:max-duration>. Se você colocar uma tag<prosody amazon:max-duration>dentro de outra, o Amazon Polly ignorará a tag interna.No seguinte exemplo, a tag
<prosody amazon:max-duration="5s">é ignorada:<speak> <prosody amazon:max-duration="16s"> Human speech is a powerful way to communicate. <prosody amazon:max-duration="5s"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak> -
Não é possível usar as tags
<prosody>com o atributoratedentro de uma tag<prosody amazon:max-duration>. Isso ocorre porque as duas afetam a velocidade de fala do texto.No seguinte exemplo, o Amazon Polly ignora a tag
<prosody rate="2">:<speak> <prosody amazon:max-duration="7500ms"> Human speech is a powerful way to communicate. <prosody rate="2"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </prosody> </speak>
Pausas e max-duration
Ao usar a tag max-duration, você ainda poderá inserir pausas dentro do texto. No entanto, o Amazon Polly inclui a duração da pausa ao calcular a duração máxima da fala. Além disso, o Amazon Polly preserva as pausas breves que ocorrem onde vírgulas e pontos são colocados em uma passagem e inclui na duração máxima.
Por exemplo, no seguinte bloco, a pausa de 600 milissegundos e as pausas causadas pelas vírgulas e pontos ocorrem dentro da fala de 8 segundos:
<speak> <prosody amazon:max-duration="8s"> Human speech is a powerful way to communicate. <break time="600ms"/> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </speak>
Adicionar uma pausa entre as frases
<s>
Essa tag é suportada pelos formatos TTS generativo, longo, neural e padrão.
Para adicionar uma pausa entre linhas ou frases no texto, use a tag <s>. Usar essa tag gera o mesmo resultado destas ações:
-
Finalizar uma frase com um ponto (.)
-
Especificar uma pausa com
<break strength="strong"/>
Ao contrário da tag <break>, a tag <s> inclui a frase. Isso é útil ao sintetizar falas organizadas em linhas, em vez de frases, como poesias.
No exemplo a seguir, a tag <s> cria uma curta pausa após a primeira e a segunda frase. A frase final não tem a tag <s>, mas também tem uma pausa curta depois, pois contém um ponto final.
<speak> <s>Mary had a little lamb</s> <s>Whose fleece was white as snow</s> And everywhere that Mary went, the lamb was sure to go. </speak>
Controlar como tipos especiais de palavras são ditas
<say-as>
Exceto pela characters opção, a <say-as> tag é compatível com os formatos TTS generativo, longo, neural e padrão. Se o Amazon Polly estiver usando uma voz neural e encontrar a tag <say-as> com a opção characters no runtime, a frase afetada será sintetizada usando a voz padrão relacionada. No entanto, a frase afetada ainda será cobrada como se usasse uma voz neural.
Use a tag <say-as> com o atributo interpret-as para informar ao Amazon Polly como dizer determinados caracteres, palavras e números. Isso permite que você forneça contexto adicional para eliminar qualquer ambiguidade sobre como o Amazon Polly deve renderizar o texto.
A tag <say-as> usa um atributo, interpret-as, que usa um número de possíveis valores disponíveis. Todos usam a mesma sintaxe:
<say-as interpret-as="value">[text to be interpreted]</say-as>Os valores a seguir estão disponíveis com o interpret-as:
-
charactersouspell-out: Soletra cada letra do texto, como em. a-b-cnota
No momento, essa opção não é compatível com vozes neurais. Se você estiver usando uma voz neural e esse código SSML for encontrado pelo Amazon Polly em tempo de execução, a frase afetada será sintetizada usando a voz padrão relacionada. No entanto, essa frase ainda será cobrada como se usasse uma voz neural.
