Visualizar um relatório de desempenho do modelo do Autopilot
Um relatório de qualidade de modelo do Amazon SageMaker (também chamado de relatório de desempenho) fornece insights e informações de qualidade para o melhor candidato a modelo gerado por um trabalho do AutoML. Isso inclui informações sobre os detalhes do trabalho, o tipo de problema do modelo, a função objetivo e outras informações relacionadas ao tipo de problema. Este guia mostra como visualizar graficamente as métricas de desempenho do Amazon SageMaker Autopilot ou visualizar métricas como dados brutos em um arquivo JSON.
Por exemplo, em problemas de classificação, o relatório de qualidade do modelo inclui o seguinte:
-
Matriz de confusão
-
Área sob a curva característica de operação do receptor (AUC)
-
Informações para entender falsos positivos e falsos negativos
-
Compensações entre verdadeiros positivos e falsos positivos
-
Compensações entre precisão e recuperação
O Autopilot também fornece métricas de desempenho para todos os seus modelos candidatos. Essas métricas são calculadas usando todos os dados de treinamento e são usadas para estimar o desempenho do modelo. A área de trabalho principal inclui essas métricas por padrão. O tipo de métrica é determinado pelo tipo de problema que está sendo tratado.
Consulte a documentação de referência da API do Amazon SageMaker para ver a lista de métricas disponíveis compatíveis com o Autopilot.
Você pode classificar seus candidatos a modelo com a métrica relevante para ajudá-lo a selecionar e implantar o modelo que atenda às suas necessidades comerciais. Para obter definições dessas métricas, consulte o tópico Métricas de candidatos do Autopilot.
Para visualizar um relatório de desempenho de um trabalho do Autopilot, siga estas etapas:
-
Escolha o ícone Início (
 ) no painel de navegação esquerdo para visualizar o menu de navegação de nível superior do Amazon SageMaker Studio Classic.
) no painel de navegação esquerdo para visualizar o menu de navegação de nível superior do Amazon SageMaker Studio Classic. -
Selecione o cartão AutoML na área de trabalho principal. Isso abre uma nova guia do Autopilot.
-
Na seção Nome, selecione a trabalho do Autopilot que tem os detalhes que você deseja examinar. Isso abre uma nova guia de trabalhos do Autopilot.
-
O painel de trabalhos do Autopilot lista os valores métricos, incluindo a métrica objetiva de cada modelo em Nome do modelo. O melhor modelo está listado no topo da lista, em Nome do modelo e é destacado na guia Modelos.
-
Para revisar os detalhes do modelo, selecione o modelo em que você está interessado e selecione Visualizar detalhes no modelo. Isso abre uma nova guia Detalhes do modelo.
-
-
Escolha a guia Performance entre as guias Explicabilidade e Artefatos.
-
Na seção superior direita da guia, selecione a seta para baixo no botão Fazer o download de relatórios de desempenho.
-
A seta para baixo fornece duas opções para visualizar as métricas de desempenho do Autopilot:
-
Você pode baixar um PDF do relatório de desempenho para visualizar as métricas graficamente.
-
Você pode ver as métricas como dados brutos e baixá-las como um arquivo JSON.
-
-
Para obter instruções sobre como criar e executar um trabalho de AutoML no SageMaker Studio Classic, consulte Crie trabalhos de regressão ou classificação para dados tabulares com a API do AutoML.
O relatório de desempenho contém duas seções. O primeiro contém detalhes sobre o trabalho do Autopilot que produziu o modelo. A segunda seção contém um relatório de qualidade do modelo.
Detalhes do trabalho do Autopilot
Esta primeira seção do relatório fornece algumas informações gerais sobre o trabalho do Autopilot que produziu o modelo. Esses trabalhos incluem as seguintes informações:
-
Nome do candidato do Autopilot
-
Nome do trabalho do Autopilot
-
Tipo de problema
-
Métrica objetiva
-
Direção de otimização
Relatório de qualidade do modelo
As informações de qualidade do modelo são geradas pelos insights de modelo do Autopilot. O conteúdo do relatório gerado depende do tipo de problema abordado: regressão, classificação binária ou classificação multiclasse. O relatório especifica o número de linhas que foram incluídas no conjunto de dados da avaliação e a hora em que a avaliação ocorreu.
Tabelas de métricas
A primeira parte do relatório de qualidade do modelo contém tabelas de métricas. Eles são apropriados para o tipo de problema abordado pelo modelo.
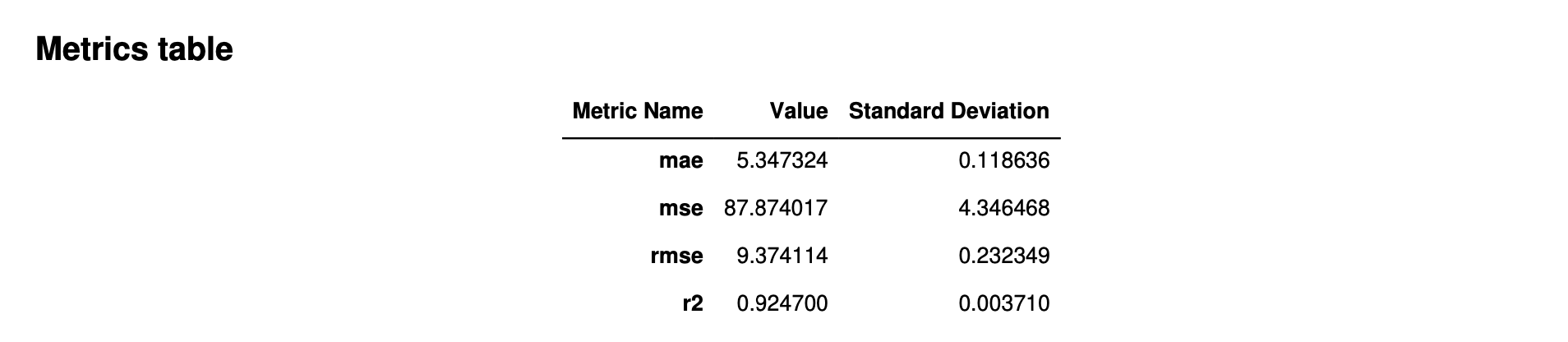
A imagem a seguir é um exemplo de uma tabela de métricas que o Autopilot gera para um problema de regressão. Ele mostra o nome, o valor e o desvio padrão da métrica.
