As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Paralelize tarefas
Para otimizar o desempenho, é importante paralelizar tarefas para cargas e transformações de dados. Conforme discutimos em Tópicos principais do Apache Spark, o número de partições resilientes distribuídas de conjunto de dados (RDD) é importante, pois determina o grau de paralelismo. Cada tarefa que o Spark cria corresponde a uma RDD partição em uma base 1:1. Para obter o melhor desempenho, você precisa entender como o número de RDD partições é determinado e como esse número é otimizado.
Se você não tiver paralelismo suficiente, os seguintes sintomas serão registrados nas CloudWatchmétricas e na interface do usuário do Spark.
CloudWatch métricas
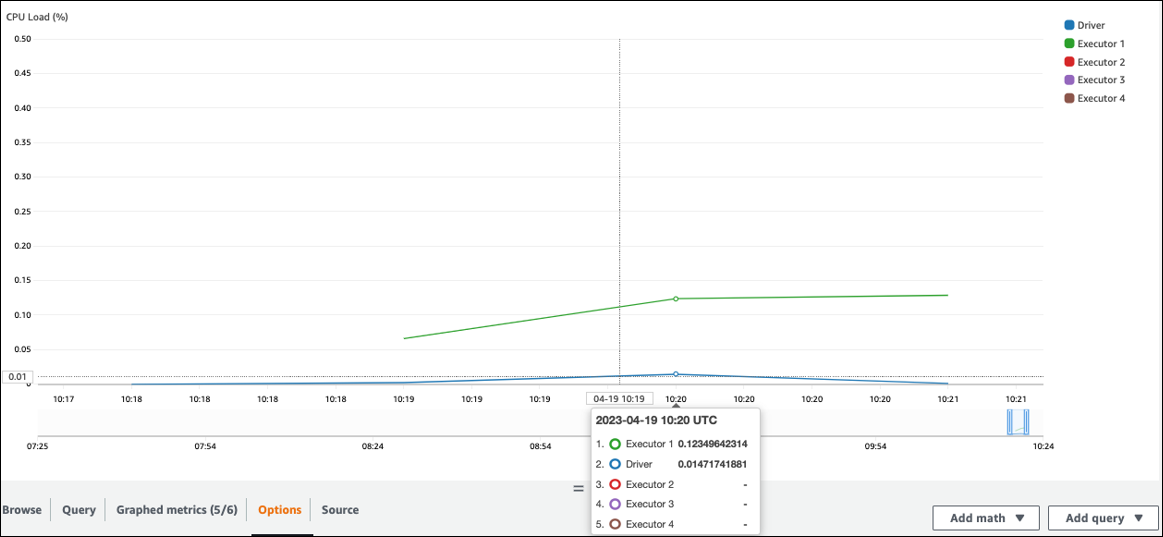
Verifique a CPUcarga e a utilização da memória. Se alguns executores não estiverem processando durante uma fase do seu trabalho, é apropriado melhorar o paralelismo. Nesse caso, durante o período visualizado, o Executor 1 estava executando uma tarefa, mas os demais executores (2, 3 e 4) não. Você pode inferir que esses executores não receberam tarefas atribuídas pelo driver do Spark.
IU do Spark
Na guia Estágio na interface do Spark, você pode ver o número de tarefas em um estágio. Nesse caso, o Spark executou apenas uma tarefa.

Além disso, a linha do tempo do evento mostra o Executor 1 processando uma tarefa. Isso significa que o trabalho nesse estágio foi executado inteiramente em um executor, enquanto os outros estavam ociosos.

Se você observar esses sintomas, tente as soluções a seguir para cada fonte de dados.
Paralelize a carga de dados do Amazon S3
Para paralelizar cargas de dados do Amazon S3, primeiro verifique o número padrão de partições. Em seguida, você pode determinar manualmente um número alvo de partições, mas evite ter muitas partições.
Determine o número padrão de partições
Para o Amazon S3, o número inicial de RDD partições do Spark (cada uma correspondendo a uma tarefa do Spark) é determinado pelos recursos do seu conjunto de dados do Amazon S3 (por exemplo, formato, compactação e tamanho). Quando você cria um AWS Glue DynamicFrame ou um Spark a DataFrame partir de CSV objetos armazenados no Amazon S3, o número inicial RDD de partições NumPartitions () pode ser calculado aproximadamente da seguinte forma:
-
Tamanho do objeto <= 64 MB:
NumPartitions = Number of Objects -
Tamanho do objeto > 64 MB:
NumPartitions = Total Object Size / 64 MB -
Não divisível (gzip):
NumPartitions = Number of Objects
Conforme discutido na seção Reduzir a quantidade de escaneamento de dados, o Spark divide objetos grandes do S3 em divisões que podem ser processadas paralelamente. Quando o objeto é maior que o tamanho da divisão, o Spark divide o objeto e cria uma RDD partição (e uma tarefa) para cada divisão. O tamanho da divisão do Spark é baseado no formato dos dados e no ambiente de execução, mas essa é uma aproximação inicial razoável. Alguns objetos são compactados usando formatos de compactação não divisíveis, como gzip, então o Spark não pode dividi-los.
