As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Otimize as funções definidas pelo usuário
Funções definidas pelo usuário (UDFs) e RDD.map PySpark geralmente degradam significativamente o desempenho. Isso se deve à sobrecarga necessária para representar com precisão seu código Python na implementação subjacente do Scala do Spark.
O diagrama a seguir mostra a arquitetura dos PySpark trabalhos. Quando você usa PySpark, o driver do Spark usa a biblioteca Py4j para chamar métodos Java do Python. Ao chamar o Spark SQL ou funções DataFrame integradas, há pouca diferença de desempenho entre Python e Scala porque as funções são executadas em cada executor usando um plano de execução JVM otimizado.
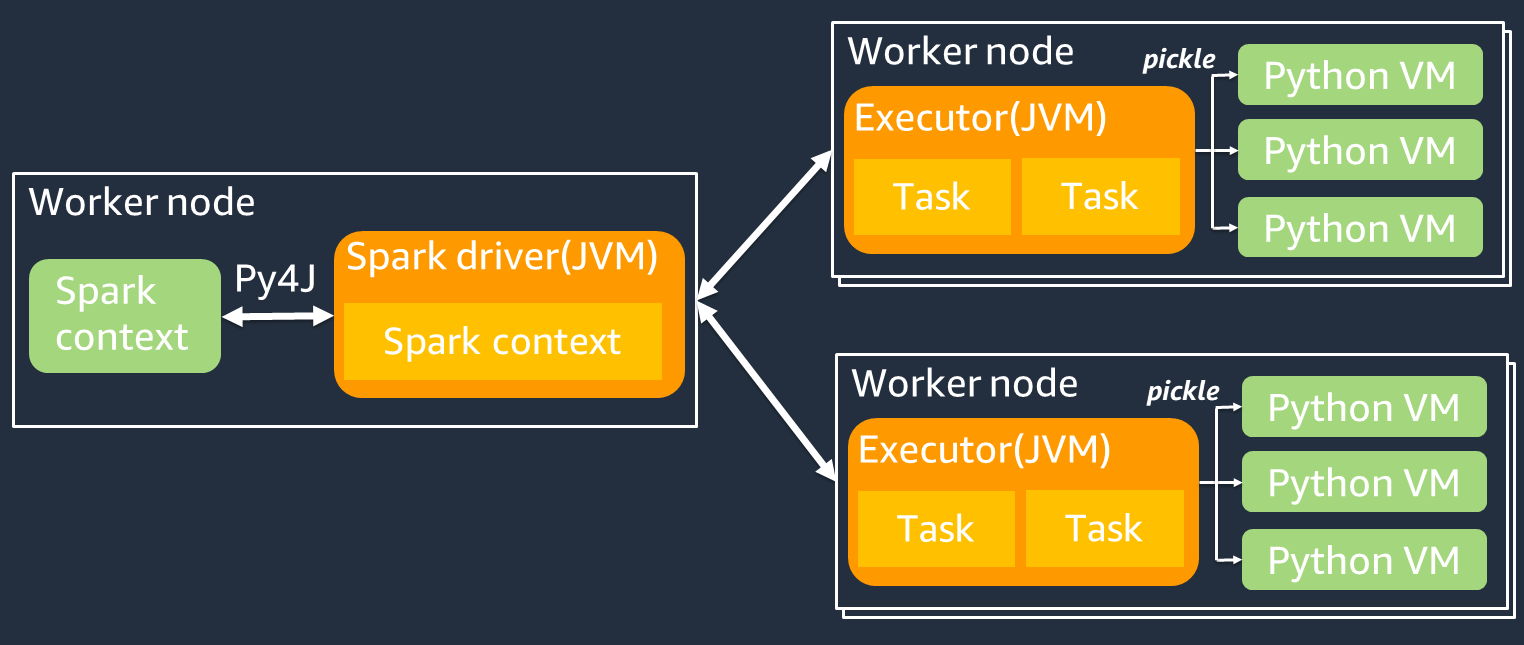
Se você usar sua própria lógica do Python, como usarmap/ mapPartitions/ udf, a tarefa será executada em um ambiente de execução do Python. O gerenciamento de dois ambientes gera um custo indireto. Além disso, seus dados na memória devem ser transformados para serem usados pelas funções integradas do ambiente de tempo de JVM execução. Pickle é um formato de serialização usado por padrão para a troca entre os tempos de execução e JVM Python. No entanto, o custo desse custo de serialização e desserialização é muito alto, portanto, UDFs escritos em Java ou Scala são mais rápidos que Python. UDFs
Para evitar a sobrecarga de serialização e desserialização PySpark, considere o seguinte:
-
Use as SQL funções integradas do Spark — Considere substituir sua própria função UDF ou função de mapa pelo Spark SQL ou por funções DataFrame integradas. Ao executar o Spark SQL ou funções DataFrame integradas, há pouca diferença de desempenho entre o Python e o Scala porque as tarefas são executadas por cada executor. JVM
-
Implemente UDFs em Scala ou Java — Considere usar um UDF que esteja escrito em Java ou Scala, porque eles são executados no. JVM
-
Use o Apache Arrow UDFs para cargas de trabalho vetorizadas — Considere usar o baseado em Arrow. UDFs Esse recurso também é conhecido como vetorizado UDF (UDFPandas). O Apache Arrow
é um formato de dados em memória independente de linguagem que AWS Glue pode ser usado para transferir dados com eficiência entre processos Python e Python. JVM Atualmente, isso é mais benéfico para usuários de Python que trabalham com Pandas ou dados. NumPy A seta é um formato colunar (vetorizado). Seu uso não é automático e pode exigir algumas pequenas alterações na configuração ou no código para aproveitar ao máximo e garantir a compatibilidade. Para obter mais detalhes e limitações, consulte Apache Arrow em PySpark