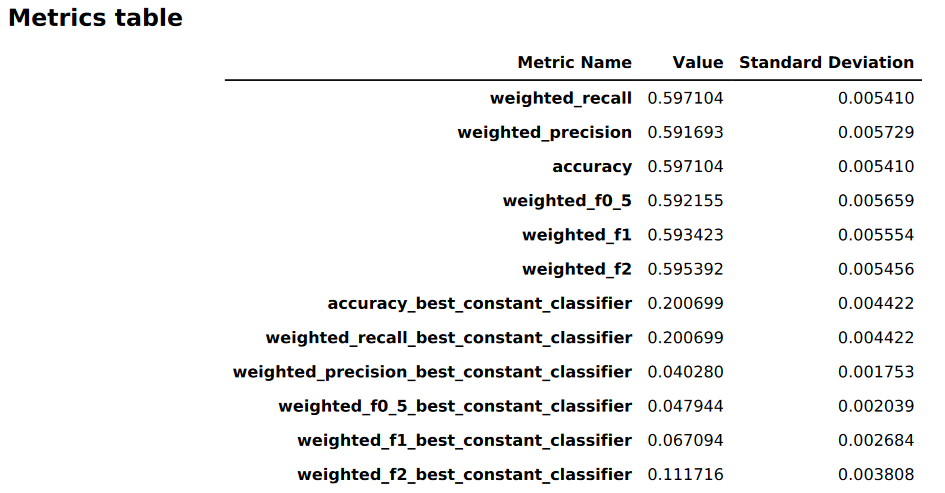
A imagem a seguir é um exemplo de uma tabela de métricas gerada pelo Autopilot para um problema de classificação multiclasse. Ele mostra o nome, o valor e o desvio padrão da métrica.
Informações gráficas de desempenho do modelo
A segunda parte do relatório de qualidade do modelo contém informações gráficas para ajudá-lo a avaliar o desempenho do modelo. O conteúdo desta seção depende do tipo de problema usado na modelagem.
A área sob a curva de característica de operação do receptor
A área abaixo da curva característica de operação do receptor representa a concessão entre as taxas de verdadeiro positivo e falso positivo. É uma métrica de precisão padrão do setor usada para modelos de classificação binária. A AUC (área sob a curva) mede a capacidade do modelo de prever uma pontuação maior de exemplos positivos em comparação com os exemplos negativos. A métrica AUC fornece uma medida agregada do desempenho do modelo em todos os limites de classificação possíveis.
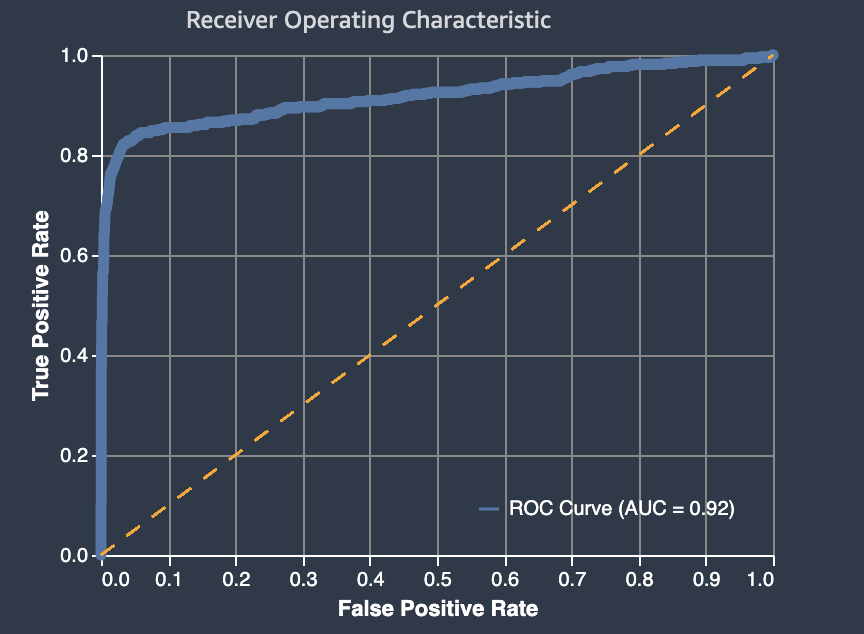
A métrica de AUC retorna um valor decimal de 0 a 1. Os valores de AUC quase de 1 indicam que um modelo de machine learning é altamente preciso. Os valores próximos a 0,5 indicam que um modelo de ML não é melhor do que a adivinhação aleatória. Valores de AUC próximos a 0 indicam que o modelo aprendeu os padrões corretos, mas está fazendo predições tão imprecisas quanto possível. Valores próximos de zero podem indicar um problema com os dados. Para obter mais informações sobre a métrica AUC, consulte o artigo Característica de operação do receptor
Veja a seguir um exemplo de uma área sob o gráfico da curva característica de operação do receptor para avaliar as predições feitas por um modelo de classificação binária. A linha fina tracejada representa a área sob a curva característica de operação do receptor que um modelo que classifica adivinhações não melhores do que aleatórias pontuaria, com uma pontuação de AUC de 0,5. As curvas dos modelos de classificação mais precisos estão acima dessa linha de base aleatória, em que a taxa de verdadeiros positivos excede a taxa de falsos positivos. A área sob a curva característica de operação do receptor que representa o desempenho do modelo de classificação binária é a linha sólida mais espessa.
Um resumo dos componentes do gráfico da taxa de falsos positivos (FPR) e da taxa de positivos verdadeiros (TPR) é definido da seguinte forma:
-
Previsões corretas
-
Positivo verdadeiro (PV): o valor previsto é 1 e o valor verdadeiro é 1.
-
Negativo verdadeiro (NV): o valor previsto é 0 e o valor verdadeiro é 0.
-
-
Previsões incorretas
-
Falso positivo (FP): o valor previsto é 1, mas o valor verdadeiro é 0.
