As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Etapa 1: identificar os casos de uso e o modelo lógico de dados
Uma empresa automotiva deseja criar um sistema de gerenciamento de componentes transacionais para armazenar e pesquisar todas as peças automotivas disponíveis e criar relacionamentos entre diferentes componentes e peças. Por exemplo, um carro contém várias baterias, cada bateria contém vários módulos de alto nível, cada módulo contém várias células e cada célula contém vários componentes de baixo nível.
Geralmente, para criar um modelo de relacionamento hierárquico, um banco de dados de grafos como o Amazon Neptune é uma escolha melhor. Em alguns casos, no entanto, o Amazon DynamoDB é a melhor alternativa para modelagem hierárquica de dados devido à sua flexibilidade, segurança, desempenho e escala.
Por exemplo, é possível criar um sistema em que 80 a 90% das consultas sejam transacionais no qual o DynamoDB se encaixe bem. Neste exemplo, os outros 10 a 20% das consultas são relacionais, onde um banco de dados gráfico como o Neptune se encaixa melhor. Nesse caso, incluir um banco de dados adicional na arquitetura para atender apenas 10 a 20% das consultas poderia aumentar o custo. Isso também aumenta a carga operacional de manter vários sistemas e sincronizar os dados. Em vez disso, você pode modelar essas consultas relacionais de 10 a 20% no DynamoDB.
Criar o diagrama de uma árvore de exemplo para componentes automotivos pode ajudar a mapear a relação entre eles. O diagrama a seguir mostra um gráfico de dependência com quatro níveis. O CM1 é o componente de nível superior. No caso do exemplo, o próprio carro. Ele tem dois subcomponentes para dois exemplos de baterias, CM2 e CM3. Cada bateria tem dois subcomponentes, que são os módulos. CM2 tem os módulos CM4 e CM5, enquanto CM3 tem os módulos CM6 e CM7. Cada módulo tem vários subcomponentes, que são as células. O módulo CM4 tem duas células, CM8 e CM9. CM5 tem uma célula, CM10. CM6 e CM7 ainda não têm células associadas.
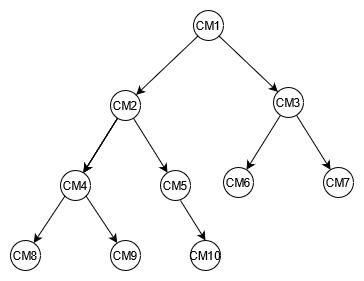
Este guia usará essa árvore e seus identificadores de componentes como referência. Um componente superior será chamado de pai, enquanto um subcomponente será chamado de filho. Por exemplo, o componente principal CM1 é pai de CM2 e CM3. CM2 é pai de CM4 e CM5. Isso representa graficamente os relacionamentos entre pais e filhos.
Na árvore, é possível ver o gráfico completo de dependências de um componente. Por exemplo, CM8 depende de CM4 que depende de CM2 que depende de CM1. A árvore define o gráfico de dependências completo como o caminho. Um caminho descreve duas coisas:
-
O gráfico de dependências
-
A posição na árvore
Preenchendo os modelos para os requisitos de negócios:
Forneça informações sobre seus usuários:
Usuário |
Descrição |
Funcionário |
Funcionário interno da empresa automotiva que precisa de informações sobre carros e seus componentes |
Forneça informações sobre as fontes de dados e como os dados serão ingeridos:
Origem |
Descrição |
Usuário |
Sistema de gestão |
Sistema que armazenará todos os dados relacionados às peças automotivas disponíveis e suas relações com outros componentes e peças. |
Funcionário |
Forneça informações sobre como os dados serão consumidos:
Consumidor |
Descrição |
Usuário |
Sistema de gestão |
Recupere todos os componentes secundários imediatos para um ID de componente pai. |
Funcionário |
Sistema de gestão |
Recupere uma lista recursiva de todos os componentes secundários para um ID de componente. |
Funcionário |
Sistema de gestão |
Veja os ancestrais de um componente. |
Funcionário |
