As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Otimize os embaralhos
Certas operações, como join() egroupByKey(), exigem que o Spark execute uma operação aleatória. O shuffle é o mecanismo do Spark para redistribuir dados para que sejam agrupados de forma diferente nas partições. RDD O embaralhamento pode ajudar a corrigir gargalos de desempenho. No entanto, como o embaralhamento geralmente envolve a cópia de dados entre os executores do Spark, o embaralhamento é uma operação complexa e cara. Por exemplo, os embaralhos geram os seguintes custos:
-
E/S de disco:
-
Gera um grande número de arquivos intermediários no disco.
-
-
E/S de rede:
-
Precisa de muitas conexões de rede (Número de conexões =
Mapper × Reducer). -
Como os registros são agregados a novas RDD partições que podem estar hospedadas em outro executor do Spark, uma fração substancial do seu conjunto de dados pode ser transferida entre os executores do Spark pela rede.
-
-
CPUe carga de memória:
-
Classifica valores e mescla conjuntos de dados. Essas operações são planejadas no executor, sobrecarregando o executor.
-
O shuffle é um dos fatores mais importantes na degradação do desempenho do seu aplicativo Spark. Ao armazenar os dados intermediários, ele pode esgotar espaço no disco local do executor, o que faz com que a tarefa do Spark falhe.
Você pode avaliar seu desempenho aleatório nas CloudWatch métricas e na interface do usuário do Spark.
CloudWatch métricas
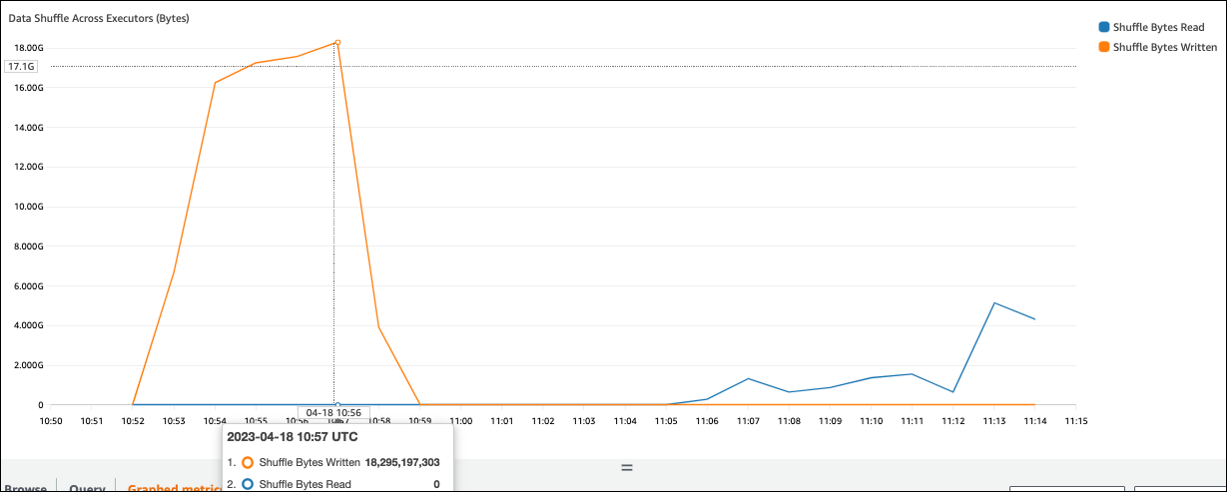
Se o valor do Shuffle Bytes Written for alto em comparação com o Shuffle Bytes Read, sua tarefa do Spark poderá usar operações aleatóriasjoin() groupByKey()
IU do Spark
Na guia Stage da interface do Spark, você pode verificar os valores Shuffle Read Size /Records. Você também pode vê-lo na guia Executors.
Na captura de tela a seguir, cada executor troca aproximadamente 18,6 GB/4020.000 registros com o processo aleatório, para um tamanho total de leitura aleatória de cerca de 75 GB).
A coluna Shuffle Spill (Disco) mostra uma grande quantidade de dados derramados de memória para o disco, o que pode causar um disco cheio ou um problema de desempenho.

Se você observar esses sintomas e o estágio demorar muito em comparação com suas metas de desempenho, ou se ele falhar Out Of Memory ou apresentar No space
left on device erros, considere as soluções a seguir.
Otimize a união
A join() operação, que une tabelas, é a operação aleatória mais usada, mas geralmente é um gargalo de desempenho. Como a união é uma operação cara, recomendamos não usá-la, a menos que seja essencial para suas necessidades comerciais. Verifique se você está fazendo uso eficiente do seu pipeline de dados fazendo as seguintes perguntas:
-
Você está recomputando uma junção que também é executada em outras tarefas que você pode reutilizar?
