As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Exemplos de código: SDK para Python
Esta seção fornece um exemplo de código para criar e invocar um endpoint que usa a explicabilidade on-line do SageMaker Clarify. Esses exemplos de código usam o AWS SDKfor Python
Dados tabulares
O exemplo a seguir usa dados tabulares e um SageMaker modelo chamadomodel_name. Neste exemplo, o contêiner do modelo aceita dados em CSV formato e cada registro tem quatro recursos numéricos. Nessa configuração mínima, somente para fins de demonstração, os dados da SHAP linha de base são definidos como zero. Consulte SHAPLinhas de base para explicabilidade para saber como escolher valores mais apropriados paraShapBaseline.
Configure o endpoint da seguinte maneira:
endpoint_config_name = 'tabular_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '0,0,0,0', }, }, }, }, )
Use a configuração do endpoint para criar um endpoint, como segue:
endpoint_name = 'tabular_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
Use o DescribeEndpoint API para inspecionar o progresso da criação de um endpoint, da seguinte forma:
response = sagemaker_client.describe_endpoint( EndpointName=endpoint_name, ) response['EndpointStatus']
Depois que o status do endpoint for "InService“, invoque o endpoint com um registro de teste, da seguinte forma:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', )
nota
No exemplo de código anterior, para endpoints de vários modelos, passe um parâmetro adicional TargetModel na solicitação para especificar qual modelo deve ser direcionado ao endpoint.
Suponha que a resposta tenha um código de status 200 (sem erro) e carregue o corpo da resposta da seguinte forma:
import codecs import json json.load(codecs.getreader('utf-8')(response['Body']))
A ação padrão para o endpoint é explicar o registro. Veja a seguir um exemplo de saída no JSON objeto retornado.
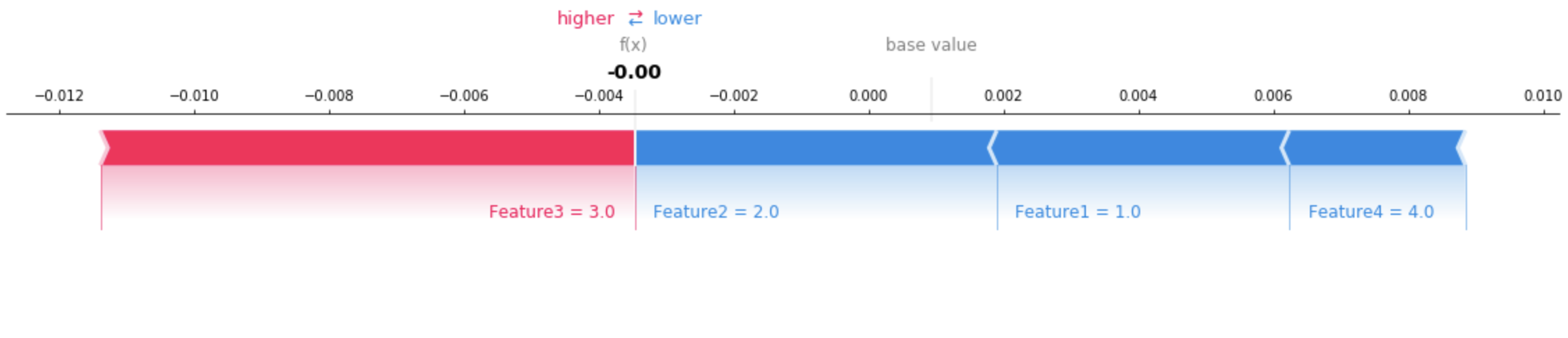
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.0006380207487381" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [-0.00433456] } ] }, { "attributions": [ { "attribution": [-0.005369821] } ] }, { "attributions": [ { "attribution": [0.007917749] } ] }, { "attributions": [ { "attribution": [-0.00261214] } ] } ] ] } }
Use o parâmetro EnableExplanations para habilitar explicações sob demanda, da seguinte forma:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', EnableExplanations='[0]>`0.8`', )
nota
No exemplo de código anterior, para endpoints de vários modelos, passe um parâmetro adicional TargetModel na solicitação para especificar qual modelo deve ser direcionado ao endpoint.
