O Amazon Redshift não permitirá mais a criação de UDFs do Python a partir do Patch 198. As UDFs do Python existentes continuarão a funcionar normalmente até 30 de junho de 2026. Para ter mais informações, consulte a publicação de blog
Usar a visualização SVL_QUERY_SUMMARY
Para analisar as informações de resumo de consulta por fluxo usando SVL_QUERY_SUMMARY, faça o seguinte:
-
Execute a seguinte consulta para determinar o ID de sua consulta:
select query, elapsed, substring from svl_qlog order by query desc limit 5;Examine o texto truncado da consulta no campo
substringpara determinar qual valor dequeryrepresenta a sua consulta. Se você executou a consulta mais de uma vez, use o valor dequeryda linha com o menor valorelapsed. Esta é a linha para a versão compilada. Se você estiver executando várias consultas, poderá aumentar o valor usado pela cláusula LIMIT usada para certificar-se de que sua consulta seja incluída. -
Selecione linhas do SVL_QUERY_SUMMARY para sua consulta. Classifique os resultados por fluxo, segmento e etapa:
select * from svl_query_summary where query = MyQueryID order by stm, seg, step;Este é um resultado de exemplo.
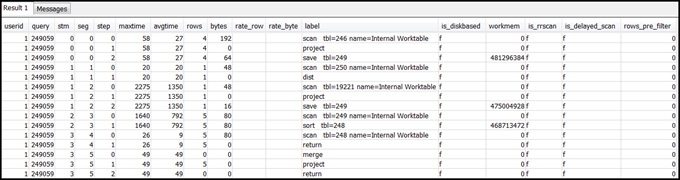
-
Mapeie as etapas às operações de consulta no plano de consulta usando as informações em Mapeamento do plano de consulta para o resumo da consulta. Elas devem ter aproximadamente os mesmos valores para linhas e bytes (linhas * largura do plano de consulta). Se elas não tiverem, consulte Estatísticas de tabela ausentes ou desatualizadas para as soluções recomendadas.
-
Verifique se o campo
is_diskbasedtem um valor det(verdadeiro) para qualquer etapa. Os hash, agregados e classificações são operadores que provavelmente irão gravar dados em disco se o sistema não tiver memória suficiente alocada para o processamento de consulta.Se
is_diskbasedfor verdadeiro, consulte Memória insuficiente alocada para a consulta para as soluções recomendadas. -
Revise os valores do campo
labele verifique se há uma sequência AGG-DIST-AGG em qualquer lugar das etapas. Sua presença indica a agregação em duas etapas, que é cara. Para corrigir isso, altere a cláusula GROUP BY para usar a chave de distribuição (a primeira chave, se houver várias). -
Revise o valor de
maxtimepara cada segmento (ele é o mesmo para todas as etapas no segmento). Identifique um segmento com o maior valor demaxtimee analise as etapas neste segmento quanto aos operadores a seguir.nota
Um valor
maxtimealto não necessariamente indica um problema com o segmento. Independente de um valor alto, o segmento pode não ter levado muito tempo para processar. Todos os segmentos em um fluxo começam a ser cronometrados simultaneamente. No entanto, alguns segmentos downstream podem não ser executados até obterem dados dos segmentos upstream. Este efeito pode fazer parecer que eles tenham levado muito tempo, pois seus valores demaxtimeincluirão tanto seu tempo de espera quanto o tempo de processamento.-
BCAST ou DIST: nesses casos, o valor
maxtimealto pode ser o resultado da redistribuição de um grande número linhas. Para soluções recomendadas, consulte Distribuição de dados pouco satisfatória. -
HJOIN (junção hash): Se a etapa em questão tem um valor muito elevado no campo de
rowsem comparação ao valor derowsna etapa final do RETURN da consulta, consulte Junção de hash para as soluções recomendadas. -
SCAN/SORT: procura uma sequência de etapas SCAN, SORT, SCAN, MERGE imediatamente antes de uma etapa de junção. Este padrão indica que os dados não classificados estão sendo varridos e, então, mesclados com a área classificada da tabela.
Verifique se o valor de linhas para a etapa SCAN tem um valor muito alto em comparação ao valor de linhas na etapa final de RETURN da consulta. Este padrão indica que o mecanismo de execução está fazendo a varredura de linhas que serão posteriormente rejeitadas, o que é ineficiente. Para soluções recomendadas, consulte Predicado insuficientemente restritivo.
Se o valor de
maxtimepara etapa SCAN é alto, consulte Cláusula WHERE pouco satisfatória para as soluções recomendadas.Se o valor de
rowspara a etapa SORT não for zero, consulte Linhas não classificadas ou mal classificadas para as soluções recomendadas.
-
-
Revise os valores de
rowsebytespara as etapas de 5 a 10 que precedem a etapa final RETURN para ter uma ideia da quantidade de dados que foi retornada ao cliente. Esse processo pode ser um tipo de arte.Por exemplo, no resumo de consulta de amostra a seguir, a terceira etapa de PROJECT fornece um valor de
rows, mas não um valor debytes. Ao examinarmos as etapas anteriores para encontrar uma etapa com o mesmo valor derows, encontramos a etapa SCAN, que fornece informações tanto de linha quanto de bytes:Veja a seguir um resultado de exemplo.
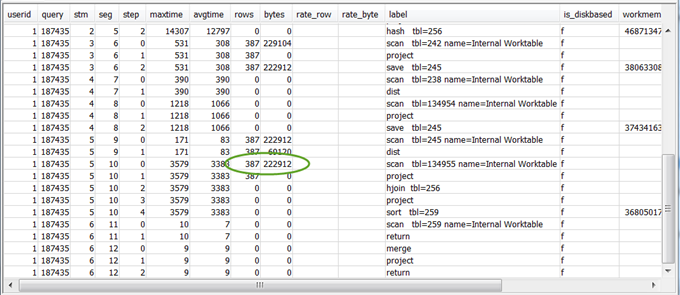
Se você estiver retornando um volume de dados inusitadamente alto, consulte Conjunto de resultados muito grande para as soluções recomendadas.
-
Verifique se o valor de
bytesé alto em relação ao valor derowspara qualquer etapa, em comparação a outras etapas. Este padrão pode indicar que você está selecionando muitas colunas. Para soluções recomendadas, consulte Lista SELECT grande.
