O Amazon Redshift deixará de oferecer suporte ao uso de UDFs em Python após 30 de junho de 2026. Começaremos a aplicar essa alteração em fases. Consulte mais informações sobre os detalhes do fim da vida útil do Python e as opções de migração na publicação do blog
Arquitetura de sistema do data warehouse
Esta seção explica os componentes da arquitetura de data warehouse do Amazon Redshift, conforme mostrado na figura a seguir.
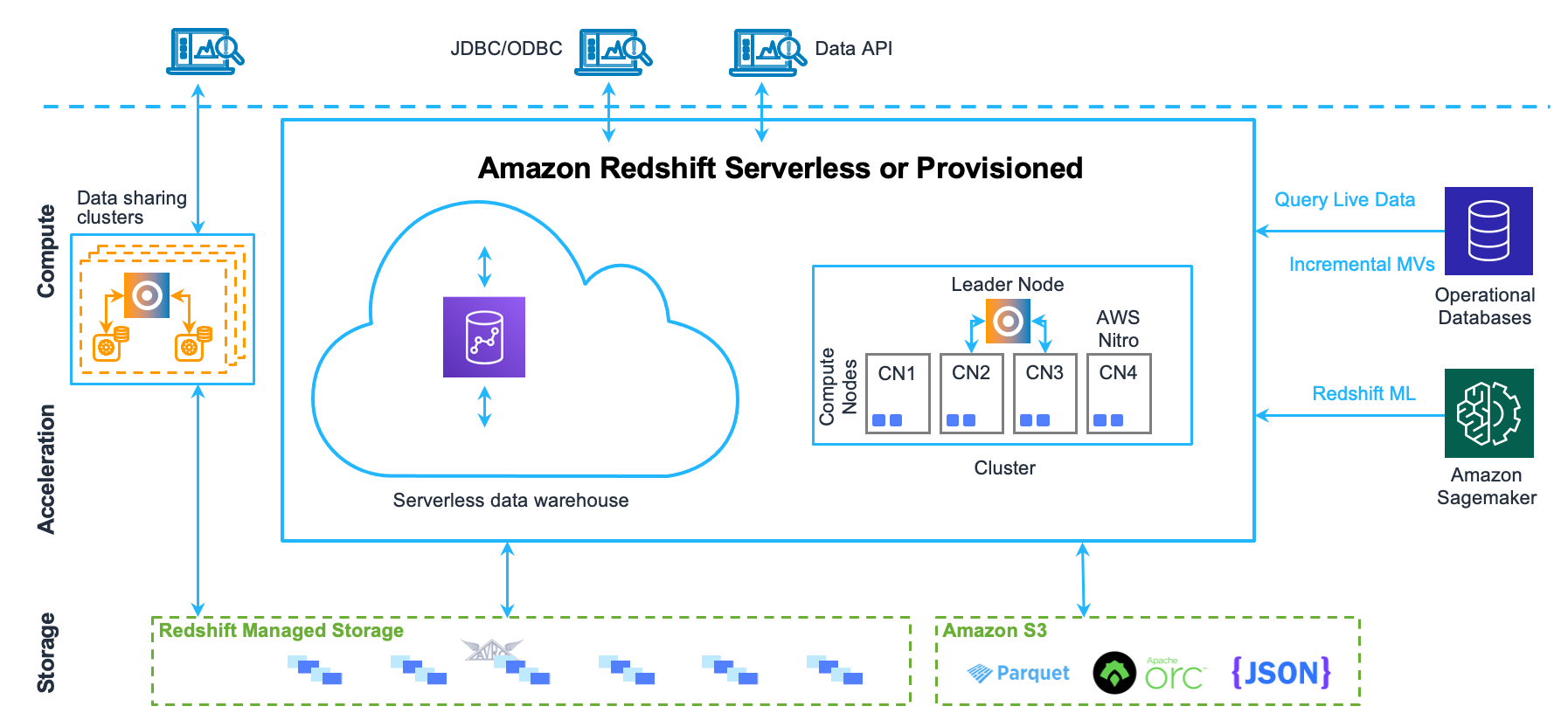
Aplicativos cliente
O Amazon Redshift se integra a diversas ferramentas de carregamento de dados e ETL (extração, transformação e carregamento), além de ferramentas de BI (business intelligence), relatórios, mineração de dados e analíticas. O Amazon Redshift se baseia no PostgreSQL de padrão aberto, portanto a maioria das aplicações cliente SQL existentes funcionará somente com alterações mínimas. Para obter informações sobre diferenças importantes entre Amazon Redshift SQL e PostgreSQL, consulte Amazon Redshift e PostgreSQL.
Clusters
O principal componente da infraestrutura de um data warehouse do Amazon Redshift é um cluster.
Um cluster é composto de um ou mais nós de computação. Se um cluster for provisionado com dois ou mais nós de computação, um nó líder adicional coordenará os nós de computação e processará a comunicação externa. O aplicativo cliente interage diretamente somente com o nó líder. Os nós de computação são transparentes a aplicativos externos.
