Minimizar tempos de limpeza
O Amazon Redshift classifica os dados automaticamente e executa VACUUM DELETE em segundo plano. Isso reduz a necessidade de executar o comando VACUUM. O processo de limpeza pode ser demorado. Dependendo da natureza dos dados, recomendamos seguir as práticas nesta seção para minimizar os tempos de limpeza.
Tópicos
Decidir sobre a reindexação
Frequentemente, você pode melhorar significativamente a performance da consulta usando um estilo intercalado de classificação, mas ao longo do tempo a performance pode se degradar se a distribuição de valores nas colunas de chaves de classificação alterar.
Ao carregar inicialmente uma tabela intercalada vazia usando COPY ou CREATE TABLE AS, o Amazon Redshift constrói automaticamente o índice intercalado. Se você inicialmente carregar uma tabela intercalada usando INSERT, você precisa executar um VACUUM REINDEX posteriormente para inicializar o índice intercalado.
Com o tempo, à medida que você adiciona linhas com novos valores de chave de classificação, a performance pode se degradar se a distribuição de valores nas colunas de chaves de classificação alterar. Se suas novas linhas caem principalmente no intervalo de valores de chave de classificação existente, você não precisa reindexar. Execute VACUUM SORT ONLY ou VACUUM FULL para restaurar a ordem de classificação.
O mecanismo de consulta é capaz de usar a ordem de classificação para selecionar com eficiência quais blocos de dados devem ser varridos para processar uma consulta. Para uma classificação intercalada, o Amazon Redshift analisa os valores da coluna de chave de classificação para determinar a ordem de classificação ideal. Se a distribuição dos valores de chave muda ou é distorcida à medida que linhas são adicionadas, a estratégia de classificação não será mais ideal e o benefício de performance de classificação se degradará. Para reanalisar a distribuição de chaves de classificação, você pode executar um VACUUM REINDEX. A operação de reindexação consome tempo, portanto para decidir se uma tabela se beneficiará de uma de reindexação, consulte a exibição SVV_INTERLEAVED_COLUMNS.
Por exemplo, a seguinte consulta exibe os detalhes de tabelas que usam chaves de classificação intercaladas.
select tbl as tbl_id, stv_tbl_perm.name as table_name, col, interleaved_skew, last_reindex from svv_interleaved_columns, stv_tbl_perm where svv_interleaved_columns.tbl = stv_tbl_perm.id and interleaved_skew is not null;tbl_id | table_name | col | interleaved_skew | last_reindex --------+------------+-----+------------------+-------------------- 100048 | customer | 0 | 3.65 | 2015-04-22 22:05:45 100068 | lineorder | 1 | 2.65 | 2015-04-22 22:05:45 100072 | part | 0 | 1.65 | 2015-04-22 22:05:45 100077 | supplier | 1 | 1.00 | 2015-04-22 22:05:45 (4 rows)
O valor para interleaved_skew é uma proporção que indica a quantidade de distorção. Um valor de 1 significa que não há distorção. Se a distorção for maior que 1,4, um VACUUM REINDEX melhorará a performance a menos que a distorção seja inerente ao conjunto subjacente.
Você pode usar o valor de data em last_reindex para determinar quanto tempo se passou desde a última reindexação.
Reduzir o tamanho da região não classificada
A região não classificada aumenta quando você carrega grandes quantidades de novos dados em tabelas que já contêm dados ou quando você não limpa as tabelas como parte de suas operações de manutenção de rotina. Para evitar operações de limpeza de longa execução, use as seguintes práticas:
-
Execute operações de limpeza em uma programação regular.
Se você carregar suas tabelas em pequenos incrementos (tal como atualizações diárias que representam uma pequena porcentagem do número total de linhas na tabela), a execução de VACUUM regularmente ajudará a garantir que operações individuais de limpeza ocorram rapidamente.
-
Execute o maior carregamento primeiro.
Se você precisar carregar uma nova tabela com várias operações COPY, execute o maior carregamento primeiro. Quando você executa um carregamento inicial em uma tabela nova ou truncada, todos os dados são carregados diretamente na região classificada, portanto nenhuma limpeza é necessária.
-
Trunque uma tabela em vez de excluir todas as linhas.
A exclusão de linhas de uma tabela não recupera o espaço que as linhas ocupavam até que você execute uma operação de limpeza; entretanto, truncar uma tabela esvazia a tabela e recupera o espaço em disco, portanto nenhuma limpeza é necessária. Como alternativa, descarte a tabela e volte a criá-la.
-
Trunque ou descarte tabelas de teste.
Se você estiver carregando um pequeno número de linhas em uma tabela para fins de teste, não exclua as linhas quando tiver terminado. Em vez disso, trunque a tabela e recarregue essas linhas como parte da operação de carregamento de produção subsequente.