-
Falso negativo (FN): o valor previsto é 0, mas o valor verdadeiro é 1.
-
A taxa de falsos-positivos (FPR) mede a fração de verdadeiros negativos (TN) que foram falsamente previstos como positivos (FP), sobre a soma de FP e TN. O intervalo é de 0 a 1. Um valor menor indica melhor precisão preditiva.
-
FPR = FP/ (FP+TN)
A taxa de positivos verdadeiros (TPR) mede a fração de verdadeiros positivos que foram corretamente previstos como positivos (TP) sobre a soma de TP e falsos negativos (FN). O intervalo é de 0 a 1. Um valor maior indica melhor precisão preditiva.
-
TPR = TP/(TP+FN)
Matriz de confusão
Uma matriz de confusão fornece uma maneira de visualizar a precisão das predições feitas por um modelo para classificação binária e multiclasse para problemas diferentes. A matriz de confusão no relatório de qualidade do modelo contém o seguinte:
-
O número e a porcentagem de predições corretas e incorretas para os rótulos reais
-
O número e a porcentagem de predições precisas na diagonal do canto superior esquerdo ao canto inferior direito
-
O número e a porcentagem de predições imprecisas na diagonal do canto superior direito ao canto inferior esquerdo
As predições incorretas em uma matriz de confusão são os valores de confusão.
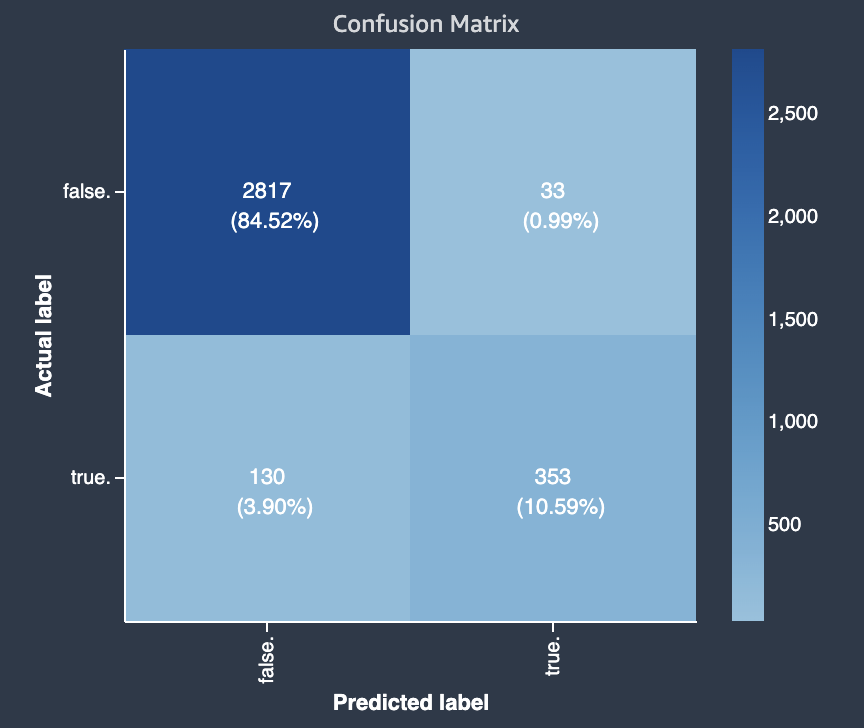
O diagrama a seguir é um exemplo de matriz de confusão para um problema de classificação multiclasse. Ela contém as seguintes informações:
-
O eixo vertical é dividido em duas linhas contendo rótulos reais verdadeiros e falsos.
-
O eixo horizontal é dividido em duas colunas contendo rótulos verdadeiros e falsos que foram previstos pelo modelo.
-
A barra de cores atribui um tom mais escuro a um número maior de amostras para indicar visualmente o número de valores que foram classificados em cada categoria.
Neste exemplo, o modelo previu corretamente 2817 valores falsos reais e 353 valores reais verdadeiros corretamente. O modelo previu incorretamente 130 valores reais verdadeiros como falsos e 33 valores reais falsos como verdadeiros. A diferença de tom indica que o conjunto de dados não está balanceado. O desequilíbrio ocorre porque há muito mais rótulos falsos reais do que rótulos verdadeiros.
O diagrama a seguir é um exemplo de matriz de confusão para um problema de classificação multiclasse. A matriz de confusão no relatório de qualidade do modelo contém o seguinte:
-
O eixo vertical é dividido em três linhas contendo três rótulos reais diferentes.
-
O eixo horizontal é dividido em três colunas contendo rótulos que foram previstos pelo modelo.
-
A barra de cores atribui um tom mais escuro a um número maior de amostras para indicar visualmente o número de valores que foram classificados em cada categoria.
No exemplo abaixo, o modelo previu corretamente os valores reais de 354 para o rótulo f, 1094 valores para o rótulo i e 852 valores para o rótulo m. A diferença de tom indica que o conjunto de dados não está balanceado porque há muito mais rótulos para o valor i do que para f ou m.
