As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Desenvolva um assistente baseado em bate-papo totalmente automatizado usando agentes e bases de conhecimento do Amazon Bedrock
Criado por Jundong Qiao (AWS), Kara Yang (AWS), Kiowa Jackson (AWS), Noah Hamilton (AWS), Praveen Kumar Jeyarajan (AWS) e Shuai Cao (AWS)
Resumo
Muitas organizações enfrentam desafios ao criar um assistente baseado em bate-papo capaz de orquestrar diversas fontes de dados para oferecer respostas abrangentes. Esse padrão apresenta uma solução para o desenvolvimento de um assistente baseado em bate-papo capaz de responder consultas de documentação e bancos de dados, com uma implantação simples.
Começando com o Amazon Bedrock, esse serviço de inteligência artificial generativa (IA) totalmente gerenciado fornece uma ampla variedade de modelos básicos avançados (FMs). Isso facilita a criação eficiente de aplicativos generativos de IA com um forte foco em privacidade e segurança. No contexto da recuperação de documentação, a Geração Aumentada de Recuperação (RAG) é um recurso fundamental. Ele usa bases de conhecimento para aumentar as solicitações de FM com informações contextualmente relevantes de fontes externas. Um índice Amazon OpenSearch Serverless serve como banco de dados vetorial por trás das bases de conhecimento do Amazon Bedrock. Essa integração é aprimorada por meio de uma engenharia rápida e cuidadosa para minimizar imprecisões e garantir que as respostas estejam ancoradas na documentação factual. Para consultas de banco FMs de dados, o Amazon Bedrock transforma consultas textuais em consultas SQL estruturadas, incorporando parâmetros específicos. Isso permite a recuperação precisa de dados de bancos de dados gerenciados pelos bancos de dados AWS Glue. O Amazon Athena é usado para essas consultas.
Para lidar com consultas mais complexas, obter respostas abrangentes exige informações provenientes de documentação e bancos de dados. Agents for Amazon Bedrock é um recurso generativo de IA que ajuda você a criar agentes autônomos capazes de entender tarefas complexas e dividi-las em tarefas mais simples para orquestração. A combinação de insights recuperados das tarefas simplificadas, facilitada pelos agentes autônomos do Amazon Bedrock, aprimora a síntese das informações, levando a respostas mais completas e exaustivas. Esse padrão demonstra como criar um assistente baseado em bate-papo usando o Amazon Bedrock e os serviços e recursos de IA generativa relacionados em uma solução automatizada.
Pré-requisitos e limitações
Pré-requisitos
Uma conta AWS ativa
Kit de Desenvolvimento da Nuvem AWS (AWS CDK), instalado e inicializado nas regiões da AWS
us-east-1us-west-2AWS Command Line Interface (AWS CLI), instalada e configurada
No Amazon Bedrock, habilite o acesso a Claude 2, Claude 2.1, Claude Instant e Titan Embeddings G1 — Text
Limitações
Essa solução é implantada em uma única conta da AWS.
Essa solução pode ser implantada somente nas regiões da AWS nas quais o Amazon Bedrock e o Amazon OpenSearch Serverless são compatíveis. Para obter mais informações, consulte a documentação do Amazon Bedrock e do Amazon OpenSearch Serverless.