. O exemplo a seguir compara um incremental básico UDF no Python padrão, como um UDF vetorizado e no Spark. SQL
Python padrão UDF
O tempo do exemplo é 3,20 (seg).
Código de exemplo
# DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # UDF Example def plus(a,b): return a+b spark.udf.register("plus",plus) df.selectExpr("count(plus(a,b))").collect()
Plano de execução
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#124)]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#580] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#124)]) +- Project [pythonUDF0#124] +- BatchEvalPython [plus(a#116L, b#117L)], [pythonUDF0#124] +- Project [id#114L AS a#116L, id#114L AS b#117L] +- Range (0, 10000000, step=1, splits=16)
Vetorizado UDF
O tempo do exemplo é 0,59 (seg).
O Vetorizado UDF é 5 vezes mais rápido que o exemplo anteriorUDF. VerificandoPhysical Plan, você pode verArrowEvalPython, o que mostra que esse aplicativo é vetorizado pelo Apache Arrow. Para habilitar o VetorizadoUDF, você deve especificar spark.sql.execution.arrow.pyspark.enabled = true em seu código.
Código de exemplo
# Vectorized UDF from pyspark.sql.types import LongType from pyspark.sql.functions import count, pandas_udf # Enable Apache Arrow Support spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true") # DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # Annotate pandas_udf to use Vectorized UDF @pandas_udf(LongType()) def pandas_plus(a,b): return a+b spark.udf.register("pandas_plus",pandas_plus) df.selectExpr("count(pandas_plus(a,b))").collect()
Plano de execução
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#1082L)], output=[count(pandas_plus(a, b))#1080L]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#5985] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#1082L)], output=[count#1084L]) +- Project [pythonUDF0#1082L] +- ArrowEvalPython [pandas_plus(a#1074L, b#1075L)], [pythonUDF0#1082L], 200 +- Project [id#1072L AS a#1074L, id#1072L AS b#1075L] +- Range (0, 10000000, step=1, splits=16)
Faísca SQL
O tempo do exemplo é 0,087 (seg).
O Spark SQL é muito mais rápido do que o VectorizedUDF, porque as tarefas são executadas em cada executor sem JVM um tempo de execução do Python. Se você puder UDF substituí-lo por uma função integrada, recomendamos que você faça isso.
Código de exemplo
df.createOrReplaceTempView("test") spark.sql("select count(a+b) from test").collect()
Usando pandas para big data
Se você já está familiarizado com pandas