-
Execute uma cópia profunda.
Se uma tabela que usa uma chave de classificação composta tem uma grande região não classificada, uma cópia profunda é muito mais rápida que um vacuum. Uma cópia profunda recria e preenche novamente uma tabela usando uma inserção em massa, que reclassifica a tabela automaticamente. Se uma tabela tem uma grande região não classificada, uma cópia profunda é muito mais rápida que um vacuum. A diferença é que você não pode realizar atualizações simultâneas durante uma operação de cópia profunda, o que pode ocorrer durante um vacuum. Para ter mais informações, consulte Práticas recomendadas do Amazon Redshift para criar consultas.
Reduzir o volume de linhas mescladas
Se uma operação de limpeza precisar mesclar novas linhas na região classificada de uma tabela, o tempo necessário para uma limpeza aumentará à medida que a tabela crescer. Você pode melhorar a performance da limpeza reduzindo o número de linhas que devem ser mescladas.
Antes de uma limpeza, uma tabela consiste em uma região classificada no topo da tabela, seguida por uma região não classificada, que aumenta sempre que linhas são adicionadas ou atualizadas. Quando um conjunto de linhas é adicionado por uma operação COPY, o novo conjunto de linhas é classificado na chave de classificação à medida que é adicionado à região não classificada no final da tabela. As novas linhas são ordenadas dentro de seu próprio conjunto, mas não na região não classificada.
O diagrama a seguir ilustra a região não classificada após duas operações COPY sucessivas, onde a chave de classificação é CUSTID. Por simplicidade, este exemplo mostra uma chave de classificação composta, mas os mesmos princípios se aplicam à chaves de classificação intercaladas, salvo que o impacto da região não classificada é maior para tabelas intercaladas.
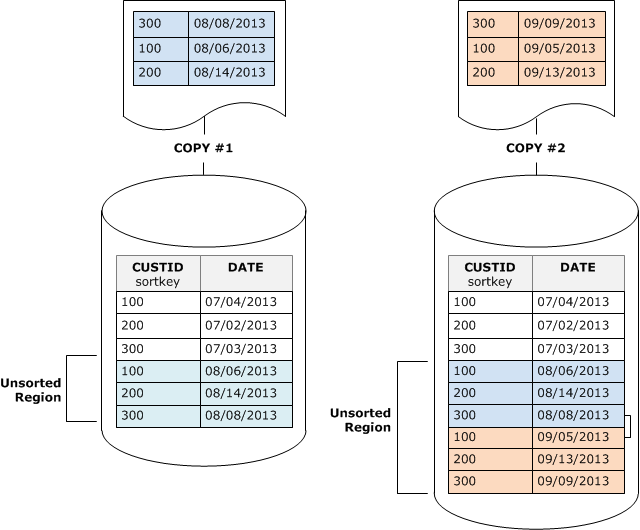
Uma limpeza restaura a ordem de classificação de uma tabela em duas etapas:
-
Classifique a região não classificada em uma região recém-classificada.
A primeira etapa é relativamente barata, pois somente a região não classificada é regravada. Se o intervalo de valores de chave de classificação da região recém-classificada for maior que o intervalo existente, somente as novas linhas precisarão ser regravadas e a limpeza será concluída. Por exemplo, se a região classificada contém valores de ID de 1 a 500 e as operações copy subsequentes adicionam valores de chave maiores que 500, então somente a região não classificada precisa ser regravada.
-
Mesclagem da região recém-classificada com a região previamente classificada.
Se as chaves na região classificada recentemente classificada sobrepõem-se às chaves da região classificada, VACUUM precisa mesclar as linhas. Começando no início da região recém-classificada (a chave de classificação mais baixa), a limpeza grava as linhas mescladas da região previamente classificada e a região recém classificada em um novo conjunto de blocos.
A extensão com que o novo intervalo de chaves de classificação sobrepõe as chaves de classificação existentes determina a extensão na qual a região previamente classificada deve ser regravada. Se as chaves não classificadas estão espalhadas pelo intervalo de classificação existente, a limpeza pode precisar regravar porções existentes da tabela.