Versões do produto
Índice LLAMA versão 0.10.6 ou posterior
Sqlalchemy versão 2.0.23 ou posterior
OpenSearch-py versão 2.4.2 ou posterior
requests_aws4auth versão 1.2.3 ou posterior
SDK da AWS para Python (Boto3) versão 1.34.57 ou posterior
Arquitetura
Pilha de tecnologias de destino
O AWS Cloud Development Kit (AWS CDK) é uma estrutura de desenvolvimento de software de código aberto para definir a infraestrutura de nuvem em código e provisioná-la por meio da AWS. CloudFormation A pilha de CDK da AWS usada nesse padrão implanta os seguintes recursos da AWS:
AWS Key Management Service (AWS KMS)
Amazon Simple Storage Service (Amazon S3)
Catálogo de dados do AWS Glue, para o componente de banco de dados do AWS Glue
AWS Lambda
AWS Identity and Access Management (IAM)
Amazon sem OpenSearch servidor
Amazon Elastic Container Registry (Amazon ECR)
Amazon Elastic Container Service (Amazon ECS)
AWS Fargate
Amazon Virtual Private Cloud (Amazon VPC)
Arquitetura de destino
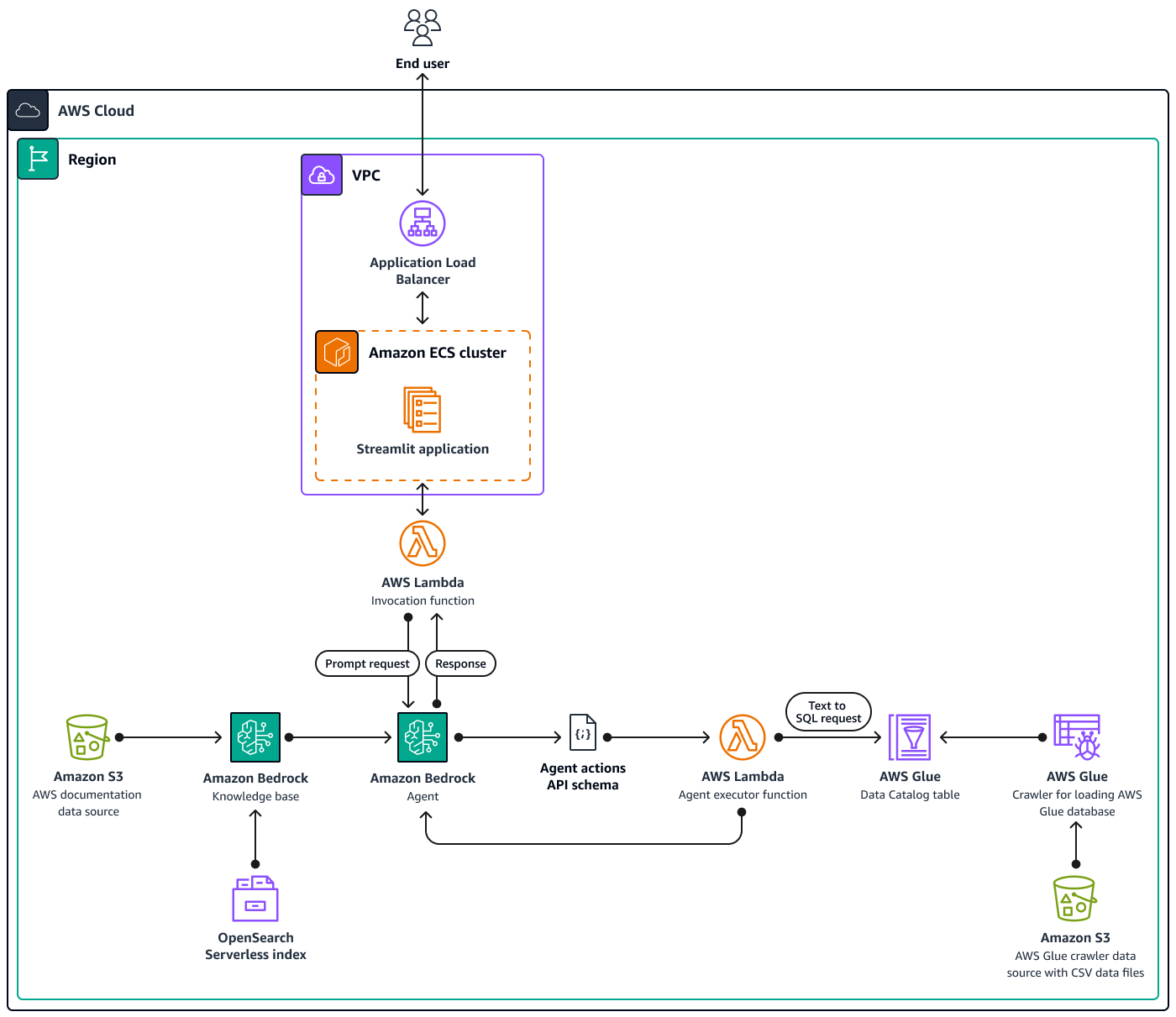
O diagrama mostra uma configuração abrangente nativa da nuvem da AWS em uma única região da AWS, usando vários serviços da AWS. A interface principal do assistente baseado em bate-papo é um aplicativo StreamlitInvocation Lambda, que então interage com os agentes do Amazon Bedrock. Esse agente responde às perguntas dos usuários consultando as bases de conhecimento do Amazon Bedrock ou invocando uma Agent executor função Lambda. Essa função aciona um conjunto de ações associadas ao agente, seguindo um esquema de API predefinido. As bases de conhecimento do Amazon Bedrock usam um índice OpenSearch Serverless como base de banco de dados vetorial. Além disso, a Agent executor função gera consultas SQL que são executadas no banco de dados AWS Glue por meio do Amazon Athena.
