O Amazon Redshift deixará de oferecer suporte ao uso de UDFs em Python após 30 de junho de 2026. Começaremos a aplicar essa alteração em fases. Consulte mais informações sobre os detalhes do fim da vida útil do Python e as opções de migração na publicação do blog
Carregar dados do Amazon EMR
Você pode usar o comando COPY para carregar dados em paralelo de um cluster do Amazon EMR configurado para gravar arquivos de texto no Sistema de Arquivos Distribuído do Hadoop (HDFS) do cluster na forma de arquivos de largura fixa, arquivos delimitados por caracteres, arquivos CSV ou com formato JSON.
Processo de carregamento de dados do Amazon EMR
Esta seção o orienta no processo de carregamento de dados de um cluster Amazon EMR. As seções a seguir fornecem os detalhes de que você precisa para realizar cada etapa.
-
Etapa 1: Configurar permissões do IAM
Os usuários que criam o cluster do Amazon EMR e executam o comando COPY do Amazon Redshift devem ter as permissões necessárias.
-
Etapa 2: Criar um cluster do Amazon EMR
Configure o cluster para enviar arquivos de texto para o Hadoop Distributed File System (HDFS). Você precisará do ID do cluster do Amazon EMR e do DNS público principal do cluster (o endpoint da instância do Amazon EC2 que hospeda o cluster).
-
Etapa 3: Recuperar a chave pública do cluster do Amazon Redshift e os endereços IP do nó do cluster
A chave pública permite que os nós de cluster do Amazon Redshift estabeleçam conexões SSH com os hosts. Você usará o endereço IP de cada nó do cluster para configurar os grupos de segurança do host para permitir o acesso de seu cluster Amazon Redshift usando esses endereços IP.
-
Você adiciona a chave pública do cluster do Amazon Redshift ao arquivo de chaves autorizadas do host para que o host reconheça o cluster do Amazon Redshift e aceite a conexão SSH.
-
Etapa 5: Configurar os hosts para aceitar todos os endereços IP do cluster do Amazon Redshift
Modifique os grupos de segurança da instância do Amazon EMR para adicionar regras de entrada para aceitar os endereços IP do Amazon Redshift.
-
Etapa 6: Executar o comando COPY para carregar os dados
De um banco de dados do Amazon Redshift, execute o comando COPY para carregar os dados em uma tabela do Amazon Redshift.
Etapa 1: Configurar permissões do IAM
Os usuários que criam o cluster do Amazon EMR e executam o comando COPY do Amazon Redshift devem ter as permissões necessárias.
Para configurar permissões do IAM
-
Adicione as permissões a seguir para o usuário que criará o cluster do Amazon EMR.
ec2:DescribeSecurityGroups ec2:RevokeSecurityGroupIngress ec2:AuthorizeSecurityGroupIngress redshift:DescribeClusters -
Adicione a seguinte permissão para o usuário ou perfil do IAM que executará o comando COPY.
elasticmapreduce:ListInstances -
Adicione a permissão a seguir à função do IAM do cluster do Amazon EMR.
redshift:DescribeClusters
Etapa 2: Criar um cluster do Amazon EMR
O comando COPY carrega dados de arquivos no Amazon EMR Hadoop Distributed File System (HDFS). Ao criar o cluster Amazon EMR, configure-o para enviar arquivos de dados para o HDFS do cluster.
Para criar um cluster do Amazon EMR
-
Crie um cluster do Amazon EMR na região da AWS como cluster do Amazon Redshift.
Se o cluster do Amazon Redshift estiver em uma VPC, o cluster do Amazon EMR deverá estar no mesmo grupo de VPC. Se o cluster do Amazon Redshift usa o modo EC2-Classic (ou seja, não está em um VPC), o cluster do Amazon EMR também deve usar o modo EC2-Classic. Para obter mais informações, consulte “Gerenciamento de clusters em uma VPC” no Guia de gerenciamento de clusters do Amazon Redshift.
-
Configure o cluster para enviar arquivos de dados para o HDFS do cluster. Os nomes de arquivos do HDFS não devem conter asteriscos (*) ou pontos de interrogação (?).
Importante
Os nomes de arquivos não devem conter asteriscos ( * ) ou pontos de interrogação ( ? ).
-
Especifique No (Não) para a opção Auto-terminate (Terminar automaticamente) na configuração de cluster do Amazon EMR para que o cluster permaneça disponível enquanto o comando COPY for executado.
Importante
Se um dos arquivos de dados for alterado ou excluído antes de COPY ser concluído, você poderá ter resultados inesperados ou a operação COPY poderá falhar.
-
Observe o ID do cluster e o DNS público primário (o endpoint da instância do Amazon EC2 que hospeda o cluster). Você usará essas informações em etapas subsequentes.
Etapa 3: Recuperar a chave pública do cluster do Amazon Redshift e os endereços IP do nó do cluster
Você usará o endereço IP de cada nó do cluster para configurar os grupos de segurança do host para permitir o acesso de seu cluster Amazon Redshift usando esses endereços IP.
Para recuperar a chave pública do cluster do Amazon Redshift e os endereços IP do nó do cluster para o seu cluster usando o console
-
Acesse o Console de Gerenciamento do Amazon Redshift.
-
No painel de navegação, selecione o link Clusters.
-
Selecione seu cluster na lista.
-
Localize o grupo Configurações de ingestão do SSH.
Observe a Chave pública do cluster e Endereços IP dos nós. Você vai usá-los em etapas subsequentes.