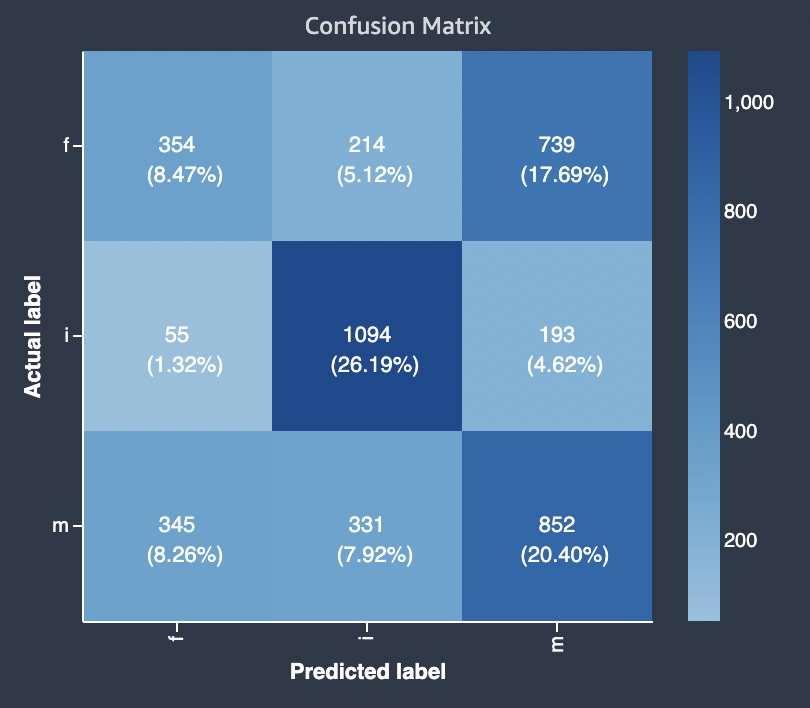
A matriz de confusão no relatório de qualidade do modelo fornecido pode acomodar no máximo 15 rótulos para tipos de problemas de classificação multiclasse. Se uma linha correspondente a um rótulo mostrar um valor Nan, isso significa que o conjunto de dados de validação usado para verificar as predições de modelo não contém dados com esse rótulo.
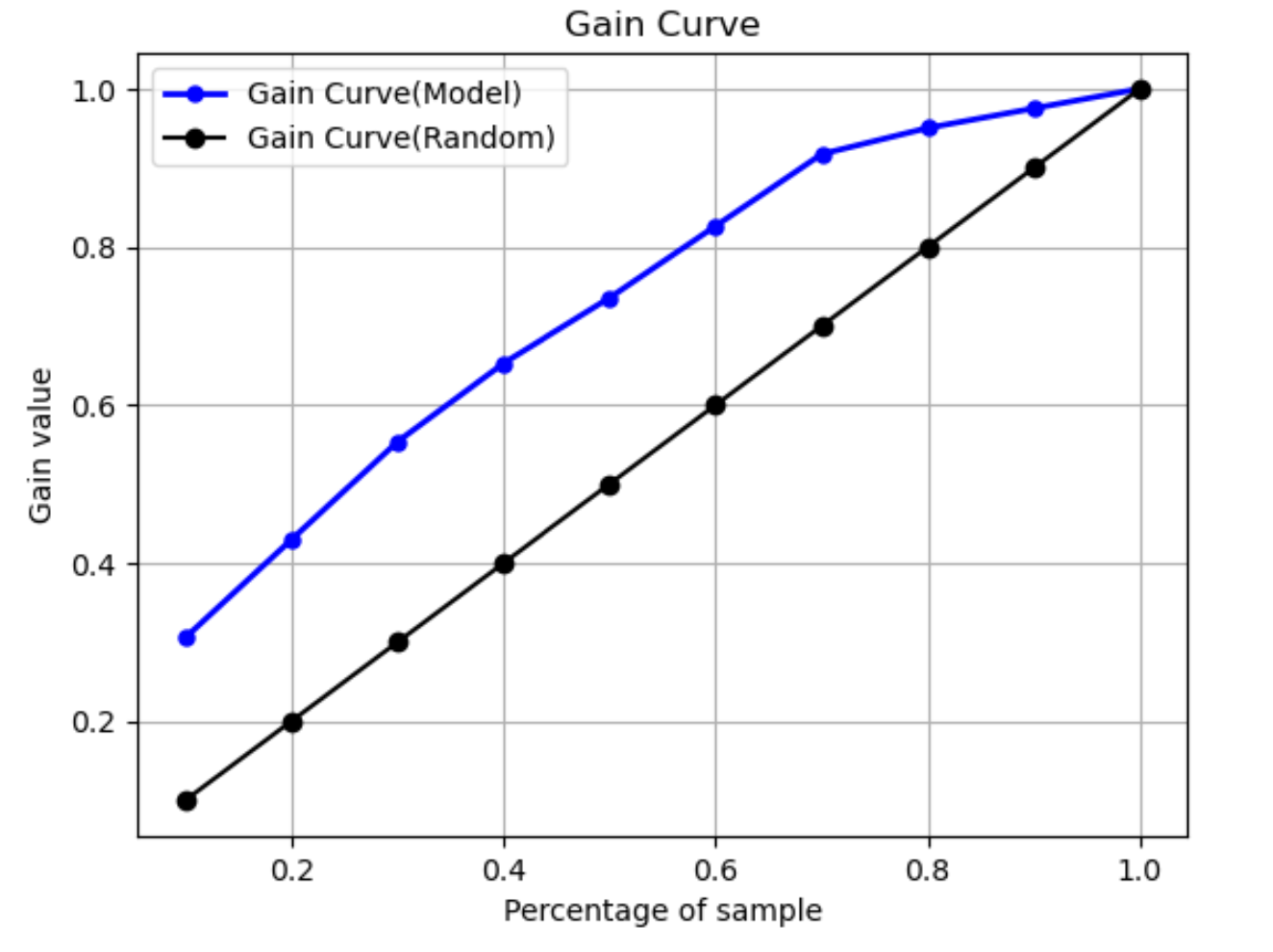
Curva de ganho
Na classificação binária, uma curva de ganho prevê o benefício cumulativo de usar uma porcentagem do conjunto de dados para encontrar um rótulo positivo. O valor do ganho é calculado durante o treinamento dividindo o número cumulativo de observações positivas pelo número total de observações positivas nos dados, em cada decil. Se o modelo de classificação criado durante o treinamento for representativo dos dados não vistos, você poderá usar a curva de ganho para prever a porcentagem de dados que deve ser segmentada para obter uma porcentagem de rótulos positivos. Quanto maior a porcentagem do conjunto de dados usado, maior a porcentagem de rótulos positivos encontrados.
No gráfico de exemplo a seguir, a curva de ganho é a linha com inclinação variável. A linha reta é a porcentagem de rótulos positivos encontrados ao selecionar aleatoriamente uma porcentagem de dados do conjunto de dados. Ao atingir 20% do conjunto de dados, você esperaria encontrar mais de 40% dos rótulos positivos. Como exemplo, você pode considerar o uso de uma curva de ganho para determinar seus esforços em uma campanha de marketing. Usando nosso exemplo de curva de ganho, para 83% das pessoas em um bairro comprarem biscoitos, você enviaria um anúncio para cerca de 60% do bairro.