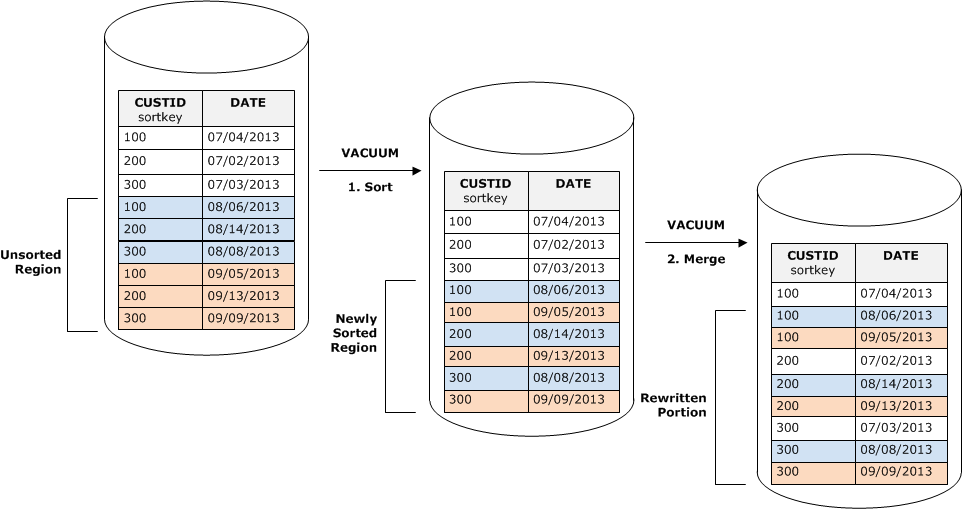
O diagrama a seguir mostra como uma limpeza classificaria e mesclaria as linhas que são adicionadas em uma tabela em que CUSTID é a chave de classificação. Como cada operação copy adiciona um novo conjunto de linhas com valores de chave que se sobrepõem às chaves existente, quase toda a tabela precisa ser regravada. O diagrama mostra uma única classificação e mesclagem, mas na prática, uma grande limpeza consiste em uma serie de etapas de classificação e mesclagem incrementais.
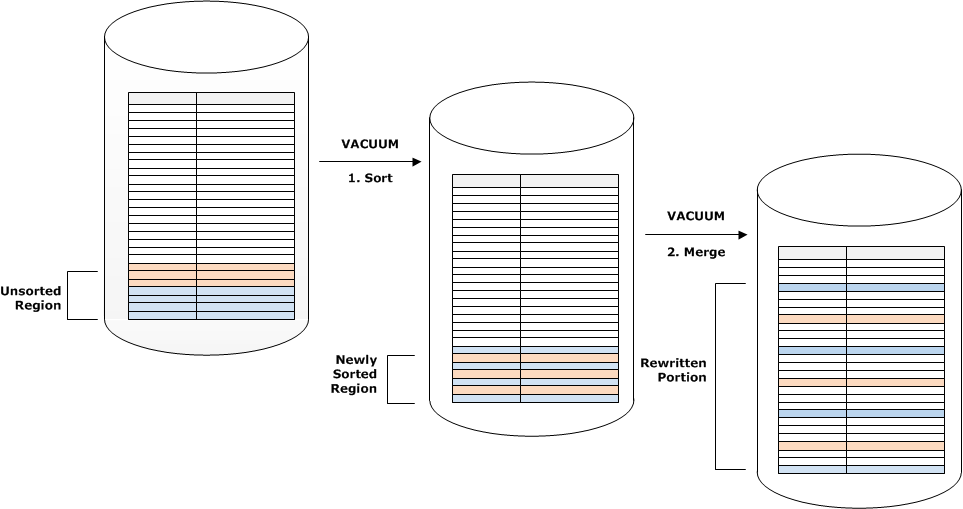
Se o intervalo de chaves de classificação em um novo conjunto de linhas sobrepõe o intervalo de chaves existente, o custo da etapa de mesclagem continua crescendo na proporção do tamanho da tabela à medida que ela cresce, enquanto o custo da etapa de classificação permanece proporcional ao tamanho da região não classificada. Nesse caso, o custo da etapa de mesclagem ofusca o custo da etapa de classificação, conforme exibido no diagrama a seguir.
Para determinar que proporção de uma tabela foi remesclada, consulte SVV_VACUUM_SUMMARY após a conclusão da operação de limpeza. A seguir consulta exibe os efeitos de seis limpezas consecutivas à medida que CUSTSALES cresceu ao longo do tempo.
select * from svv_vacuum_summary where table_name = 'custsales';table_name | xid | sort_ | merge_ | elapsed_ | row_ | sortedrow_ | block_ | max_merge_ | | partitions | increments | time | delta | delta | delta | partitions -----------+------+------------+------------+------------+-------+------------+---------+--------------- custsales | 7072 | 3 | 2 | 143918314 | 0 | 88297472 | 1524 | 47 custsales | 7122 | 3 | 3 | 164157882 | 0 | 88297472 | 772 | 47 custsales | 7212 | 3 | 4 | 187433171 | 0 | 88297472 | 767 | 47 custsales | 7289 | 3 | 4 | 255482945 | 0 | 88297472 | 770 | 47 custsales | 7420 | 3 | 5 | 316583833 | 0 | 88297472 | 769 | 47 custsales | 9007 | 3 | 6 | 306685472 | 0 | 88297472 | 772 | 47 (6 rows)
A coluna merge_increments fornece uma indicação da quantidade de dados que foram mesclados em cada operação de limpeza. Se o número de incrementos de mesclagem ao longo de limpezas consecutivas aumentar em proporção ao crescimento do tamanho da tabela, isso é uma indicação de que cada operação de limpeza está mesclando novamente um número crescente de linhas na tabela em decorrência da sobreposição das regiões classificadas existentes e novas.
