As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Grupos de disponibilidade distribuídos
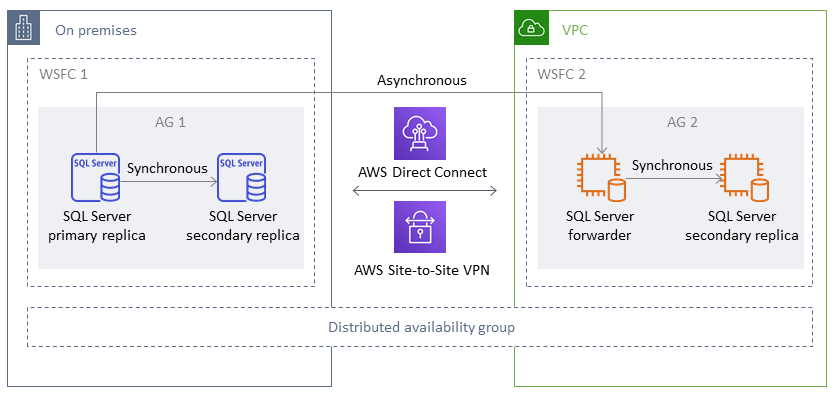
Um grupo de disponibilidade distribuído abrange dois grupos de disponibilidade separados. Você pode pensar nisso como um grupo de disponibilidade de grupos de disponibilidade. Os grupos de disponibilidade subjacentes são configurados em dois clusters WSFC diferentes. Os grupos de disponibilidade que participam de um grupo de disponibilidade distribuído não precisam compartilhar o mesmo local. Eles podem ser físicos ou virtuais, on-premises ou na nuvem pública. Os grupos de disponibilidade em um grupo de disponibilidade distribuído não precisam executar a mesma versão do SQL Server. A instância de banco de dados de destino pode executar uma versão posterior do SQL Server que a instância de banco de dados de origem.
Uma arquitetura de grupo de disponibilidade distribuída oferece uma maneira flexível de rehospedar uma instância ou banco de dados essencial do SQL Server em. AWS Ele fornece uma solução híbrida para o lift and shift (ou lift and transform) de seus bancos de dados essenciais do SQL Server no AWS.
Usar uma arquitetura de grupo de disponibilidade distribuída é mais eficiente do que estender os clusters WFSC locais existentes para o. AWS Os dados são transferidos somente do primário local para uma das AWS réplicas (o encaminhador). O encaminhador é responsável por enviar dados para outras réplicas de leitura secundárias em. AWS
No diagrama a seguir, o primeiro cluster WSFC (WSFC 1) está hospedado on-premises e tem um grupo de disponibilidade locais (AG 1). O segundo cluster WSFC (WSFC 2) está hospedado AWS e tem um grupo de AWS disponibilidade (AG 2). Direct Connect
nota
Em qualquer dado momento, há apenas um banco de dados disponível para operações de gravação. Você pode usar as réplicas secundárias restantes para operações de leitura. Para aumentar a escala horizontalmente de suas cargas de trabalho de leitura, você pode adicionar mais réplicas de leitura em várias zonas de disponibilidade no AWS.
Para obter mais informações sobre grupos de disponibilidade distribuídos, consulte:
-
Como arquitetar uma solução híbrida do Microsoft SQL Server usando grupos de disponibilidade distribuídos
no blog AWS Database -
Migre o SQL Server para o AWS uso de grupos de disponibilidade distribuídos no site de Orientação AWS Prescritiva