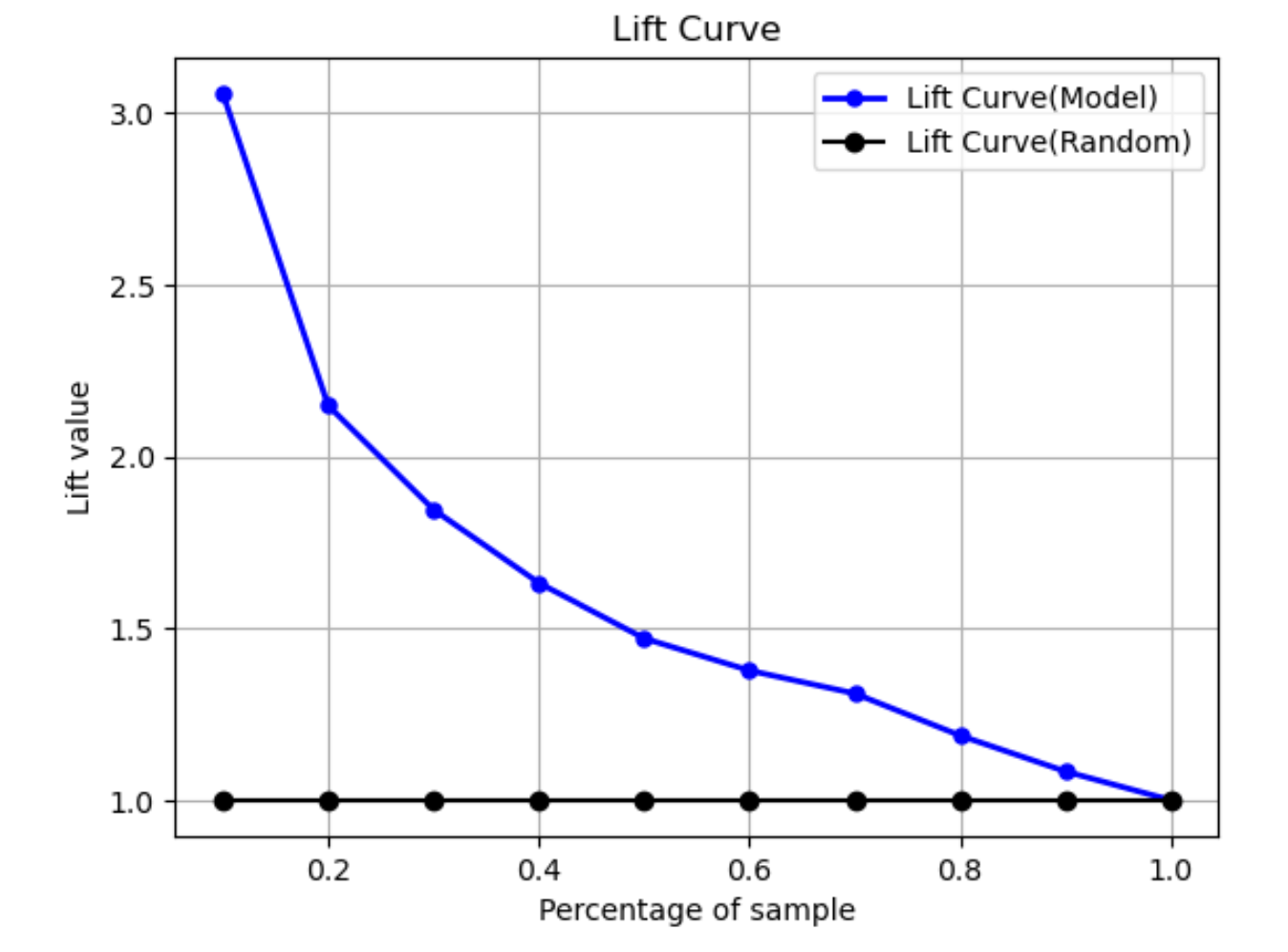
Curva de elevação
Na classificação binária, a curva de elevação ilustra o aumento do uso de um modelo treinado para prever a probabilidade de encontrar um rótulo positivo em comparação com uma suposição aleatória. O valor de elevação é calculado durante o treinamento usando a razão entre o ganho percentual e a proporção de rótulos positivos em cada decil. Se o modelo criado durante o treinamento for representativo dos dados não vistos, use a curva de elevação para prever a vantagem de usar o modelo em vez de adivinhar aleatoriamente.
No gráfico de exemplo a seguir, a curva de elevação é a linha com inclinação variável. A linha reta é a curva de elevação associada à seleção aleatória da porcentagem correspondente do conjunto de dados. Ao atingir 40% do conjunto de dados com os rótulos de classificação do seu modelo, você esperaria encontrar cerca de 1,7 vezes o número de rótulos positivos que teria encontrado ao selecionar aleatoriamente 40% dos dados não vistos.
Curva de recuperação de precisão
A curva de recuperação de precisão representa a compensação entre precisão e recuperação para problemas de classificação binária.
A precisão mede a fração de positivos reais que são previstos como positivos (TP) de todas as predições positivas (TP e falsos positivos). O intervalo é de 0 a 1. Um valor maior indica melhor precisão nos valores previstos.
-
Precisão = TP/(TP+FP)
Recall mede a fração de positivos reais que são previstos como positivos (PV) de todas as predições positivas (PP e falsos negativos). Isso também é conhecido como a sensibilidade ou como a taxa positiva verdadeira. O intervalo é de 0 a 1. Um valor maior indica uma melhor detecção de valores positivos da amostra.
-
Recuperação = TP/(TP+FN)
O objetivo de um problema de classificação é rotular corretamente o maior número possível de elementos. Um sistema com alto recall, mas baixa precisão, retorna uma alta porcentagem de falsos positivos.
O gráfico a seguir mostra um filtro de spam que marca todos os e-mails como spam. Tem alto recall, mas baixa precisão, porque o recall não mede falsos positivos.