-
cardinalounumber: interpreta o texto numérico como um número cardinal, por exemplo, 1.234. -
ordinal: interpreta o texto numérico como um número ordinal, por exemplo, 1.234º. -
digits: soletra cada dígito individualmente, como em 1-2-3-4. -
fraction: interpreta o texto numérico como uma fração. Isso funciona tanto em frações comuns, como 3/20, quanto em mistas, como 2 ½. Veja a seguir mais informações. -
unit: interpreta um texto numérico como medida. O valor deve ser um número ou uma fração que, por sua vez, é seguida por uma unidade sem espaço no meio, como em1/2inch, ou por apenas uma unidade, como em1meter. -
date: interpreta o texto como uma data. O formato de data deve ser especificado com o atributo do formato. Veja a seguir mais informações. -
time: interpreta o texto numérico como uma duração, em minutos e segundos, como em1'21". -
address: interpreta o texto como parte de um endereço. -
expletive: aumenta o som do conteúdo incluído na tag. -
telephone: interpreta o texto numérico como um número de telefone de 7 ou 10 dígitos, como em2025551212. Você também pode usar esse valor para lidar com ramais telefônicos, como em2025551212x345. Veja a seguir mais informações.nota
Atualmente, a opção
telephonenão está disponível para todos os idiomas. No entanto, ela está disponível para as vozes que falam variantes do idioma inglês (en-AU, en-GB, en-IN, en-US e en-GB-WLS), variantes do idioma espanhol (es-ES, es-MX e es-US), variantes do idioma francês (fr-FR e fr-CA) e variantes do português (pt-BR e pt-PT), bem como alemão (de-DE), italiano (it-IT), japonês (ja-JP) e russo (ru-RU). Também deve ser observado que, em alguns casos, idiomas como o árabe (arb) tratam automaticamente o número definido como um número de telefone e, portanto, não implementam a tagtelephoneSSML.
Frações
O Amazon Polly interpretará os valores da tag say-as com o atributo interpret-as="fraction" como frações comuns. Veja a seguir a sintaxe de frações.
-
Fração
Sintaxe:
número cardinal/número cardinal, como 2/9.Por exemplo:
<say-as interpret-as="fraction">2/9</say-as>é pronunciado "dois nonos." -
Número misto não negativo
Sintaxe:
número cardinal+número cardinal/número cardinal, como 3+1/2.Por exemplo:
<say-as interpret-as="fraction">3+1/2</say-as>é pronunciado "três e meio".nota
Deve haver um
+entre "3" e "1/2". O Amazon Polly não é compatível com um número misto sem o+, como "3 1/2".
Datas
Quando interpret-as for definido como date, você também precisará indicar o formato da data.
Neste caso, usa-se a seguinte sintaxe:
<say-as interpret-as="date" format="format">[date]</say-as>
Por exemplo: .
<speak> I was born on <say-as interpret-as="date" format="mdy">12-31-1900</say-as>. </speak>
Os formatos a seguir podem ser usados com o atributo date.
-
mdy: onth-day-year M. -
dmy: ay-month-year D. -
ymd: ear-month-day Y. -
md: mês-dia. -
dm: dia-mês. -
ym: ano-mês. -
my: mês-ano. -
d: dia. -
m: Mês. -
y: Ano. -
yyyymmdd: ear-month-day Y. Se você usar esse formato, o Amazon Polly poderá ignorar partes da data ao usar pontos de interrogação.Por exemplo, o Amazon Polly renderiza o seguinte exemplo como "22 de setembro":
<say-as interpret-as="date">????0922</say-as>Formatnão é necessários.
Telefone
O Amazon Polly tenta interpretar o texto fornecido corretamente com base na formatação do texto, mesmo sem a tag <say-as>. Por exemplo, se o texto incluir 202-555-1212, o Amazon Polly o interpretará como um número de telefone de dez dígitos e dirá cada dígito individualmente, com uma breve pausa para cada traço. Nesse caso, você não precisa usar o <say-as interpret-as="telephone">. No entanto, se você fornecer o texto 2025551212 e quiser que o Amazon Polly o diga como número de telefone, será necessário especificar <say-as
interpret-as="telephone">.
A lógica para a interpretação de cada elemento é específica de cada idioma. Por exemplo, o Inglês dos EUA e o Inglês do Reino Unido se diferenciam na pronúncia dos números de telefone (no Inglês do Reino Unido, as sequências do mesmo dígito são agrupadas, como "double five" [dois números cinco] ou "triple four" [três números quatro]). Para ver a diferença, teste o exemplo a seguir com uma voz dos EUA e com uma voz do Reino Unido:
<speak> Richard's number is <say-as interpret-as="telephone">2122241555</say-as> </speak>
Pronunciar acrônimos e abreviaturas
<sub>
Essa tag é suportada pelos formatos TTS generativo, longo, neural e padrão.