-
Você está se unindo para resolver chaves estrangeiras para valores que não são usados pelos consumidores de sua saída?
Depois de confirmar que suas operações de junção são essenciais para seus requisitos de negócios, consulte as opções a seguir para otimizar sua união de uma forma que atenda às suas necessidades.
Use o botão para baixo antes de entrar
Filtre linhas e colunas desnecessárias no DataFrame antes de realizar uma junção. Isso tem as seguintes vantagens:
-
Reduz a quantidade de transferência de dados durante o shuffle
-
Reduz a quantidade de processamento no executor do Spark
-
Reduz a quantidade de dados digitalizados
# Default df_joined = df1.join(df2, ["product_id"]) # Use Pushdown df1_select = df1.select("product_id","product_title","star_rating").filter(col("star_rating")>=4.0) df2_select = df2.select("product_id","category_id") df_joined = df1_select.join(df2_select, ["product_id"])
Use DataFrame Join
Tente usar um Spark de alto níveldyf.toDF(). Conforme discutido na seção Tópicos principais do Apache Spark, essas operações de junção aproveitam internamente a otimização de consultas pelo otimizador Catalyst.
Embaralhe e transmita junções e dicas de hash
O Spark suporta dois tipos de junção: junção aleatória e junção hash de transmissão. Uma junção de hash de transmissão não requer embaralhamento e pode exigir menos processamento do que uma junção aleatória. No entanto, é aplicável somente ao unir uma mesa pequena a uma grande. Ao unir uma tabela que cabe na memória de um único executor do Spark, considere usar uma junção de hash de transmissão.
O diagrama a seguir mostra a estrutura de alto nível e as etapas de uma junção de hash de transmissão e uma junção aleatória.
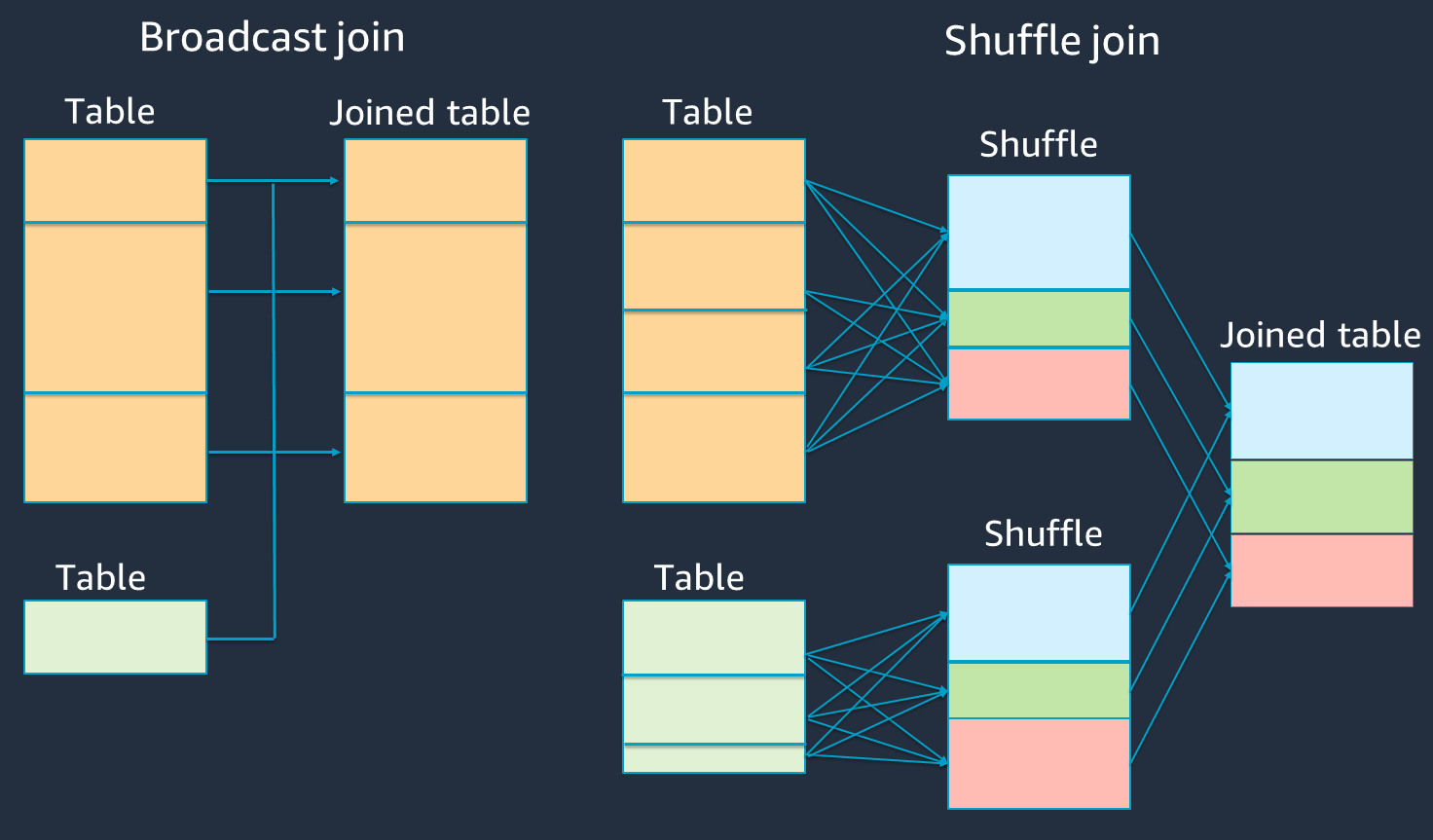
Os detalhes de cada união são os seguintes:
-
Junção aleatória:
-
A junção de hash shuffle une duas tabelas sem classificação e distribui a junção entre as duas tabelas. É adequado para junções de pequenas tabelas que podem ser armazenadas na memória do executor do Spark.
-
A junção sort-merge distribui as duas tabelas a serem unidas por chave e as classifica antes de serem unidas. É adequado para junções de mesas grandes.
-
-
Junção de hash de transmissão:
-
Uma junção de hash de transmissão empurra o menor RDD ou a tabela para cada um dos nós de trabalho. Em seguida, ele faz uma combinação do lado do mapa com cada partição do maior RDD ou da tabela.
