O Amazon Redshift deixará de oferecer suporte ao uso de UDFs em Python após 30 de junho de 2026. Começaremos a aplicar essa alteração em fases. Consulte mais informações sobre os detalhes do fim da vida útil do Python e as opções de migração na publicação do blog
Machine learning
O Amazon Redshift Machine Learning (Amazon Redshift ML) é um serviço robusto baseado em nuvem que ajuda analistas e cientistas de dados de todos os níveis de qualificação a usarem a tecnologia de Machine Learning. O Amazon Redshift ML usa um modelo para gerar resultados. É possível usar modelos das seguintes maneiras:
Você fornece os dados desejados para treinar um modelo e metadados associados a entradas de dados ao Amazon Redshift. Em seguida, o Amazon Redshift ML cria modelos no Amazon SageMaker AI que capturam padrões nos dados de entrada. Ao usar seus próprios dados para o modelo, você pode usar o Amazon Redshift ML para identificar tendências nos dados, como previsão de rotatividade, valor de permanência do cliente ou previsão de receita. Você pode usar esses modelos para gerar previsões para novos dados de entrada sem incorrer em custos adicionais.
É possível usar um dos modelos de base (FM) fornecidos pelo Amazon Bedrock, como Claude ou Amazon Titan. Usando o Amazon Bedrock, você pode combinar o poder dos grandes modelos de linguagem (LLMs) com data analytics no Amazon Redshift em apenas algumas etapas. Ao usar um grande modelo de linguagem (LLM) externo, você pode utilizar o Amazon Redshift para realizar processamento de linguagem natural (PLN) em seus dados. O PLN pode ser utilizado para aplicações como geração de texto, análise de sentimentos ou tradução. Para ter mais informações sobre como usar o Amazon Bedrock com o Amazon Redshift, consulte Integração do Amazon Redshift ML com o Amazon Bedrock.
nota
Optar por não usar seus dados para melhorar o serviço
Se você estiver usando modelos do Amazon Bedrock, é recomendável ler as políticas da AWS sobre como o serviço Amazon Bedrock lida com seus dados. Você deve determinar se precisa usar uma política de cancelamento para evitar que o serviço use seus dados para melhorias no modelo ou no serviço, caso o Amazon Bedrock implemente essa funcionalidade no futuro. Para garantir que o serviço não use seus dados para essas finalidades, use a política geral de cancelamento da AWS.
Para saber mais, consulte:
nota
Os LLMs podem gerar informações imprecisas ou incompletas. Recomendamos verificar as informações que os LLMs produzem para garantir que sejam precisas e completas.
Como o Amazon Redshift ML utiliza o Amazon SageMaker AI
O Amazon Redshift utiliza o Amazon SageMaker AI Autopilot para obter automaticamente o melhor modelo e disponibilizar a função de previsão no Amazon Redshift.
O diagrama a seguir ilustra como o Amazon Redshift ML funciona.
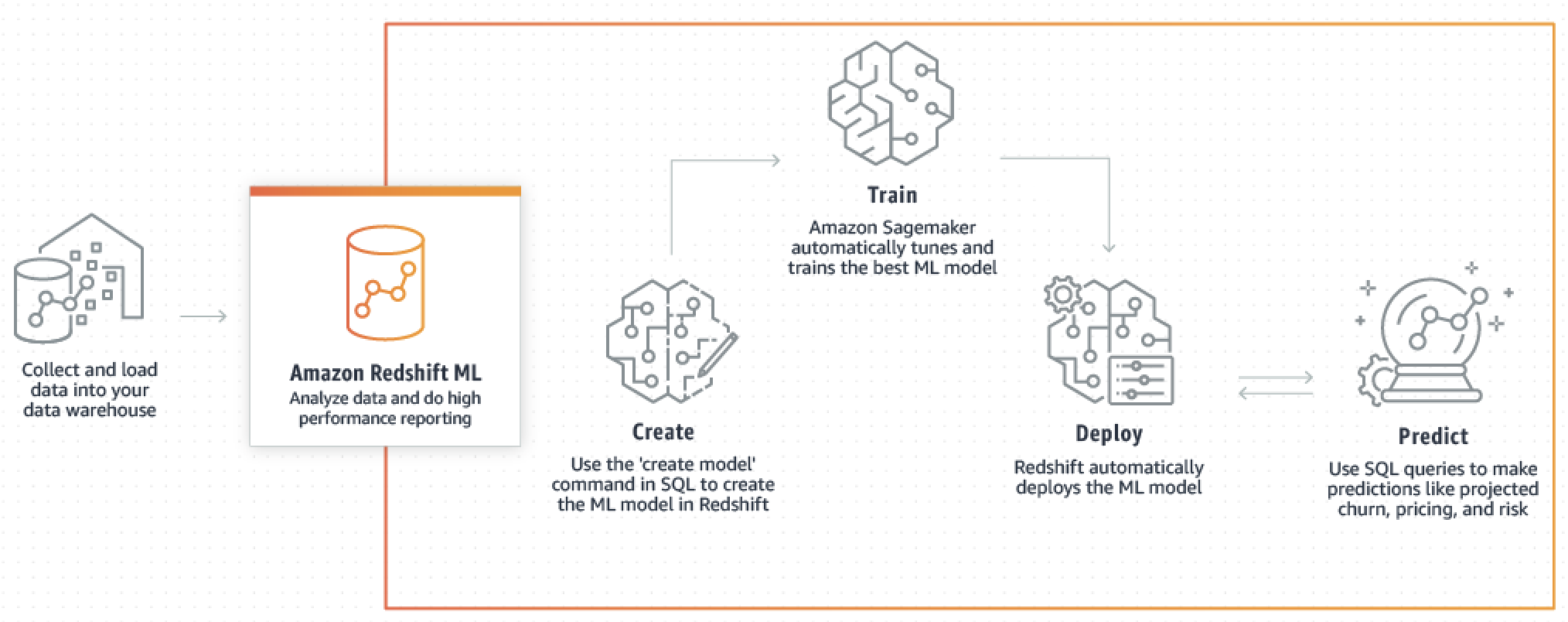
O fluxo de trabalho geral é o seguinte:
-
O Amazon Redshift exporta os dados de treinamento para o Amazon S3.
-
O Amazon SageMaker AI Autopilot pré-processa os dados de treinamento. O pré-processamento executa funções importantes, como a imputação de valores ausentes. Ele reconhece que certas colunas são categóricas (como o código postal), formata-as corretamente para treinamento e executa inúmeras outras tarefas. Escolher os melhores pré-processadores para aplicar no conjunto de dados de treinamento é um problema por si só, e o Amazon SageMaker AI Autopilot automatiza a respectiva solução.
-
O Amazon SageMaker AI Autopilot encontra o algoritmo e os hiperparâmetros do algoritmo que fornecem o modelo com as previsões mais precisas.
-
O Amazon Redshift registra a função de previsão como uma função SQL no cluster do Amazon Redshift.
-
Quando você executa instruções CREATE MODEL, o Amazon Redshift usa o Amazon SageMaker AI para treinamento. Portanto, há um custo associado para treinar seu modelo. Este é um item de linha separado para o Amazon SageMaker AI em seu faturamento da AWS. Você também paga pelo armazenamento usado no Amazon S3 para armazenar seus dados de treinamento. Não será cobrada a inferência que usa modelos criados com CREATE MODEL que podem ser compilados e executados no cluster do Amazon Redshift. Não há cobranças adicionais do Amazon Redshift para usar o Amazon Redshift ML.
Tópicos