Use a tag <sub> com o atributo alias para substituir uma palavra (ou pronúncia) diferente do texto selecionado, como um acrônimo ou abreviação.
Neste caso, usa-se sintaxe:
<sub alias="new word">abbreviation</sub>No exemplo a seguir, o nome "Mercúrio" é substituído pelo símbolo químico do elemento para tornar o conteúdo do áudio mais claro.
<speak> My favorite chemical element is <sub alias="Mercury">Hg</sub>, because it looks so shiny. </speak>
Melhorar a pronúncia especificando partes da fala
<w>
Essa tag é suportada pelos formatos TTS generativo, longo, neural e padrão.
Você pode usar a tag <w> para personalizar a pronúncia de palavras especificando a parte da fala da palavra ou significado alternativo. Isso é feito usando o atributo role.
Essa tag usa a seguinte sintaxe:
<w role="attribute">text</w>Os valores a seguir podem ser usados para o atributo role:
Para especificar a parte da fala:
-
amazon:VB: interpreta a palavra como verbo (presente simples). -
amazon:VBD: interpreta a palavra como verbo no pretérito. -
amazon:DT: interpreta a palavra como um determinante. -
amazon:IN: interpreta a palavra como uma preposição. -
amazon:JJ: interpreta a palavra como um adjetivo. -
amazon:NN: interpreta a palavra como um substantivo.
Por exemplo, dependendo da parte da fala, a pronúncia do inglês dos EUA da palavra "read" varia de acordo com a tag:
<speak> The word <say-as interpret-as="characters">read</say-as> may be interpreted as either the present simple form <w role="amazon:VB">read</w>, or the past participle form <w role="amazon:VBD">read</w>. </speak>
Como definir um significado específico:
-
amazon:DEFAULT: usa o sentido padrão da palavra. -
amazon:SENSE_1: usa o sentido não padrão da palavra, quando presente. Por exemplo, o termo "bass" é pronunciado de forma diferente dependendo de seu significado. O significado padrão é a parte mais baixa da escala musical. O significado alternativo é uma espécie de peixe de água doce também chamado de "bass", mas com pronúncia diferente. O uso de<w role="amazon:SENSE_1">bass</w>renderiza a pronúncia não padrão (peixe de água fresca) para o texto de áudio.
Essa diferença poderá ser ouvida se você sintetizar o seguinte:
<speak> Depending on your meaning, the word <say-as interpret-as="characters">bass</say-as> may be interpreted as either a musical element: bass, or as its alternative meaning, a freshwater fish <w role="amazon:SENSE_1">bass</w>. </speak>
nota
Alguns idiomas podem ter uma seleção diferente de partes da fala com suporte.
Adicionar o som da respiração
<amazon:breath> e <amazon:auto-breaths>
Essa tag é compatível somente com o formato TTS padrão.
Um fala natural inclui corretamente palavras faladas e sons de respiração. Ao adicionar sons de respiração à fala sintetizada, você pode torná-la mais natural. As tags <amazon:breath> e <amazon:auto-breaths> fornecem respirações. Você tem as seguintes opções:
-
Modo manual: defina o local, o comprimento e o volume de um som de respiração no texto
-
Modo automatizado: o Amazon Polly insere automaticamente sons de respiração na saída de fala
-
Modo misto: você e o Amazon Polly adicionam sons de respiração
Modo manual
No modo manual, coloque a tag <amazon:breath/> no texto de entrada em que você deseja colocar uma respiração. Você pode personalizar o comprimento e volume de respirações com os atributos duration e volume respectivamente:
-
duration: controla o comprimento da respiração. Os valores válidos são:default,x-short,short,medium,long,x-long. O valor padrão émedium. -
volume: controla o volume de sons de respiração. Os valores válidos são:default,x-soft,soft,medium,loud,x-loud. O valor padrão émedium.
nota
O comprimento e o volume exatos de cada valor de atributo dependem da voz do Amazon Polly usada.
Para definir um som de respiração usando os valores padrão, use <amazon:breath/> sem atributos.
