As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Gerenciamento de cache do gravador
O armazenamento em cache é um dos recursos mais importantes de qualquer banco de dados (DB) porque ajuda a reduzir a E/S do disco. Os dados acessados com mais frequência são armazenados em uma área de memória chamada cache de buffer. Quando uma consulta é executada com frequência, ela recupera os dados diretamente do cache em vez do disco. Isso é mais rápido e oferece melhor escalabilidade e desempenho do aplicativo. Você configura o tamanho do cache do PostgreSQL usando oshared_buffers parâmetro. Para obter mais informações, consulte Memória
Após um failover, o gerenciamento de cache de cluster (CCM) na edição compatível com o Amazon Aurora PostgreSQL foi projetado para melhorar o desempenho da recuperação de aplicativos e bancos de dados. Em uma situação de failover típica sem o CCM, você pode ver uma degradação de desempenho temporária, mas significativa. Isso ocorre porque quando a instância de banco de dados de failover é iniciada, o cache do buffer está vazio. Um cache vazio também é conhecido como um cache frio. A instância de banco de dados deve ler do disco, que é mais lento do que a leitura do cache.
Ao implementar o CCM, você escolhe uma instância de banco de dados de leitura preferida, e o CCM sincroniza continuamente sua memória cache com a da instância de banco de dados primária ou de gravação. Se ocorrer um failover, a instância de banco de dados de leitor da nova instância de banco de dados de gravador. Como ele já tem uma memória cache, conhecida como cache aquecido, isso minimiza o impacto do failover no desempenho do aplicativo.
Como funciona o gerenciamento de cache de cluster?
As instâncias de banco de dados de failover estão localizadas em zonas de disponibilidade diferentes da instância de banco de dados primária do gravador. A instância de banco de dados do leitor preferencial é o alvo prioritário de failover, que é especificado atribuindo-lhe o nível de prioridade de nível 0.
nota
A prioridade da camada de promoção é um valor que especifica a ordem em que um leitor do Aurora é promovido para a instância de banco de dados do leitor depois de uma falha. Os valores válidos são 0 – 15, em que 0 é a primeira prioridade, e 15 é a última prioridade. Para obter mais informações sobre a camada de promoção, consulte Tolerância a falhas para um cluster de banco de dados Aurora. modificar o nível de promoção não causa uma interrupção.
O CCM sincroniza o cache da instância de banco de dados do gravador para a instância de banco de dados de leitor de sua preferência. A instância de banco de dados do leitor envia o conjunto de endereços de buffer que estão atualmente armazenados em cache para a instância de banco de dados do gravador como um filtro bloom. Um filtro bloom é uma estrutura de dados probabilística e com baixo consumo de memória que é usada para testar se um elemento é membro de um conjunto. O uso de um filtro bloom impede que a instância de banco de dados do leitor envie os mesmos endereços de buffer para a instância de banco de dados do gravador repetidamente. Quando a instância de banco de dados do gravador recebe o filtro bloom, ela compara os blocos em seu cache de buffer e envia buffers usados com frequência para a instância de banco de dados do leitor. Por padrão, um buffer é considerado usado com frequência se tiver uma contagem de uso maior que três.
O diagrama a seguir mostra como o CCM sincroniza o cache de buffer da instância de banco de dados do gravador com a instância de banco de dados de leitura preferida.
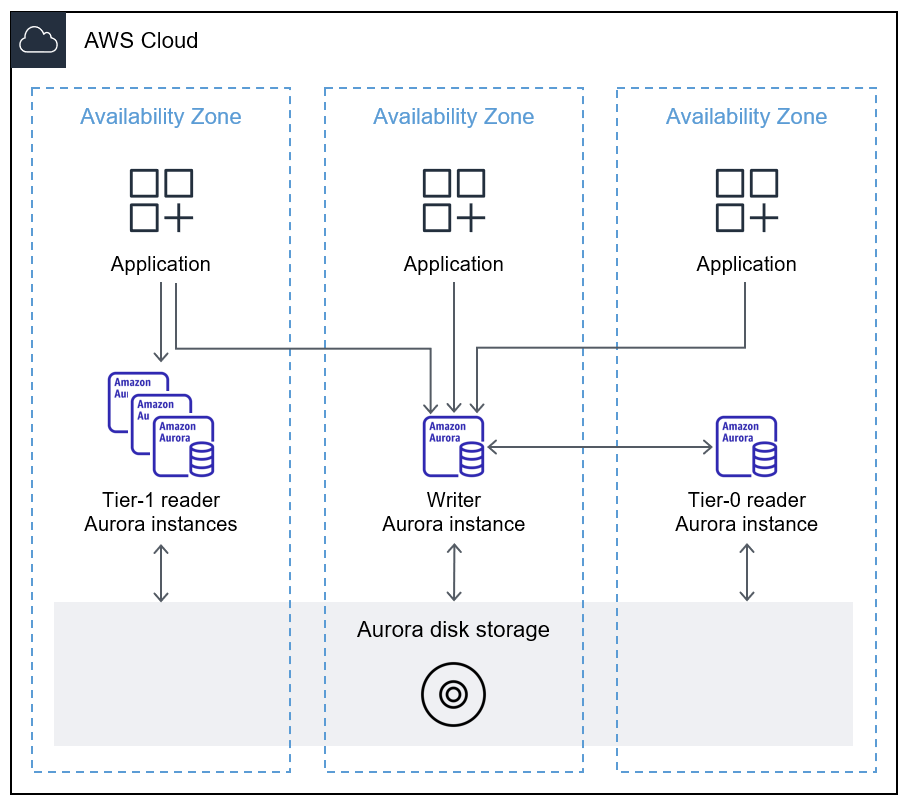
Para obter mais informações sobre o CCM, consulte Recuperação rápida após failover com gerenciamento de cache de cluster para Aurora PostgreSQL (documentação do Aurora) e Introdução ao gerenciamento de cache de cluster Aurora PostgreSQL
Limitações
O recurso do CCM tem as seguintes limitações:
-
A instância de banco de dados da instância de banco de dados da instância de banco de dados da instância de banco de dados da instância do gravador, como
r5.2xlargeoudb.r5.xlarge. -
Não há suporte ao CCM para clusters de banco de dados Aurora. PostgreSQL que fazem parte de bancos de dados globais do Aurora.
Casos de uso para gerenciamento de cache de cluster
Para alguns setores, como varejo, bancos e finanças, atrasos de apenas alguns milissegundos podem causar problemas de desempenho de aplicativos e resultar em uma perda significativa de negócios. Como o CCM ajuda a recuperar o desempenho do aplicativo e do banco de dados sincronizando continuamente o cache de buffer da instância primária do banco de dados com a instância de backup preferida, ele pode ajudar a evitar perdas comerciais associadas aos failovers.