O NumPartitions valor pode variar dependendo do formato dos dados, da compactação, da AWS Glue versão, do número de AWS Glue trabalhadores e da configuração do Spark.
Por exemplo, quando você carrega um único csv.gz objeto de 10 GB usando um Spark DataFrame, o driver do Spark cria somente uma RDD Partition (NumPartitions=1) porque o gzip não pode ser dividido. Isso resulta em uma carga pesada em um executor específico do Spark e nenhuma tarefa é atribuída aos demais executores, conforme descrito na figura a seguir.
Verifique o número real de tarefas (NumPartitions) do estágio na guia Spark Web UI Stage ou execute df.rdd.getNumPartitions() seu código para verificar o paralelismo.
Ao encontrar um arquivo gzip de 10 GB, examine se o sistema que está gerando esse arquivo pode gerá-lo em um formato divisível. Se isso não for uma opção, talvez seja necessário escalar a capacidade do cluster para processar o arquivo. Para executar transformações de forma eficiente nos dados que você carregou, você precisará reequilibrar os trabalhadores RDD em seu cluster usando a repartição.
Determine manualmente um número alvo de partições
Dependendo das propriedades de seus dados e da implementação de determinadas funcionalidades pelo Spark, você pode acabar com um NumPartitions valor baixo, mesmo que o trabalho subjacente ainda possa ser paralelizado. Se NumPartitions for muito pequeno, execute df.repartition(N) para aumentar o número de partições para que o processamento possa ser distribuído entre vários executores do Spark.
Nesse caso, a execução df.repartition(100) aumentará NumPartitions de 1 para 100, criando 100 partições de seus dados, cada uma com uma tarefa que pode ser atribuída aos outros executores.
A operação repartition(N) divide os dados inteiros igualmente (10 GB/100 partições = 100 MB/partição), evitando a distorção de dados em determinadas partições.
nota
Quando uma operação aleatória como a join é executada, o número de partições aumenta ou diminui dinamicamente, dependendo do valor de ou. spark.sql.shuffle.partitions spark.default.parallelism Isso facilita uma troca mais eficiente de dados entre os executores do Spark. Para obter mais informações, consulte a documentação do Spark
Sua meta ao determinar o número alvo de partições é maximizar o uso dos trabalhadores provisionados AWS Glue . O número de AWS Glue trabalhadores e o número de tarefas do Spark estão relacionados por meio do número devCPUs. O Spark suporta uma tarefa para cada CPU núcleo v. Na AWS Glue versão 3.0 ou posterior, você pode calcular um número alvo de partições usando a fórmula a seguir.
# Calculate NumPartitions by WorkerType numExecutors = (NumberOfWorkers - 1) numSlotsPerExecutor = 4 if WorkerType is G.1X 8 if WorkerType is G.2X 16 if WorkerType is G.4X 32 if WorkerType is G.8X NumPartitions = numSlotsPerExecutor * numExecutors # Example: Glue 4.0 / G.1X / 10 Workers numExecutors = ( 10 - 1 ) = 9 # 1 Worker reserved on Spark Driver numSlotsPerExecutor = 4 # G.1X has 4 vCpu core ( Glue 3.0 or later ) NumPartitions = 9 * 4 = 36
Neste exemplo, cada trabalhador G.1X fornece quatro CPU núcleos v para um executor do Spark (). spark.executor.cores = 4 O Spark suporta uma tarefa para cada v CPU Core, então os executores do G.1X Spark podem executar quatro tarefas simultaneamente (). numSlotPerExecutor Esse número de partições faz uso total do cluster se as tarefas levarem o mesmo tempo. No entanto, algumas tarefas demorarão mais do que outras, criando núcleos ociosos. Se isso acontecer, considere multiplicar numPartitions por 2 ou 3 para dividir e programar com eficiência as tarefas de gargalo.
Muitas partições
Um número excessivo de partições cria um número excessivo de tarefas. Isso causa uma carga pesada no driver do Spark devido à sobrecarga relacionada ao processamento distribuído, como tarefas de gerenciamento e troca de dados entre os executores do Spark.
Se o número de partições em seu trabalho for substancialmente maior do que o número desejado de partições, considere reduzir o número de partições. Você pode reduzir partições usando as seguintes opções:
-
Se o tamanho do arquivo for muito pequeno, use AWS Glue groupFiles. Você pode reduzir o paralelismo excessivo resultante do lançamento de uma tarefa do Apache Spark para processar cada arquivo.