É adequado para junções quando uma de suas RDDs tabelas cabe na memória ou pode ser feita para caber na memória. É vantajoso fazer uma junção de hash de transmissão sempre que possível, porque isso não requer uma combinação aleatória. Você pode usar uma dica de junção para solicitar uma entrada de transmissão do Spark da seguinte maneira.
# DataFrame from pySpark.sql.functions import broadcast df_joined= df_big.join(broadcast(df_small), right_df[key] == left_df[key], how='inner') -- SparkSQL SELECT /*+ BROADCAST(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;Para obter mais informações sobre dicas de junção, consulte Dicas de união
.
-
Na AWS Glue versão 3.0 e versões posteriores, você pode aproveitar automaticamente as junções de hash de transmissão ativando a execução adaptativa de consultas e parâmetros adicionais
Na AWS Glue versão 3.0, você pode ativar a Execução Adaptativa de Consultas spark.sql.adaptive.enabled=true definindo. A execução adaptativa de consultas está ativada por padrão no AWS Glue 4.0.
Você pode definir parâmetros adicionais relacionados aos shuffles e às junções de hash de transmissão:
-
spark.sql.adaptive.localShuffleReader.enabled -
spark.sql.adaptive.autoBroadcastJoinThreshold
Para obter mais informações sobre parâmetros relacionados, consulte Conversão de junção sort-merge em junção
Na AWS Glue versão 3.0 ou posterior, você pode usar outras dicas de junção para o shuffle para ajustar seu comportamento.
-- Join Hints for shuffle sort merge join SELECT /*+ SHUFFLE_MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGEJOIN(t2) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; SELECT /*+ MERGE(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle hash join SELECT /*+ SHUFFLE_HASH(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key; -- Join Hints for shuffle-and-replicate nested loop join SELECT /*+ SHUFFLE_REPLICATE_NL(t1) / FROM t1 INNER JOIN t2 ON t1.key = t2.key;
Use o compartimento
A junção classificação-mesclagem requer duas fases: embaralhar e classificar e, em seguida, mesclar. Essas duas fases podem sobrecarregar o executor do Spark OOM e causar problemas de desempenho quando alguns dos executores estão se mesclando e outros estão classificando simultaneamente. Nesses casos, talvez seja possível unir com eficiência usando o agrupamento.