Carregar os dados por ordem de chave de classificação
Se você carregar os dados na ordem da chave de classificação usando o comando COPY, poderá reduzir ou até mesmo eliminar a necessidade de limpeza.
COPY adiciona automaticamente linhas novas à região classificada da tabela quando todas as seguintes opções são verdadeiras:
-
A tabela usa uma chave de classificação composta com somente uma coluna de classificação.
-
A coluna de classificação é NOT NULL.
-
A tabela está 100 por cento classificada ou vazia.
-
Todas as linhas novas são mais altas na ordem de classificação que as linhas existentes, incluindo as linhas marcadas para exclusão. Nesse caso, o Amazon Redshift usa os primeiros oito bytes da chave de classificação para determinar a ordem de classificação.
Por exemplo, suponha que você tenha uma tabela que registre eventos de clientes usando um ID de cliente e hora. Se você classificar pelo ID de cliente, é provável que o intervalo de chaves de classificação de novas linhas adicionadas por carregamentos incrementais se sobreponha ao intervalo existente, conforme mostrado no exemplo anterior, resultando em uma operação de limpeza dispendiosa.
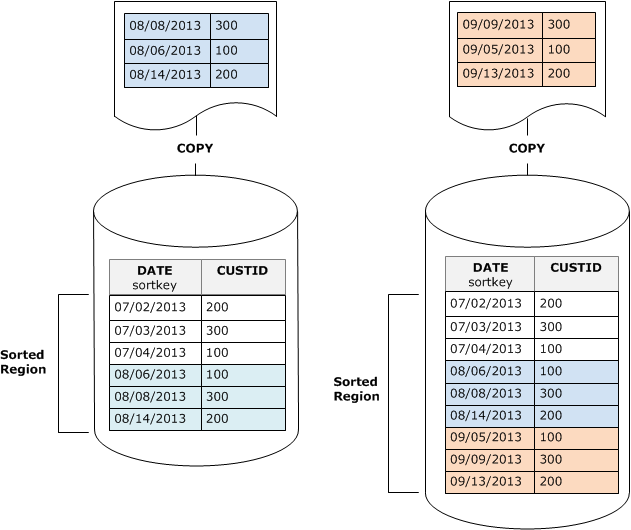
Se você definir sua chave de classificação como uma coluna de carimbo de data/hora, suas novas linhas serão anexadas por ordem de classificação no final da tabela, conforme exibido no diagrama a seguir, reduzindo ou até eliminando a necessidade de limpeza.
Usar tabelas de séries temporais para reduzir os dados armazenados
Se você mantém dados para um período de rolamento, use uma série de tabelas, como o diagrama a seguir ilustra.
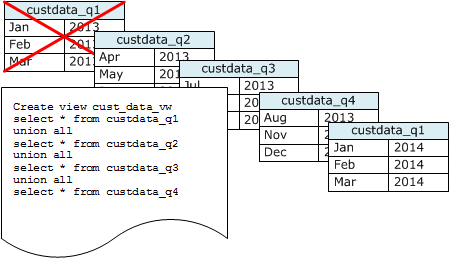
Crie uma nova tabela sempre que você adicionar um conjunto de dados e, então, exclua a tabela mais velha da série. Você obtém um benefício duplo:
-
Você evita o custo adicional da exclusão das linhas, pois uma operação DROP TABLE é muito mais eficiente que um DELETE em massa.
-
Se as tabelas são classificadas por timestamp, nenhuma limpeza é necessária. Se cada tabela contém os dados para um mês, uma limpeza no máximo terá que regravar um mês de dados, mesmo que as tabelas não estejam classificadas por timestamp.
Você pode criar uma exibição UNION ALL para uso reportando consultas que ocultam o fato de que os dados são armazenados em várias tabelas. Se uma consulta filtrar na chave de classificação, o planejador de consulta pode eficientemente ignorar todas as tabelas que não são usadas. Um UNION ALL pode ser menos eficiente para outros tipos de consultas, portanto você deve avaliar a performance de consultas no contexto de todas as consultas que utilizam as tabelas.