Nó líder
O nó líder gerencia a comunicação com programas cliente e toda a comunicação com nós de computação. Ele analisa e desenvolve planos de execução para realizar operações de banco de dados, em especial, a série de etapas necessárias a fim de obter resultados para consultas complexas. Com base no plano de execução, o nó líder compila código, distribui o código compilado aos nós de computação e atribui uma parte dos dados a cada nó de computação.
O nó líder distribui instruções SQL para os nós de computação somente quando uma consulta referencia tabelas armazenadas nos nós de computação. Todas as outras consultas são executadas de maneira exclusiva no nó de liderança. O Amazon Redshift foi projetado para implementar determinadas funções SQL somente no nó líder. Uma consulta que usa qualquer uma dessas funções retornará um erro se referenciar tabelas que residam nos nós de computação. Para obter mais informações, consulte Funções SQL compatíveis no nó de liderança.
Nós de computação
O nó líder compila código de elementos individuais do plano de execução e atribui o código aos nós de computação individuais. Os nós de computação executam o código compilado e reenviam os resultados intermediários ao nó líder para agregação final.
Cada nó de computação tem as próprias CPU e memória dedicadas, determinadas pelo tipo de nó. À medida que sua workload cresce, você pode aumentar a capacidade computacional de um cluster aumentando o número de nós, atualizando o tipo de nó ou ambos.
O Amazon Redshift oferece vários tipos de nós para suas necessidades de computação. Para obter detalhes de cada tipo de nó, consulte “Clusters do Amazon Redshift” no Guia de gerenciamento de clusters do Amazon Redshift.
Redshift Managed Storage
Os dados do data warehouse são armazenados em outro nível de armazenamento do Redshift Managed Storage (RMS). O RMS oferece a capacidade de escalar seu armazenamento para petabytes usando o armazenamento do Amazon S3. O RMS permite a você escalar e pagar pela computação e pelo armazenamento de maneira independente, para que você possa dimensionar o cluster com base apenas nas necessidades de computação. Ele usa automaticamente o armazenamento local baseado em SSD de alto desempenho como cache de nível 1. Também aproveita as otimizações, como temperatura do bloco de dados, idade do bloco de dados e padrões de workload, para oferecer alta performance e escalar o armazenamento automaticamente para o Amazon S3, quando necessário, sem exigir nenhuma ação.
Fatias de nó
Um nó de computação é particionado em fatias. Cada fatia recebe uma parte da memória do nó e do espaço em disco, em que processa uma parte do workload atribuído ao nó. O nó líder gerencia dados a distribuição de dados para as fatias e divide o workload para todas as consultas ou outras operações de banco de dados para as fatias. Assim, as fatias funcionam em paralelo para completar a operação.
O número de fatias por nó é determinado pelo tamanho do nó do cluster. Para obter mais informações sobre o número de fatias para cada tamanho de nó, acesse “Clusters e nós no Amazon Redshift” no Guia de gerenciamento de clusters do Amazon Redshift.
Ao criar uma tabela, você também pode especificar uma coluna como a chave de distribuição. Quando a tabela é carregada com dados, as linhas são distribuídas para as fatias de nó de acordo com a chave de distribuição definida para uma tabela. A escolha de uma boa chave de distribuição permite que o Amazon Redshift use processamento paralelo para carregar dados e executar consultas com eficiência. Para obter informações sobre como escolher uma chave de distribuição, consulte Escolha o melhor estilo de distribuição.
Rede interna
O Amazon Redshift tira proveito de conexões de alta largura de banda, proximidade e protocolos de comunicação personalizados para fornecer comunicação de rede privada e de alta velocidade entre o nó líder e os nós de computação. Os nós de computação são executados em uma rede isolada, separada, que aplicativos cliente jamais acessam diretamente.
Bancos de dados na
Um cluster contém um ou mais bancos de dados. Os dados do usuário são armazenados nos nós de computação. O cliente SQL se comunica com o nó líder, que, por sua vez, coordena a execução de consultas com os nós de computação.
O Amazon Redshift é um sistema de gerenciamento de banco de dados relacional (RDBMS), portanto, é compatível com outras aplicações RDBMS. Embora forneça a mesma funcionalidade de um RDBMS típico, incluindo funções de processamento de transações online (OLTP), como inserção e exclusão de dados, o Amazon Redshift é otimizado para análise de alta performance e relatórios de conjuntos de dados muito grandes.
O Amazon Redshift é baseado no PostgreSQL. O Amazon Redshift e o PostgreSQL têm uma série de diferenças muito importantes que você precisa levar em consideração ao projetar e desenvolver suas aplicações de data warehouse. Para obter informações sobre como o Amazon Redshift SQL difere do PostgreSQL, consulte Amazon Redshift e PostgreSQL.