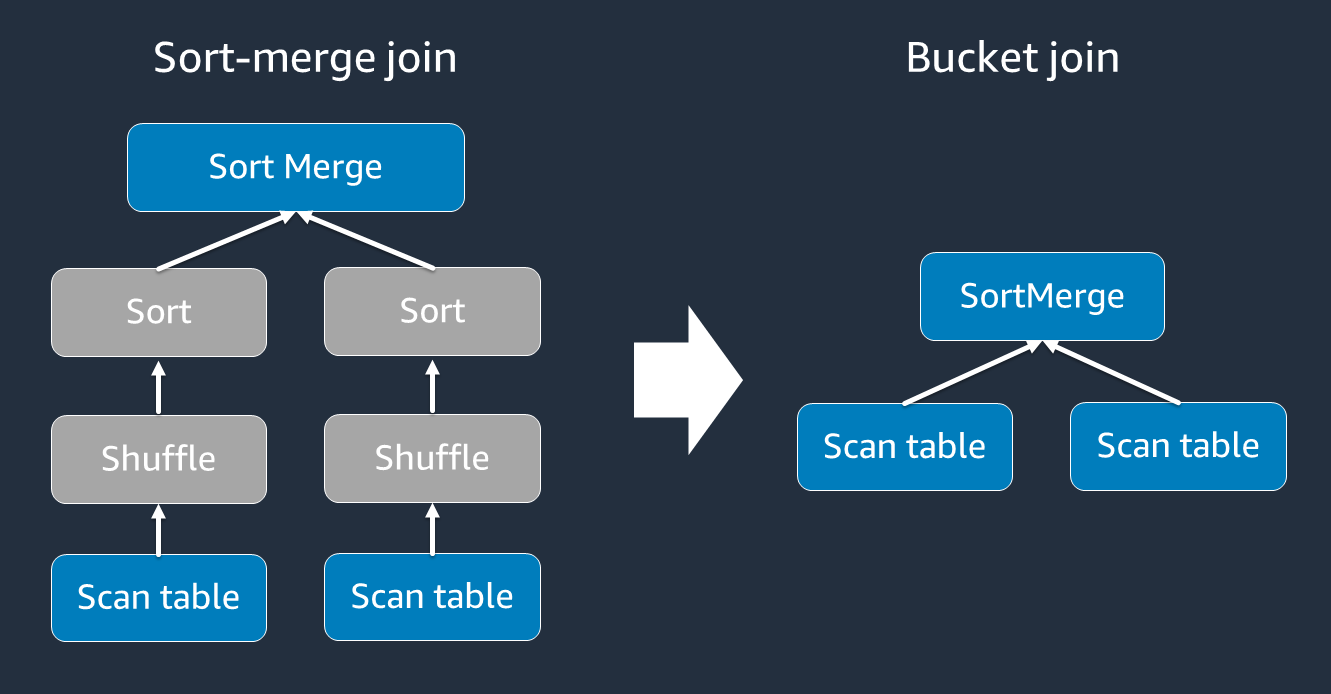
As tabelas agrupadas são úteis para o seguinte:
-
Dados unidos com frequência pela mesma chave, como
account_id -
Carregar tabelas cumulativas diárias, como tabelas base e delta, que podem ser agrupadas em uma coluna comum
Você pode criar uma tabela agrupada usando o código a seguir.
df.write.bucketBy(50, "account_id").sortBy("age").saveAsTable("bucketed_table")
Repartição DataFrames nas chaves de junção antes da junção
Para reparticionar os dois DataFrames nas chaves de junção antes da junção, use as instruções a seguir.
df1_repartitioned = df1.repartition(N,"join_key") df2_repartitioned = df2.repartition(N,"join_key") df_joined = df1_repartitioned.join(df2_repartitioned,"product_id")
Isso particionará dois (ainda separados) RDDs na chave de junção antes de iniciar a junção. Se os dois RDDs estiverem particionados na mesma chave com o mesmo código de particionamento, RDD os registros de que seu plano de unir terão uma grande probabilidade de serem colocados no mesmo trabalhador antes de serem embaralhados para a junção. Isso pode melhorar o desempenho ao reduzir a atividade da rede e a distorção de dados durante a junção.
Supere a distorção de dados
A distorção de dados é uma das causas mais comuns de gargalo nas tarefas do Spark. Ela ocorre quando os dados não são distribuídos uniformemente entre as RDD partições. Isso faz com que as tarefas dessa partição demorem muito mais do que outras, atrasando o tempo geral de processamento do aplicativo.