Dê mais peso ao recall do que à precisão se seu problema tiver uma penalidade baixa por valores falsos positivos, mas uma penalidade alta por perder um resultado verdadeiro positivo. Por exemplo, detectar uma colisão iminente em um veículo autônomo.
Por outro lado, um sistema com alta precisão, mas com baixa recuperação, retorna uma alta porcentagem de falsos negativos. Um filtro de spam que marca cada e-mail como desejável (não spam) tem alta precisão, mas baixa recuperação, pois a precisão não mede falsos negativos.
Se seu problema tem uma penalidade baixa por valores falsos negativos, mas uma penalidade alta por perder resultados negativos verdadeiros, dê mais peso à precisão do que à recuperação. Por exemplo, sinalizar um filtro suspeito para uma auditoria fiscal.
O gráfico a seguir mostra um filtro de spam que tem alta precisão, mas baixa recuperação, porque a precisão não mede falsos negativos.
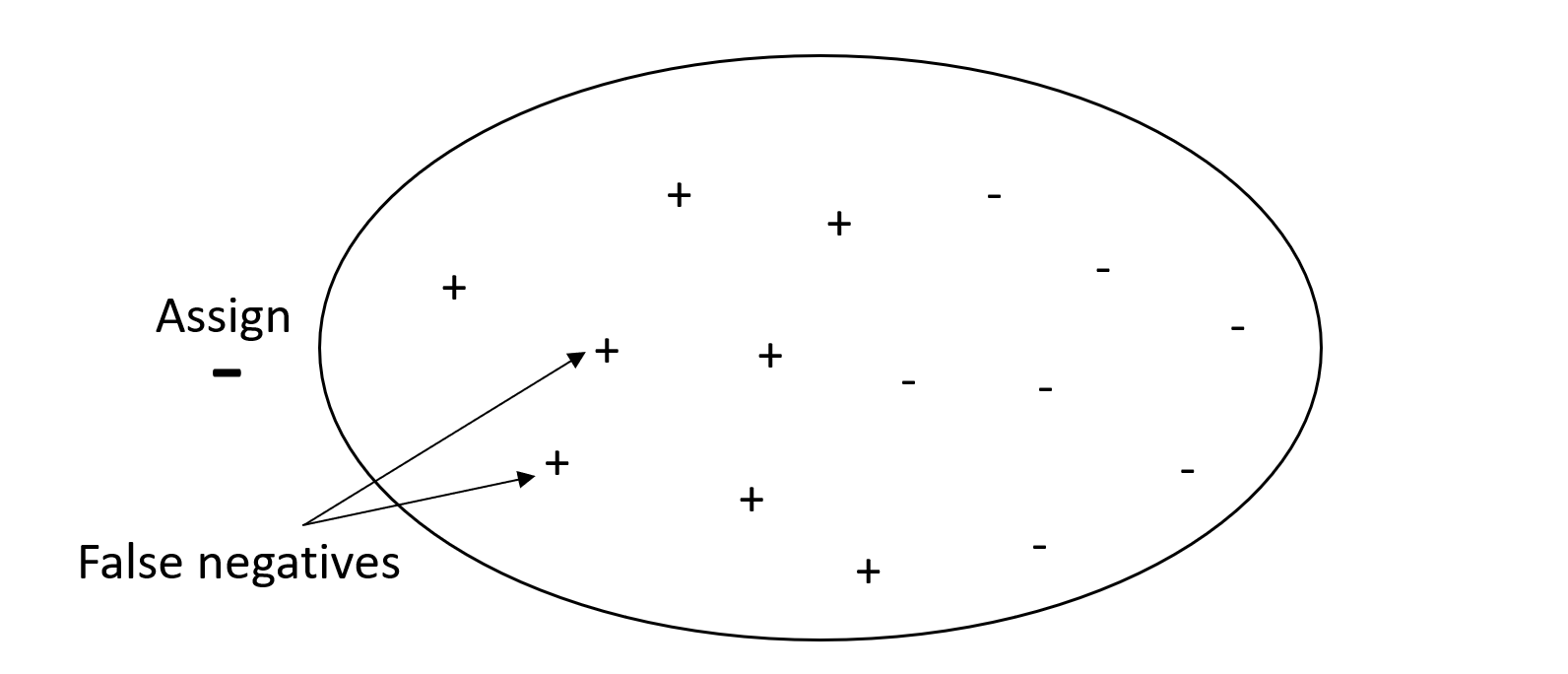
Um modelo que faz predições com alta precisão e alta recuperação produz um grande número de resultados rotulados corretamente. Para obter mais informações, consulte o artigo Precisão e recordar
Área sob a curva de recuperação de precisão (AUPRC)
Para problemas de classificação binária, o Amazon SageMaker Autopilot inclui um gráfico da área sob a curva de recuperação de precisão (AUPRC). A métrica AUPRC fornece uma medida agregada do desempenho do modelo em todos os limites de classificação possíveis e usa precisão e recuperação. O AUPRC não leva em consideração o número de negativos verdadeiros. Portanto, pode ser útil avaliar o desempenho do modelo nos casos em que há um grande número de pontos negativos verdadeiros nos dados. Por exemplo, para modelar um gene contendo uma mutação rara.
O gráfico a seguir é um exemplo de um gráfico AUPRC. A precisão em seu valor mais alto é 1 e a recuperação está em 0. No canto inferior direito do gráfico, recall é o valor mais alto (1) e a precisão é 0. Entre esses dois pontos, a curva AUPRC ilustra a compensação entre precisão e recuperação em diferentes limites.