Neste exemplo, o valor de predição é menor que o valor limite de 0.8, portanto, o registro não é explicado:
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.6380207487381995" }, "explanations": {} }
Use ferramentas de visualização para ajudar a interpretar as explicações retornadas. A imagem a seguir mostra como SHAP os gráficos podem ser usados para entender como cada recurso contribui para a previsão. O valor base no diagrama, também chamado de valor esperado, é a média das previsões do conjunto de dados de treinamento. Os recursos que aumentam o valor esperado são vermelhos e os recursos que reduzem o valor esperado são azuis. Consulte o layout da força SHAP aditiva
Veja o exemplo completo de caderno de notas para dados tabulares
Dados de texto
Esta seção fornece um exemplo de código para criar e invocar um endpoint de explicabilidade on-line para dados de texto. O exemplo de código usado SDK para Python.
O exemplo a seguir usa dados de texto e um SageMaker modelo chamadomodel_name. Neste exemplo, o contêiner do modelo aceita dados em CSV formato e cada registro é uma única string.
endpoint_config_name = 'text_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'InferenceConfig': { 'FeatureTypes': ['text'], 'MaxRecordCount': 100, }, 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '"<MASK>"', }, 'TextConfig': { 'Granularity': 'token', 'Language': 'en', }, 'NumberOfSamples': 100, }, }, }, )
-
ShapBaseline: um token especial reservado para processamento de linguagem natural (NLP). -
FeatureTypes: identifica o recurso como texto. Se esse parâmetro não for fornecido, o explicador tentará inferir o tipo de recurso. -
TextConfig: especifica a unidade de granularidade e o idioma para a análise dos recursos de texto. Neste exemplo, o idioma é inglês e granularidadetokensignifica uma palavra em um texto em inglês. -
NumberOfSamples: um limite para definir os limites superiores do tamanho do conjunto de dados sintéticos. -
MaxRecordCount: o número máximo de registros em uma solicitação que o recipiente modelo pode processar. Esse parâmetro está definido para estabilizar o performance.
Use a configuração de endpoint para criar o endpoint, como segue:
endpoint_name = 'text_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
Depois que o status do endpoint se tornar InService, invoque o endpoint. O exemplo de código a seguir usa um registro de teste da seguinte forma:
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='"This is a good product"', )
Se a solicitação for concluída com êxito, o corpo da resposta retornará um JSON objeto válido semelhante ao seguinte:
{ "version": "1.0", "predictions": { "content_type": "text/csv", "data": "0.9766594\n" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [ -0.007270948666666712 ], "description": { "partial_text": "This", "start_idx": 0 } }, { "attribution": [ -0.018199033666666628 ], "description": { "partial_text": "is", "start_idx": 5 } }, { "attribution": [ 0.01970993241666666 ], "description": { "partial_text": "a", "start_idx": 8 } }, { "attribution": [ 0.1253469515833334 ], "description": { "partial_text": "good", "start_idx": 10 } }, { "attribution": [ 0.03291143366666657 ], "description": { "partial_text": "product", "start_idx": 15 } } ], "feature_type": "text" } ] ] } }
Use ferramentas de visualização para ajudar a interpretar as atribuições de texto retornadas. A imagem a seguir mostra como o utilitário de visualização captum pode ser usado para entender como cada palavra contribui para a previsão. Quanto maior a saturação da cor, maior a importância dada à palavra. Neste exemplo, uma cor vermelha brilhante altamente saturada indica uma forte contribuição negativa. Uma cor verde altamente saturada indica uma forte contribuição positiva. A cor branca indica que a palavra tem uma contribuição neutra. Consulte a biblioteca captum

Veja o exemplo completo do caderno de notas para dados de texto