Por exemplo, para usar atributos para definir a duração e o volume de uma respiração como média, você deve definir os atributos da seguinte maneira:
<speak> Sometimes you want to insert only <amazon:breath duration="medium" volume="x-loud"/>a single breath. </speak>
Para usar os valores padrão, você pode simplesmente usar a tag:
<speak> Sometimes you need <amazon:breath/>to insert one or more average breaths <amazon:breath/> so that the text sounds correct. </speak>
Você pode adicionar sons de respiração individuais em um trecho da seguinte forma:
<speak> <amazon:breath duration="long" volume="x-loud"/> <prosody rate="120%"> <prosody volume="loud"> Wow! <amazon:breath duration="long" volume="loud"/> </prosody> That was quite fast. <amazon:breath duration="medium" volume="x-loud"/> I almost beat my personal best time on this track. </prosody> </speak>
Modo automatizado
No modo automatizado, use a tag <amazon:auto-breaths> para instruir o Amazon Polly a criar automaticamente ruídos de respiração em intervalos apropriados. Você pode definir a frequência dos intervalos, o volume e a duração. Coloque a tag </amazon:auto-breaths> no início do texto em que você deseja aplicar a respiração automatizada e feche a tag no final.
nota
Ao contrário da tag do modo manual, <amazon:breath/>, a tag <amazon:auto-breaths> requer uma tag de fechamento (</amazon:auto-breaths>).
Você pode usar os seguintes atributos opcionais com a tag <amazon:auto-breaths>:
-
volume: controla o volume de sons de respiração. Os valores válidos são:default,x-soft,soft,medium,loud,x-loud. O valor padrão émedium. -
frequency: controla a frequência com que sons respiratórios ocorrem no texto. Os valores válidos são:default,x-low,low,medium,high,x-high. O valor padrão émedium. -
duration: controla o comprimento da respiração. Os valores válidos são:default,x-short,short,medium,long,x-long. O valor padrão émedium.
Por padrão, a frequência de sons de respiração depende do texto de entrada. No entanto, muitas vezes, sons de respiração ocorrem após vírgulas e pontos.
Os exemplos a seguir mostram como usar a tag <amazon:auto-breaths>. Para decidir quais opções usar para o seu conteúdo, copie os exemplos aplicáveis para o console do Amazon Polly e escute as diferenças.
-
Usando o modo automatizado sem parâmetros opcionais.
<speak> <amazon:auto-breaths>Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech- enabled products. Amazon Polly is a text-to-speech service that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Usando o modo automatizado com controle de volume. O parâmetros não especificados (
durationefrequency) são definidos como os valores padrão (medium).<speak> <amazon:auto-breaths volume="x-soft">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Usando o modo automatizado com controle de frequência. O parâmetros não especificados (
durationevolume) são definidos como os valores padrão (medium).<speak> <amazon:auto-breaths frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Usando o modo automatizado com parâmetros opcionais. Para o parâmetro
Durationnão especificado, o Amazon Polly usa o valor padrão (medium).<speak> <amazon:auto-breaths volume="x-loud" frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech-enabled applications that work in many different countries.</amazon:auto-breaths> </speak>
Estilo de locutor
<amazon:domain name="news">
O estilo de locutor pode ser usado somente com as vozes de Matthew e Joanna, disponíveis apenas em inglês dos EUA (en-US), e Lupe em espanhol dos EUA (es-US). Ele só é compatível ao usar o formato Neural.
Para usar o estilo de locutor, use tags SSML e a seguinte sintaxe:
<amazon:domain name="news">text</amazon:domain>
Por exemplo, você poderá usar o estilo de locutor com a voz de Matthew da seguinte forma:
<speak> <amazon:domain name="news"> From the Tuesday, April 16th, 1912 edition of The Guardian newspaper: The maiden voyage of the White Star liner Titanic, the largest ship ever launched, has ended in disaster. The Titanic started her trip from Southampton for New York on Wednesday. Late on Sunday night she struck an iceberg off the Grand Banks of Newfoundland. By wireless telegraphy she sent out signals of distress, and several liners were near enough to catch and respond to the call. </amazon:domain> </speak>
Adicionar compactação de intervalo dinâmico
<amazon:effect name="drc">
Essa tag é compatível com os formatos TTS de forma longa, padrão e neural.
Dependendo do texto, do idioma e da voz usados em um arquivo de áudio, os sons variam de baixo a alto. Os sons ambientais, como o som de um veículo em movimento, muitas vezes podem ocultar os sons mais baixos, o que dificulta ouvir a faixa de áudio com clareza. Para aumentar o volume de determinados sons no seu arquivo de áudio, use a tag de compactação de alcance dinâmico (drc).