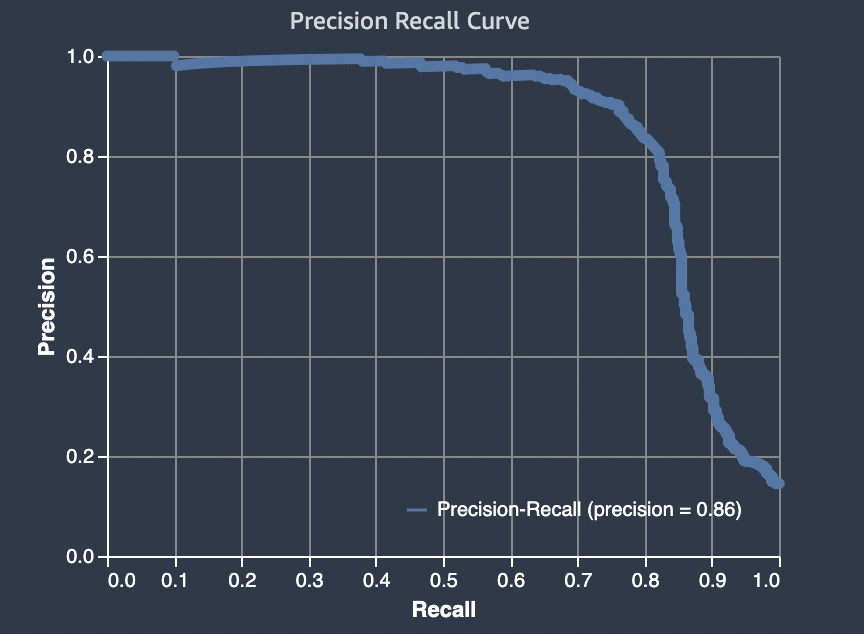
Gráfico real em relação ao previsto
O gráfico real em relação ao previsto mostra a diferença entre os valores reais e previstos do modelo. No gráfico de exemplo a seguir, a linha sólida é uma linha linear de melhor ajuste. Se o modelo fosse 100% preciso, cada ponto previsto seria igual ao ponto real correspondente e estaria nessa linha de melhor ajuste. A distância da linha de melhor ajuste é uma indicação visual do erro do modelo. Quanto maior a distância da linha de melhor ajuste, maior o erro do modelo.
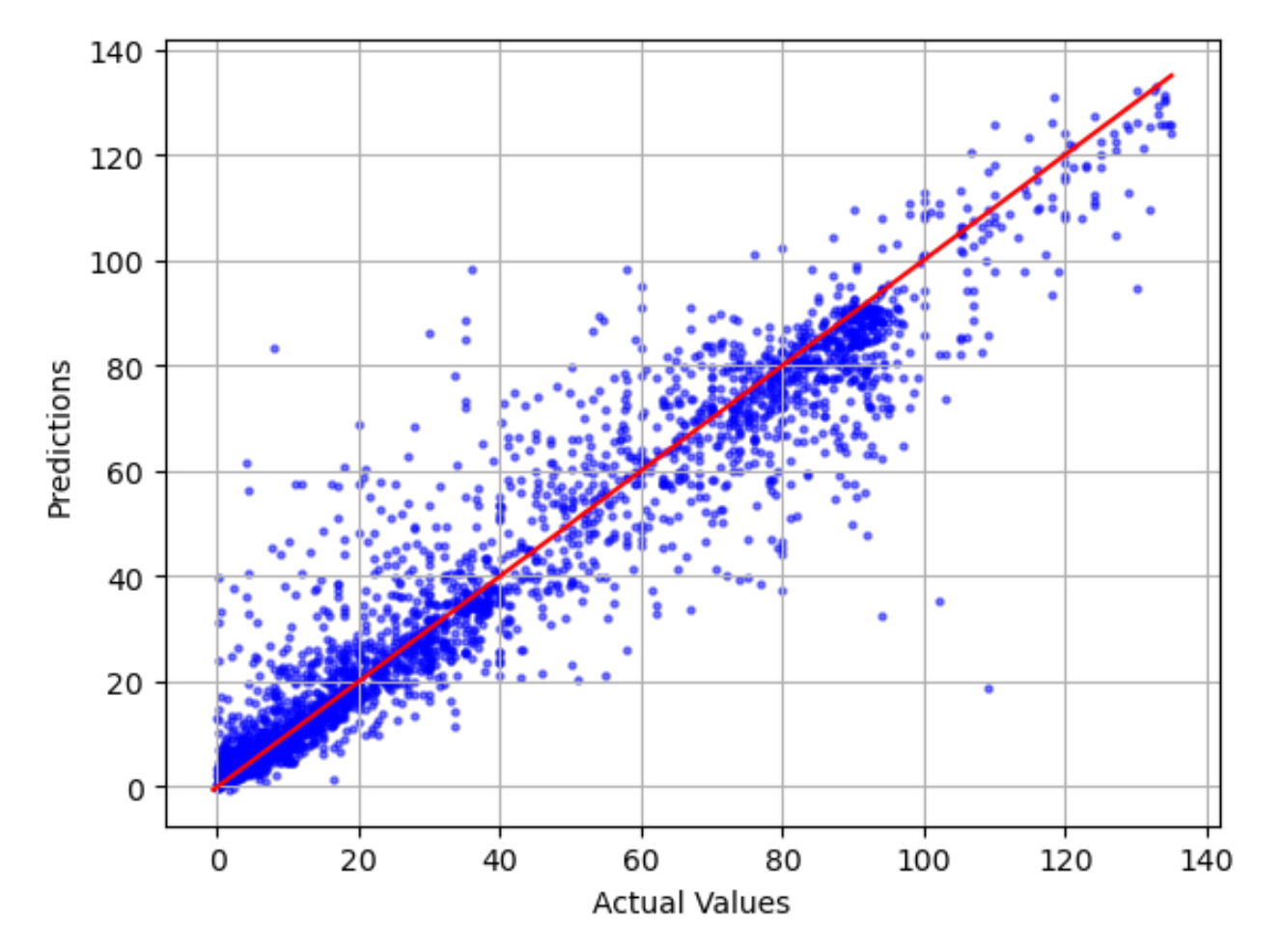
Gráfico residual padronizado
Um gráfico de resíduos padronizado incorpora os seguintes termos estatísticos:
residual-
Um resíduo (bruto) mostra a diferença entre os valores reais e os previstos pelo seu modelo. Quanto maior a diferença, maior o valor residual.
standard deviation-
O desvio padrão é uma medida de como os valores variam de um valor médio. Um desvio padrão alto indica que muitos valores são muito diferentes de seu valor médio. Um desvio padrão baixo indica que muitos valores estão próximos do valor médio.
standardized residual-
Um resíduo padronizado divide os resíduos brutos por seu desvio padrão. Os resíduos padronizados têm unidades de desvio padrão e são úteis para identificar valores discrepantes nos dados, independentemente da diferença na escala dos resíduos brutos. Se um resíduo padronizado for muito menor ou maior do que os outros resíduos padronizados, isso indica que o modelo não está se ajustando bem a essas observações.