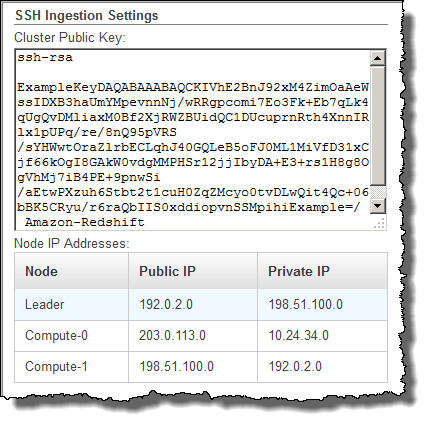
Você usará os endereços IP privados na Etapa 3 para configurar o host do Amazon EC2 para aceitar a conexão do Amazon Redshift.
Para recuperar a chave pública do cluster e os endereços IP do nó do cluster para seu cluster usando a CLI do Amazon Redshift, execute o comando describe-clusters. Por exemplo:
aws redshift describe-clusters --cluster-identifier <cluster-identifier>
A resposta incluirá um valor de ClusterPublicKey e a lista de endereços IP privados e públicos, semelhante ao seguinte:
{ "Clusters": [ { "VpcSecurityGroups": [], "ClusterStatus": "available", "ClusterNodes": [ { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "LEADER", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-0", "PublicIPAddress": "10.nnn.nnn.nnn" }, { "PrivateIPAddress": "10.nnn.nnn.nnn", "NodeRole": "COMPUTE-1", "PublicIPAddress": "10.nnn.nnn.nnn" } ], "AutomatedSnapshotRetentionPeriod": 1, "PreferredMaintenanceWindow": "wed:05:30-wed:06:00", "AvailabilityZone": "us-east-1a", "NodeType": "dc2.large", "ClusterPublicKey": "ssh-rsa AAAABexamplepublickey...Y3TAl Amazon-Redshift", ... ... }
Para recuperar a chave pública do cluster e os endereços IP do nó do cluster para o seu cluster usando a API do Amazon Redshift, use a ação DescribeClusters. Para obter mais informações, consulte describe-clusters no Guia de CLI do Amazon Redshift ou DescribeClusters no Guia de API do Amazon Redshift.
Etapa 4: Adicionar a chave pública do cluster do Amazon Redshift a cada arquivo de chaves autorizadas do host do Amazon EC2
Você adiciona a chave pública do cluster ao arquivo de chaves autorizadas de cada host para todos os nós do cluster do Amazon EMR para que os hosts reconheçam o Amazon Redshift e aceitem a conexão SSH.
Para adicionar a chave pública do cluster do Amazon Redshift ao arquivo de chaves autorizadas do host
-
Acesse o host usando uma conexão SSH.
Para obter informações sobre como se conectar a uma instância usando SSH, consulte Conectar-se à instância do Linux no Manual do usuário do Amazon EC2.
-
Copie a chave pública do Amazon Redshift do console ou do texto de resposta da CLI.
-
Copie e cole os conteúdos da chave pública no arquivo
/home/<ssh_username>/.ssh/authorized_keysno host. Inclua a string completa com o prefixo “ssh-rsa” e o sufixo “Amazon-Redshift”. Por exemplo:ssh-rsa AAAACTP3isxgGzVWoIWpbVvRCOzYdVifMrh… uA70BnMHCaMiRdmvsDOedZDOedZ Amazon-Redshift
Etapa 5: Configurar os hosts para aceitar todos os endereços IP do cluster do Amazon Redshift
Para permitir o tráfego de entrada para as instâncias do host, edite o grupo de segurança e adicione uma regra de entrada para cada nó de cluster do Amazon Redshift. Para Tipo, selecione SSH com protocolo TCP na porta 22. Em Source (Fonte), insira os endereços IP privados do nó do cluster do Amazon Redshift que você recuperou em Etapa 3: Recuperar a chave pública do cluster do Amazon Redshift e os endereços IP do nó do cluster. Para obter informações sobre como adicionar regras a um grupo de segurança do Amazon EC2, consulte Autorizar tráfego de entrada para as instâncias no Manual do usuário do Amazon EC2.
Etapa 6: Executar o comando COPY para carregar os dados
Execute um comando COPY para se conectar ao cluster do Amazon EMR e carregar os dados em uma tabela do Amazon Redshift. O cluster do Amazon EMR deve continuar em execução até que o comando COPY seja concluído. Por exemplo, não configure o encerramento automático do cluster.
Importante
Se um dos arquivos de dados for alterado ou excluído antes de COPY ser concluído, você poderá ter resultados inesperados ou a operação COPY poderá falhar.
No comando COPY, especifique o ID do cluster Amazon EMR e o caminho do arquivo HDFS e o nome do arquivo.
COPY sales FROM 'emr://myemrclusterid/myoutput/part*' CREDENTIALS IAM_ROLE 'arn:aws:iam::0123456789012:role/MyRedshiftRole';
Você pode usar caracteres curinga asterisco ( * ) e ponto de interrogação ( ? ) como parte do argumento do nome do arquivo. Por exemplo, part* carrega os arquivos part-0000, part-0001 e assim por diante. Se você especificar somente um nome de pasta, COPY tentará carregar todos os arquivos na pasta.
Importante
Se você usar caracteres curinga ou usar somente o nome da pasta, certifique-se de que nenhum arquivo indesejado seja carregado ou o comando COPY falhará. Por exemplo, alguns processos podem gravar um arquivo de log na pasta de saída.