A tag drc define um limite de "intensidade" de médio alcance para seu áudio e aumenta o volume (o ganho) dos sons em torno desse limite. Ele aplica o maior aumento de ganho mais próximo do limiar, e o aumento de ganho é diminuído muito além do limiar.
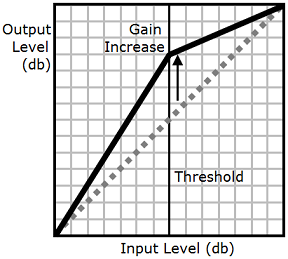
Isso facilita ouvir os sons de meio alcance em um ambiente com barulho, o que aumenta a clareza do arquivo de áudio todo.
A tag drc é um parâmetro booleano (presente ou ausente). Ela usa a sintaxe: <amazon:effect name="drc"> e é fechada com </amazon:effect>.
Você pode usar a tag drc com qualquer voz ou idioma compatível com o Amazon Polly. Você pode aplicá-la a uma seção inteira da gravação ou em apenas algumas palavras. Por exemplo: .
<speak> Some audio is difficult to hear in a moving vehicle, but <amazon:effect name="drc"> this audio is less difficult to hear in a moving vehicle.</amazon:effect> </speak>
nota
Quando você usa "drc" na sintaxe , há distinção entre letras maiúsculas e minúsculas.amazon:effect
Usar drc com a tag prosody
volume
Assim como mostra o gráfico a seguir, a tag prosody
volume aumenta uniformemente o volume de um arquivo de áudio inteiro a partir do nível original (linha pontilhada) até um nível ajustado (linha contínua). Para aumentar ainda mais o volume de certas partes do arquivo, use a tag drc com a tag prosody
volume. Combinar tags não afeta as configurações da tag prosody volume.
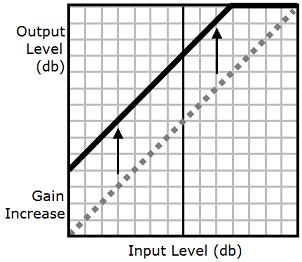
Ao usar as tags drc e prosody
volume em conjunto, o Amazon Polly aplica a tag drc primeiro, aumentando os sons de alcance médio (aqueles próximos ao limite). Em seguida, ele aplica a tag prosody volume e aumenta ainda mais o volume da faixa de áudio toda de forma uniforme.
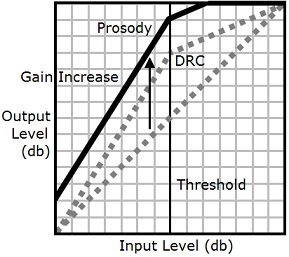
Para usar as tags em conjunto, aninhe uma dentro da outra. Por exemplo: .
<speak> <prosody volume="loud">This text needs to be understandable and loud. <amazon:effect name="drc"> This text also needs to be more understandable in a moving car.</amazon:effect></prosody> </speak>
Neste texto, a tag prosody volume aumenta o volume do trecho inteiro para "alto". A tag drc aprimora o volume de valores de alcance médio na segunda frase.
nota
Ao usar as tags drc e prosody
volume em conjunto, use as práticas de XML padrão para agrupar tags.
Falar suavemente
<amazon:effect phonation="soft">
No momento, essa tag é compatível somente com o formato TTS padrão.
Para especificar que o texto de entrada deve ser falado em softer-than-normal voz, use a <amazon:effect phonation="soft">tag.
Neste caso, usa-se sintaxe:
<amazon:effect phonation="soft">text</amazon:effect>Por exemplo, você pode usar essa tag com a voz de Matthew da seguinte forma:
<speak> This is Matthew speaking in my normal voice. <amazon:effect phonation="soft">This is Matthew speaking in my softer voice.</amazon:effect> </speak>
Controlar o timbre
<amazon : efeito > vocal-tract-length
No momento, essa tag é compatível somente com o formato TTS padrão.
Timbre é a qualidade tonal de uma voz que ajuda a distinguir a diferença entre as vozes, mesmo quando elas têm o mesmo tom e intensidade. Uma das características fisiológicas mais importantes que contribui com o timbre da fala timbre é o comprimento do trato vocal. O trato vocal é uma cavidade de ar que se estende desde o topo das pregas vocais até a borda dos lábios.
