As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Migre dados de um ambiente Hadoop local para o Amazon S3 usando with for Amazon S3 DistCp AWS PrivateLink
Criado por Jason Owens (AWS), Andres Cantor (), Jeff Klopfenstein (AWS), Bruno Rocha Oliveira (AWS) e Samuel Schmidt () AWS AWS
Resumo
Esse padrão demonstra como migrar praticamente qualquer quantidade de dados de um ambiente Apache Hadoop local para a nuvem Amazon Web Services (AWS) usando a ferramenta de código aberto Apache DistCpcom o Amazon Simple Storage Service (Amazon AWS PrivateLink S3). Em vez de usar a Internet pública ou uma solução de proxy para migrar dados, você pode usar o Amazon S3 AWS PrivateLink para migrar dados para o Amazon S3 por meio de uma conexão de rede privada entre seu datacenter local e uma Amazon Virtual Private Cloud (Amazon). VPC Se você usar DNS entradas no Amazon Route 53 ou adicionar entradas no arquivo /etc/hosts em todos os nós do seu cluster Hadoop local, você será automaticamente direcionado para o endpoint de interface correto.
Este guia fornece instruções de uso DistCp para migrar dados para a AWS nuvem. DistCp é a ferramenta mais usada, mas outras ferramentas de migração estão disponíveis. Por exemplo, você pode usar AWS ferramentas off-line, como AWSSnowball ou AWSSnowmobile, ou ferramentas on-line, como AWS Storage Gateway AWS ou. AWS DataSync Além disso, você pode usar outras ferramentas de código aberto, como o NiFiApache.
Pré-requisitos e limitações
Pré-requisitos
Uma AWS conta ativa com uma conexão de rede privada entre seu data center local e a nuvem AWS
Hadoop, instalado localmente com DistCp
Um usuário do Hadoop com acesso aos dados de migração no Hadoop Distributed File System () HDFS
AWSInterface de linha de comando (AWSCLI), instalada e configurada
Permissões para colocar objetos em um bucket do S3
Limitações
As limitações da nuvem privada virtual (VPC) se aplicam AWS PrivateLink ao Amazon S3. Para obter mais informações, consulte Propriedades e limitações do endpoint de interface e AWS PrivateLink cotas (AWS PrivateLink documentação).
AWS PrivateLink para Amazon S3 não oferece suporte ao seguinte:
Arquitetura
Pilha de tecnologia de origem
Pilha de tecnologias de destino
Arquitetura de destino
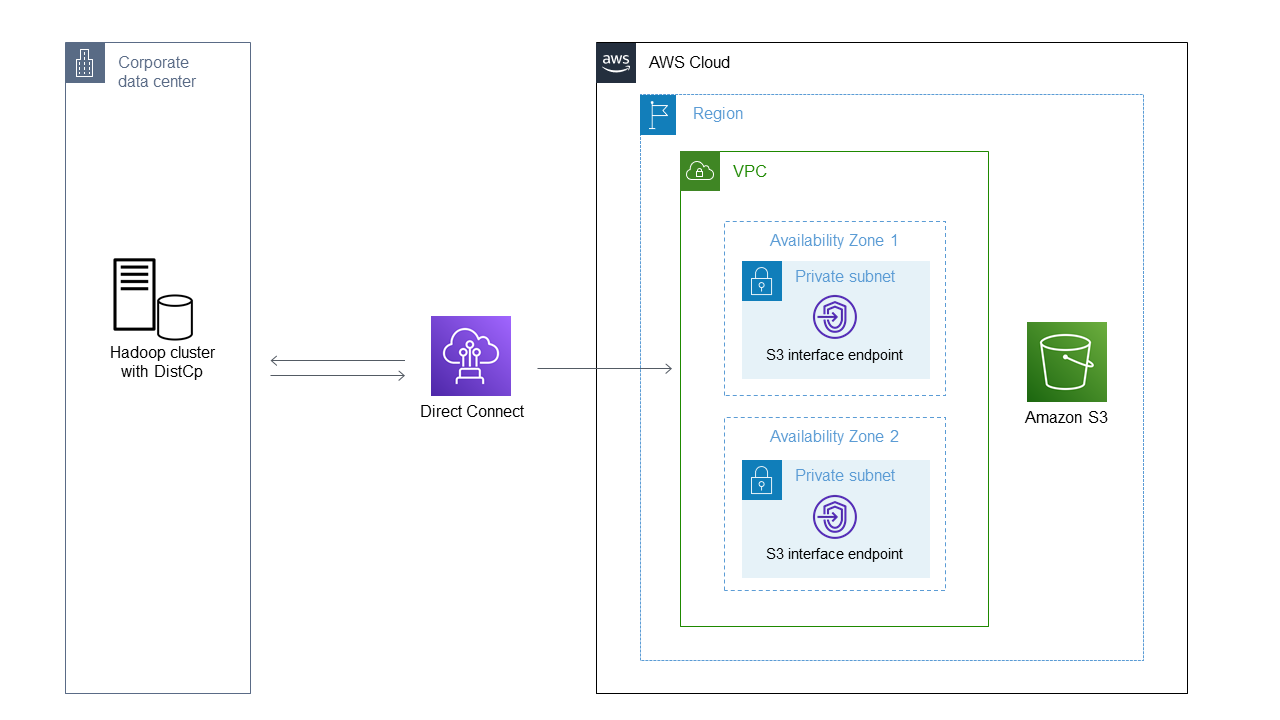
O diagrama mostra como o administrador do Hadoop usa DistCp para copiar dados de um ambiente local por meio de uma conexão de rede privada, como o AWS Direct Connect, para o Amazon S3 por meio de um endpoint de interface do Amazon S3.