Para identificar a distorção de dados, avalie as seguintes métricas na interface do usuário do Spark:
-
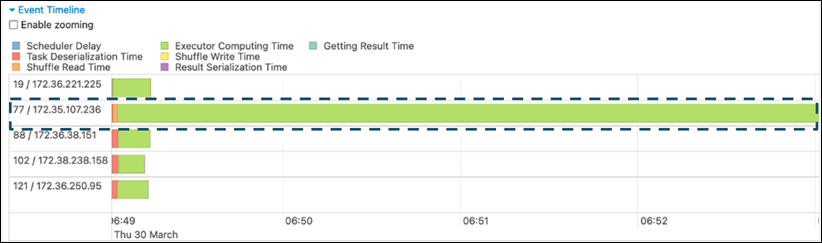
Na guia Palco na interface do usuário do Spark, examine a página Cronograma do evento. Você pode ver uma distribuição desigual de tarefas na captura de tela a seguir. Tarefas distribuídas de forma desigual ou demorando muito para serem executadas podem indicar distorção de dados.
-
Outra página importante é o Summary Metrics, que mostra estatísticas das tarefas do Spark. A captura de tela a seguir mostra métricas com percentis para duração, tempo de GC, derramamento (memória), derramamento (disco) e assim por diante.

Quando as tarefas forem distribuídas uniformemente, você verá números semelhantes em todos os percentis. Quando há distorção de dados, você verá valores muito tendenciosos em cada percentil. No exemplo, a duração da tarefa é inferior a 13 segundos em Min, 25º percentil, Mediana e 75º percentil. Embora a tarefa Max tenha processado 100 vezes mais dados do que o percentil 75, sua duração de 6,4 minutos é cerca de 30 vezes maior. Isso significa que pelo menos uma tarefa (ou até 25% das tarefas) demorou muito mais do que o resto das tarefas.
Se você observar distorção de dados, tente o seguinte:
-
Se você usa AWS Glue 3.0, ative a Execução de Consulta Adaptativa por meio da configuração
spark.sql.adaptive.enabled=true. A execução adaptativa de consultas está ativada por padrão na AWS Glue versão 4.0.Você também pode usar o Adaptive Query Execution para a distorção de dados introduzida pelas junções definindo os seguintes parâmetros relacionados:
-
spark.sql.adaptive.skewJoin.skewedPartitionFactor -
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes -
spark.sql.adaptive.advisoryPartitionSizeInBytes=128m (128 mebibytes or larger should be good) -
spark.sql.adaptive.coalescePartitions.enabled=true (when you want to coalesce partitions)
Para obter mais informações, consulte a documentação do Apache Spark
. -
-
Use chaves com uma grande variedade de valores para as chaves de junção. Em uma junção aleatória, as partições são determinadas para cada valor de hash de uma chave. Se a cardinalidade de uma chave de junção for muito baixa, é mais provável que a função hash faça um trabalho ruim ao distribuir seus dados entre partições. Portanto, se seu aplicativo e sua lógica de negócios forem compatíveis, considere usar uma chave de cardinalidade mais alta ou uma chave composta.
# Use Single Primary Key df_joined = df1_select.join(df2_select, ["primary_key"]) # Use Composite Key df_joined = df1_select.join(df2_select, ["primary_key","secondary_key"])
Use o cache
Ao usar repetitivo DataFrames, evite operações aleatórias ou computacionais adicionais usando df.cache() ou df.persist() armazenando em cache os resultados do cálculo na memória e no disco de cada executor do Spark. O Spark também suporta a persistência RDDs em disco ou a replicação em vários nós (nível de armazenamento
Por exemplo, você pode persistir DataFrames adicionandodf.persist(). Quando o cache não for mais necessário, você poderá usá-lo unpersist para descartar os dados em cache.
df = spark.read.parquet("s3://<Bucket>/parquet/product_category=Books/") df_high_rate = df.filter(col("star_rating")>=4.0) df_high_rate.persist() df_joined1 = df_high_rate.join(<Table1>, ["key"]) df_joined2 = df_high_rate.join(<Table2>, ["key"]) df_joined3 = df_high_rate.join(<Table3>, ["key"]) ... df_high_rate.unpersist()
Remova ações desnecessárias do Spark
Evite executar ações desnecessáriascount, comoshow, oucollect. Conforme discutido na seção Tópicos principais do Apache Spark, o Spark é preguiçoso. Cada transformação RDD pode ser recalculada cada vez que você executa uma ação nela. Quando você usa várias ações do Spark, vários acessos à origem, cálculos de tarefas e execuções aleatórias para cada ação são chamados.
Se você não precisar collect() de outras ações em seu ambiente comercial, considere removê-las.
nota
Evite usar o Spark collect() em ambientes comerciais o máximo possível. A collect() ação retorna todos os resultados de um cálculo no executor do Spark para o driver do Spark, o que pode fazer com que o driver do Spark retorne um erro. OOM Para evitar OOM erros, o Spark define spark.driver.maxResultSize = 1GB por padrão, o que limita o tamanho máximo dos dados retornados ao driver do Spark em 1 GB.