Ferramentas
Serviços da AWS
O Amazon Athena é um serviço de consultas interativas que permite analisar dados diretamente no Amazon Simple Storage Service (Amazon S3) usando SQL padrão.
O Amazon Bedrock é um serviço totalmente gerenciado que disponibiliza modelos básicos de alto desempenho (FMs) das principais startups de IA e da Amazon para seu uso por meio de uma API unificada.
O AWS Cloud Development Kit (AWS CDK) é uma estrutura de desenvolvimento de software que ajuda você a definir e provisionar a infraestrutura da Nuvem AWS em código.
A AWS Command Line Interface (AWS CLI) é uma ferramenta de código aberto que ajuda você a interagir com os serviços da AWS por meio de comandos em seu shell de linha de comando.
O Amazon Elastic Container Service (Amazon ECS) é um serviço de gerenciamento de contêineres escalável e rápido que facilita a execução, a interrupção e o gerenciamento de contêineres em um cluster.
O Elastic Load Balancing (ELB) distribui o tráfego de entrada de aplicativos ou de rede em vários destinos. Por exemplo, você pode distribuir tráfego entre instâncias, contêineres e endereços IP do Amazon Elastic Compute Cloud (Amazon EC2) em uma ou mais zonas de disponibilidade.
O AWS Glue é um serviço de extração, transformação e carregamento (ETL) totalmente gerenciado. Ele ajuda você a categorizar de forma confiável, limpar, enriquecer e mover dados de forma confiável entre armazenamento de dados e fluxos de dados. Esse padrão usa um crawler do AWS Glue e uma tabela do Catálogo de Dados do AWS Glue.
O AWS Lambda é um serviço de computação que ajuda você a executar código sem exigir provisionamento ou gerenciamento de servidores. Ele executa o código somente quando necessário e dimensiona automaticamente, assim, você paga apenas pelo tempo de computação usado.
O Amazon OpenSearch Serverless é uma configuração sem servidor sob demanda para o Amazon Service. OpenSearch Nesse padrão, um índice OpenSearch sem servidor serve como um banco de dados vetorial para as bases de conhecimento do Amazon Bedrock.
O Amazon Simple Storage Service (Amazon S3) é um serviço de armazenamento de objetos baseado na nuvem que ajuda você a armazenar, proteger e recuperar qualquer quantidade de dados.
Outras ferramentas
Streamlit
é uma estrutura Python de código aberto para criar aplicativos de dados.
Repositório de código
O código desse padrão está disponível no GitHub genai-bedrock-agent-chatbot
assetspasta — Os ativos estáticos, como o diagrama de arquitetura e o conjunto de dados público.code/lambdas/action-lambdapasta — O código Python para a função Lambda que atua como uma ação para o agente Amazon Bedrock.code/lambdas/create-index-lambdapasta — O código Python para a função Lambda que cria o índice Serverless. OpenSearchcode/lambdas/invoke-lambdapasta — O código Python para a função Lambda que invoca o agente Amazon Bedrock, que é chamado diretamente do aplicativo Streamlit.code/lambdas/update-lambdapasta — O código Python para a função Lambda que atualiza ou exclui recursos depois que os recursos da AWS são implantados por meio do AWS CDK.code/layers/boto3_layerpasta — A pilha de CDK da AWS que cria uma camada de Boto3 que é compartilhada entre todas as funções do Lambda.code/layers/opensearch_layerpasta — A pilha de CDK da AWS que cria uma camada OpenSearch sem servidor que instala todas as dependências para criar o índice.code/streamlit-apppasta — O código Python que é executado como imagem de contêiner no Amazon ECScode/code_stack.py— O AWS CDK constrói arquivos Python que criam recursos da AWS.app.py— O AWS CDK empilha arquivos Python que implantam recursos da AWS na conta de destino da AWS.requirements.txt— A lista de todas as dependências do Python que devem ser instaladas para o AWS CDK.cdk.json— O arquivo de entrada para fornecer os valores necessários para criar recursos. Além disso, noscontext/configcampos, você pode personalizar a solução adequadamente. Para obter mais informações sobre personalização, consulte a seção Informações adicionais.