Para controlar o timbre da saída de fala no Amazon Polly, use a tag vocal-tract-length. Esta tag tem o efeito de alterar o comprimento do trato vocal do orador, que soa como uma alteração no tamanho do orador. Ao aumentar o vocal-tract-length, o orador soa fisicamente maior. Ao diminuí-lo, o orador soa menor. Você pode usar essa tag com qualquer uma das vozes do portfólio de texto para fala do Amazon Polly.
Para alterar o timbre, use os seguintes valores:
-
+n%ou-n%: ajusta comprimento do trato vocal por uma alteração percentual na voz atual. Por exemplo, +4% ou -2%. Os valores válidos variam de +100% a -50%. Valores fora deste intervalo são cortados. Por exemplo, sons +111%, como+100% e -60% soam como -50%. -
n%: altera o comprimento do trato vocal a uma porcentagem absoluta do comprimento do trato da voz atual. Por exemplo, 110% ou 75%. Um valor absoluto de 110% é equivalente a um valor relativo de +10%. Um valor absoluto de 100% é o mesmo que o valor padrão da voz atual.
O exemplo a seguir mostra como alterar o comprimento do trato vocal para alterar o timbre:
<speak> This is my original voice, without any modifications. <amazon:effect vocal-tract-length="+15%"> Now, imagine that I am much bigger. </amazon:effect> <amazon:effect vocal-tract-length="-15%"> Or, perhaps you prefer my voice when I'm very small. </amazon:effect> You can also control the timbre of my voice by making minor adjustments. <amazon:effect vocal-tract-length="+10%"> For example, by making me sound just a little bigger. </amazon:effect><amazon:effect vocal-tract-length="-10%"> Or, making me sound only somewhat smaller. </amazon:effect> </speak>
Combinar várias tags
Você pode combinar a tag vocal-tract-length com qualquer outra tag de SSML compatível com o Amazon Polly. Visto que o timbre (comprimento do trato vocal) e a altura estão intimamente conectados, você pode ter os melhores resultados usando ambas as tags vocal-tract-lengthe <prosody
pitch>. Para produzir a voz mais realista, recomendamos que você use diferentes porcentagens de alterações para as duas tags. Experimente com várias combinações para obter os resultados desejados.
O exemplo a seguir mostra como combinar tags.
<speak> The pitch and timbre of a person's voice are connected in human speech. <amazon:effect vocal-tract-length="-15%"> If you are going to reduce the vocal tract length, </amazon:effect><amazon:effect vocal-tract-length="-15%"> <prosody pitch="+20%"> you might consider increasing the pitch, too. </prosody></amazon:effect> <amazon:effect vocal-tract-length="+15%"> If you choose to lengthen the vocal tract, </amazon:effect> <amazon:effect vocal-tract-length="+15%"> <prosody pitch="-10%"> you might also want to lower the pitch. </prosody></amazon:effect> </speak>
Sussurrar
<amazon:effect name="whispered">
No momento, essa tag é compatível somente com o formato TTS padrão.
Essa tag indica que o texto de entrada deve ser falado em uma voz sussurrada, em vez da fala normal. Isso pode ser usado com qualquer uma das vozes do portfólio de texto para fala do Amazon Polly.
Neste caso, usa-se a seguinte sintaxe:
<amazon:effect name="whispered">text</amazon:effect>Por exemplo: .
<speak> <amazon:effect name="whispered">If you make any noise, </amazon:effect> she said, <amazon:effect name="whispered">they will hear us.</amazon:effect> </speak>
Neste caso, a fala sintetizada dita pelo personagem será sussurrada, mas a frase "Ela disse" será dita na fala normal sintetizada da voz do Amazon Polly selecionada.
É possível aprimorar o efeito "sussurro" diminuindo a velocidade da prosódia em até 10%, dependendo do efeito desejado.
Por exemplo: .
<speak> When any voice is made to whisper, <amazon:effect name="whispered"> <prosody rate="-10%">the sound is slower and quieter than normal speech </prosody></amazon:effect> </speak>
Ao gerar marcas de fala para uma voz sussurrada, o fluxo de áudio também deverá incluir a voz sussurrada para garantir que as marcas de fala correspondam ao fluxo de áudio.