-
Use
coalesce(N)para mesclar partições. Esse é um processo de baixo custo. Ao reduzir o número de partições,coalesce(N)é preferívelrepartition(N), poisrepartition(N)executa o shuffle para distribuir igualmente a quantidade de registros em cada partição. Isso aumenta os custos e as despesas gerais de gerenciamento. -
Use a execução adaptativa de consultas do Spark 3.x. Conforme discutido na seção Tópicos principais do Apache Spark, a Execução Adaptativa de Consultas fornece uma função para aglutinar automaticamente o número de partições. Você pode usar essa abordagem quando não consegue saber o número de partições até realizar a execução.
Paralelize a carga de dados de JDBC
O número de RDD partições do Spark é determinado pela configuração. Observe que, por padrão, somente uma única tarefa é executada para verificar todo o conjunto de dados de origem por meio de uma SELECT consulta.
Tanto o Spark AWS Glue DynamicFrames quanto o Spark DataFrames oferecem suporte ao carregamento de JDBC dados paralelizado em várias tarefas. Isso é feito usando where predicados para dividir uma SELECT consulta em várias consultas. Para paralelizar as leituras deJDBC, configure as seguintes opções:
-
Para AWS Glue DynamicFrame, defina
hashfield(ouhashexpression)hashpartitione. Para saber mais, consulte Lendo de JDBC tabelas em paralelo.connection_mysql8_options = { "url": "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test", "dbtable": "medicare_tb", "user": "test", "password": "XXXXXXXXX", "hashexpression":"id", "hashpartitions":"10" } datasource0 = glueContext.create_dynamic_frame.from_options( 'mysql', connection_options=connection_mysql8_options, transformation_ctx= "datasource0" ) -
Para Spark DataFrame, set
numPartitionspartitionColumn,lowerBound, e.upperBoundPara saber mais, consulte JDBCPara outros bancos de dados. df = spark.read \ .format("jdbc") \ .option("url", "jdbc:mysql://XXXXXXXXXX.XXXXXXX.us-east-1.rds.amazonaws.com:3306/test") \ .option("dbtable", "medicare_tb") \ .option("user", "test") \ .option("password", "XXXXXXXXXX") \ .option("partitionColumn", "id") \ .option("numPartitions", "10") \ .option("lowerBound", "0") \ .option("upperBound", "1141455") \ .load() df.write.format("json").save("s3://bucket_name/Tests/sparkjdbc/with_parallel/")
Paralelize a carga de dados do DynamoDB ao usar o conector ETL
O número de RDD partições do Spark é determinado pelo dynamodb.splits parâmetro. Para paralelizar as leituras do Amazon DynamoDB, configure as seguintes opções:
-
Aumente o valor do
dynamodb.splits. -
Otimize o parâmetro seguindo a fórmula explicada em Tipos e opções de conexão do ETL in AWS Glue for Spark.
Paralelize a carga de dados do Kinesis Data Streams
O número de RDD partições do Spark é determinado pelo número de fragmentos no stream de dados de origem do Amazon Kinesis Data Streams. Se você tiver apenas alguns fragmentos em seu fluxo de dados, haverá apenas algumas tarefas do Spark. Isso pode resultar em baixo paralelismo nos processos posteriores. Para paralelizar as leituras do Kinesis Data Streams, configure as seguintes opções:
-
Aumente o número de fragmentos para obter mais paralelismo ao carregar dados do Kinesis Data Streams.
-
Se sua lógica no microlote for complexa o suficiente, considere reparticionar os dados no início do lote, depois de eliminar as colunas desnecessárias.
Para obter mais informações, consulte Práticas recomendadas para otimizar o custo e o desempenho AWS Glue de ETL trabalhos de streaming
Paralelize tarefas após o carregamento dos dados
Para paralelizar tarefas após o carregamento dos dados, aumente o número de RDD partições usando as seguintes opções:
-
Reparticione os dados para gerar um número maior de partições, especialmente logo após o carregamento inicial, se a carga em si não puder ser paralelizada.
Ligue
repartition()DynamicFrame ou DataFrame especifique o número de partições. Uma boa regra é duas ou três vezes o número de núcleos disponíveis.No entanto, ao escrever uma tabela particionada, isso pode levar a uma explosão de arquivos (cada partição pode potencialmente gerar um arquivo em cada partição da tabela). Para evitar isso, você pode reparticionar sua coluna DataFrame por. Isso usa as colunas de partição da tabela para que os dados sejam organizados antes da gravação. Você pode especificar um número maior de partições sem colocar arquivos pequenos nas partições da tabela. No entanto, tenha cuidado para evitar a distorção de dados, na qual alguns valores de partição acabam com a maioria dos dados e atrasam a conclusão da tarefa.
-
Quando houver embaralhos, aumente o
spark.sql.shuffle.partitionsvalor. Isso também pode ajudar com qualquer problema de memória ao embaralhar.Quando você tem mais de 2.001 partições aleatórias, o Spark usa um formato de memória compactada. Se você tiver um número próximo a esse, talvez queira definir o
spark.sql.shuffle.paritionsvalor acima desse limite para obter uma representação mais eficiente.