Serviços do AWS
AWSO Identity and Access Management (IAM) ajuda você a gerenciar com segurança o acesso aos seus AWS recursos controlando quem está autenticado e autorizado a usá-los.
O Amazon Simple Storage Service (Amazon S3) é um serviço de armazenamento de objetos baseado na nuvem que ajuda você a armazenar, proteger e recuperar qualquer quantidade de dados.
A Amazon Virtual Private Cloud (AmazonVPC) ajuda você a lançar AWS recursos em uma rede virtual que você definiu. Essa rede virtual é semelhante a uma rede tradicional que você operaria no próprio datacenter, com os benefícios de usar a infraestrutura escalável da AWS.
Outras ferramentas
Épicos
| Tarefa | Descrição | Habilidades necessárias |
|---|
Crie um endpoint AWS PrivateLink para o Amazon S3. | Faça login no AWS Management Console e abra o VPCconsole da Amazon. No painel de navegação, selecione Endpoints e Criar endpoint. Em Categoria do serviço, escolha Serviços do AWS. Na caixa de pesquisa, digite s3 e pressione Enter. Nos resultados da pesquisa, escolha com.amazonaws. < your-aws-region >.s3 nome do serviço em que o valor na coluna Tipo é Interface. Para VPC, escolha o seuVPC. Em Sub-redes, escolha sua sub-rede. Em Grupo de segurança, escolha ou crie um grupo de segurança que permita TCP 443. Adicione tags com base em seus requisitos e escolha Criar endpoint.
| Administrador da AWS |
Verifique os endpoints e encontre as DNS entradas. | Abra o VPCconsole da Amazon, escolha Endpoints e selecione o endpoint que você criou anteriormente. Na guia Detalhes, encontre a primeira DNS entrada para DNSnomes. Esta é a DNS entrada regional. Quando você usa esse DNS nome, as solicitações alternam entre DNS as entradas específicas das zonas de disponibilidade. Escolha a guia Sub-redes. Você pode encontrar o endereço da interface de rede elástica do endpoint em cada zona de disponibilidade.
| Administrador da AWS |
Verifique as regras do firewall e as configurações de roteamento. | Para confirmar se suas regras de firewall estão abertas e se sua configuração de rede está configurada corretamente, use o Telnet para testar o endpoint na porta 443. Por exemplo: $ telnet vpce-<your-VPC-endpoint-ID>.s3.us-east-2.vpce.amazonaws.com 443
Trying 10.104.88.6...
Connected to vpce-<your-VPC-endpoint-ID>.s3.us-east-2.vpce.amazonaws.com.
...
$ telnet vpce-<your-VPC-endpoint-ID>.s3.us-east-2.vpce.amazonaws.com 443
Trying 10.104.71.141...
Connected to vpce-<your-VPC-endpoint-ID>.s3.us-east-2.vpce.amazonaws.com.
Se você usar a entrada Regional, um teste bem-sucedido mostra que DNS há alternância entre os dois endereços IP que você pode ver na guia Sub-redes do endpoint selecionado no console da Amazon. VPC | Administrador de rede, AWS administrador |
Configure a resolução de nomes. | Você deve configurar a resolução de nomes para permitir que o Hadoop acesse o endpoint da interface Amazon S3. Não é possível usar o nome do endpoint em si. Em vez disso, você deve resolver <your-bucket-name>.s3.<your-aws-region>.amazonaws.com ou*.s3.<your-aws-region>.amazonaws.com. Para obter mais informações sobre essa limitação de nomenclatura, consulte Apresentando o cliente Hadoop S3A (site do Hadoop). Escolha uma das seguintes opções de configuração: Use no local DNS para resolver o endereço IP privado do endpoint. Você pode substituir o comportamento de todos os compartimentos ou dos compartimentos selecionados. Para obter mais informações, consulte “Opção 2: acessar o Amazon S3 usando zonas de política de resposta do sistema de nomes de domínio (DNSRPZ)” em Acesso híbrido seguro ao Amazon S3 AWS PrivateLink usando AWS (postagem do blog). Configure o local DNS para encaminhar condicionalmente o tráfego para os endpoints de entrada do resolvedor no. VPC O tráfego é encaminhado para a Route 53. Para obter mais informações, consulte “Opção 3: Encaminhamento de DNS solicitações locais usando endpoints de entrada do Amazon Route 53 Resolver” em Acesso híbrido seguro ao Amazon S3 usando AWS PrivateLink (postagem do blog). AWS Edite o arquivo /etc/hosts em todos os nós do seu cluster do Hadoop. Essa é uma solução temporária para testes e não é recomendada para produção. Para editar o arquivo /etc/hosts, adicione uma entrada para <your-bucket-name>.s3.<your-aws-region>.amazonaws.com ou s3.<your-aws-region>.amazonaws.com. O arquivo /etc/hosts não pode ter vários endereços IP para uma entrada. Você deve escolher um único endereço IP de uma das zonas de disponibilidade, que então se torna um único ponto de falha.