Práticas recomendadas
O exemplo de código fornecido aqui é apenas para fins proof-of-concept (PoC) ou piloto. Se você quiser levar o código para produção, certifique-se de usar as seguintes práticas recomendadas:
Ativar o registro de acesso ao Amazon S3
Habilitar registros de fluxo de VPC
Configure o monitoramento e os alertas para as funções do Lambda. Para obter mais informações, consulte Monitorar e solucionar problemas de funções do Lambda. Para obter as melhores práticas, consulte as melhores práticas para trabalhar com as funções do AWS Lambda.
Épicos
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Exporte variáveis para a conta e a região. | Para fornecer credenciais da AWS para o AWS CDK usando variáveis de ambiente, execute os seguintes comandos.
| AWS DevOps, DevOps engenheiro |
Configure o perfil nomeado da AWS CLI. | Para configurar o perfil nomeado da AWS CLI para a conta, siga as instruções em Configuração e configurações do arquivo de credenciais. | AWS DevOps, DevOps engenheiro |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Clone o repositório em sua estação de trabalho local. | Para clonar o repositório, execute o comando a seguir no seu terminal.
| DevOps engenheiro, AWS DevOps |
Configure o ambiente virtual Python. | Para ativar o ambiente virtual do Python, execute os comandos a seguir.
Para configurar as dependências necessárias, execute o comando a seguir.
| DevOps engenheiro, AWS DevOps |
Configure o ambiente do AWS CDK. | Para converter o código em um CloudFormation modelo da AWS, execute o comando | AWS DevOps, DevOps engenheiro |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Implante recursos na conta. | Para implantar recursos na conta da AWS usando o AWS CDK, faça o seguinte:
Após a implantação bem-sucedida, você pode acessar o aplicativo assistente baseado em bate-papo usando a URL fornecida na guia Saídas no console. CloudFormation | DevOps engenheiro, AWS DevOps |
| Tarefa | Descrição | Habilidades necessárias |
|---|---|---|
Remova os recursos da AWS. | Depois de testar a solução, para limpar os recursos, execute o comando | AWS DevOps, DevOps engenheiro |
Recursos relacionados
Documentação da AWS
Recursos do Amazon Bedrock:
Recursos do AWS CDK:
Outros recursos da AWS
Outros recursos
Mais informações
Personalize o assistente baseado em bate-papo com seus próprios dados
Para integrar seus dados personalizados para implantar a solução, siga estas diretrizes estruturadas. Essas etapas foram projetadas para garantir um processo de integração contínuo e eficiente, permitindo que você implante a solução de forma eficaz com seus dados personalizados.
Para integração de dados da base de conhecimento
Preparação de dados
Localize o
assets/knowledgebase_data_source/diretório.Coloque seu conjunto de dados nessa pasta.
Ajustes de configuração
Abra o arquivo
cdk.json.Navegue até o
context/configure/paths/knowledgebase_file_namecampo e, em seguida, atualize-o adequadamente.Navegue até o
bedrock_instructions/knowledgebase_instructioncampo e atualize-o para refletir com precisão as nuances e o contexto do seu novo conjunto de dados.
Para integração de dados estruturais
Organização de dados
Dentro do
assets/data_query_data_source/diretório, crie um subdiretório, comotabular_data.Coloque seu conjunto de dados estruturado (formatos aceitáveis incluem CSV, JSON, ORC e Parquet) nessa subpasta recém-criada.
Se você estiver se conectando a um banco de dados existente, atualize a função
create_sql_engine()code/lambda/action-lambda/build_query_engine.pypara se conectar ao seu banco de dados.
Atualizações de configuração e código
No
cdk.jsonarquivo, atualize ocontext/configure/paths/athena_table_data_prefixcampo para alinhar com o novo caminho de dados.Revise
code/lambda/action-lambda/dynamic_examples.csvincorporando novos text-to-SQL exemplos que correspondam ao seu conjunto de dados.Revise
code/lambda/action-lambda/prompt_templates.pypara espelhar os atributos do seu conjunto de dados estruturado.No
cdk.jsonarquivo, atualize ocontext/configure/bedrock_instructions/action_group_descriptioncampo para explicar a finalidade e a funcionalidade da funçãoAction groupLambda.No
assets/agent_api_schema/artifacts_schema.jsonarquivo, explique as novas funcionalidadesAction groupda sua função Lambda.
Atualização geral
No cdk.json arquivo, na context/configure/bedrock_instructions/agent_instruction seção, forneça uma descrição abrangente da funcionalidade pretendida e da finalidade do design do agente Amazon Bedrock, levando em consideração os dados recém-integrados.