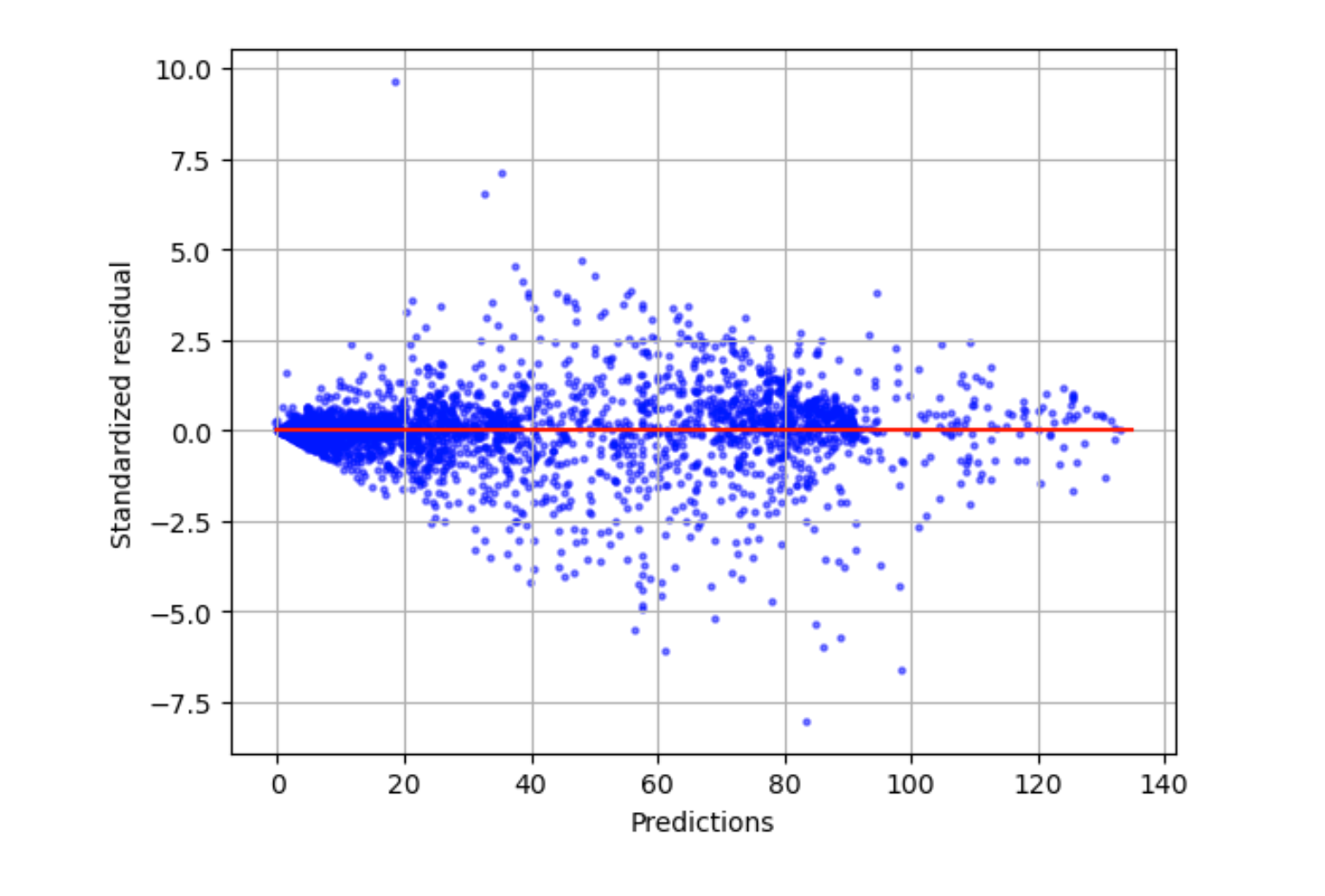
O gráfico de resíduos padronizado mede a força da diferença entre os valores observados e esperados. O valor real previsto é exibido no eixo x. Um ponto com um valor maior que um valor absoluto de 3 é comumente considerado um valor atípico.
O gráfico de exemplo a seguir mostra que um grande número de resíduos padronizados está agrupado em torno de 0 no eixo horizontal. Os valores próximos de zero indicam que o modelo está se ajustando bem a esses pontos. Os pontos na parte superior e inferior do gráfico não são bem previstos pelo modelo.
Histograma residual
Um histograma residual incorpora os seguintes termos estatísticos:
residual-
Um resíduo (bruto) mostra a diferença entre os valores reais e os previstos pelo seu modelo. Quanto maior a diferença, maior o valor residual.
standard deviation-
O desvio padrão é uma medida de quanto os valores variam de um valor médio. Um desvio padrão alto indica que muitos valores são muito diferentes de seu valor médio. Um desvio padrão baixo indica que muitos valores estão próximos do valor médio.
standardized residual-
Um resíduo padronizado divide os resíduos brutos por seu desvio padrão. Resíduos padronizados têm unidades de desvio padrão. Eles são úteis para identificar valores discrepantes nos dados, independentemente da diferença na escala dos resíduos brutos. Se um resíduo padronizado for muito menor ou maior do que os outros resíduos padronizados, isso indicaria que o modelo não está se ajustando bem a essas observações.
histogram-
Um histograma é um gráfico que mostra a frequência com que um valor ocorreu.
O histograma residual mostra a distribuição dos valores residuais padronizados. Um histograma distribuído em forma de sino e centrado em zero indica que o modelo não superestima ou subestima sistematicamente qualquer intervalo específico de valores alvo.
No gráfico a seguir, os valores residuais padronizados indicam que o modelo está se ajustando bem aos dados. Se o gráfico mostrasse valores distantes do valor central, isso indicaria que esses valores não se encaixam bem no modelo.