| Administrador da AWS |
Configure a autenticação para o Amazon S3. | Para se autenticar no Amazon S3 por meio do Hadoop, recomendamos que você exporte credenciais de função temporárias para o ambiente do Hadoop. Para obter mais informações, consulte Autenticação com o S3 (site do Hadoop). Para trabalhos de longa duração, você pode criar um usuário e atribuir uma política que tenha permissões para colocar dados somente em um bucket do S3. A chave de acesso e a chave secreta podem ser armazenadas no Hadoop, acessíveis somente para o DistCp trabalho em si e para o administrador do Hadoop. Para obter mais informações sobre como armazenar segredos, consulte Armazenamento de segredos com provedores de credenciais do Hadoop (site do Hadoop). Para obter mais informações sobre outros métodos de autenticação, consulte Como obter credenciais de uma IAM função para uso com CLI acesso a uma AWS conta na documentação do AWS IAM Identity Center (sucessor do AWS Single Sign-On). Para usar credenciais temporárias, adicione as credenciais temporárias ao seu arquivo de credenciais ou execute os seguintes comandos para exportar as credenciais para o seu ambiente: export AWS_SESSION_TOKEN=SECRET-SESSION-TOKEN
export AWS_ACCESS_KEY_ID=SESSION-ACCESS-KEY
export AWS_SECRET_ACCESS_KEY=SESSION-SECRET-KEY
Se você tiver uma combinação tradicional de chave de acesso e chave secreta, execute os seguintes comandos: export AWS_ACCESS_KEY_ID=my.aws.key
export AWS_SECRET_ACCESS_KEY=my.secret.key
Se você usar uma combinação de chave de acesso e chave secreta, altere o provedor de credenciais nos DistCp comandos de "org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider" para"org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider". | Administrador da AWS |
Transfira dados usando DistCp. | Para usar DistCp para transferir dados, execute os seguintes comandos: hadoop distcp -Dfs.s3a.aws.credentials.provider=\
"org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider" \
-Dfs.s3a.access.key="${AWS_ACCESS_KEY_ID}" \
-Dfs.s3a.secret.key="${AWS_SECRET_ACCESS_KEY}" \
-Dfs.s3a.session.token="${AWS_SESSION_TOKEN}" \
-Dfs.s3a.path.style.access=true \
-Dfs.s3a.connection.ssl.enabled=true \
-Dfs.s3a.endpoint=s3.<your-aws-region>.amazonaws.com \
hdfs:///user/root/ s3a://<your-bucket-name>
A AWS região do endpoint não é descoberta automaticamente quando você usa o DistCp comando com AWS PrivateLink o Amazon S3. O Hadoop 3.3.2 e versões posteriores resolvem esse problema ativando a opção de definir explicitamente a AWS região do bucket do S3. Para obter mais informações, consulte S3A para adicionar a opção fs.s3a.endpoint.region para definir a região (site do Hadoop). AWS Para obter mais informações sobre provedores S3A adicionais, consulte Configuração geral do cliente S3A (site do Hadoop). Por exemplo, se você usa criptografia, pode adicionar a seguinte opção à série de comandos acima, dependendo do seu tipo de criptografia: -Dfs.s3a.server-side-encryption-algorithm=AES-256 [or SSE-C or SSE-KMS]
Para usar o endpoint da interface com o S3A, você deve criar uma entrada de DNS alias para o nome regional do S3 (por exemplo,s3.<your-aws-region>.amazonaws.com) para o endpoint da interface. Consulte a seção Configurar autenticação para o Amazon S3 para obter instruções. Essa solução alternativa é necessária para o Hadoop 3.3.2 e versões anteriores. Versões futuras do S3A não exigirão essa solução alternativa. Se você tiver problemas de assinatura com o Amazon S3, adicione uma opção de usar a Signature Version 4 (SigV4): -Dmapreduce.map.java.opts="-Dcom.amazonaws.services.s3.enableV4=true"
| Engenheiro de migração, AWS administrador |