As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Exportar
No fluxo do Data Wrangler, você pode exportar algumas ou todas as transformações que você fez para seus pipelines de processamento de dados.
Um fluxo do Data Wrangler é a série de etapas de preparação de dados que você executou em seus dados. Na preparação de dados, você realiza uma ou mais transformações em seus dados. Cada transformação é feita usando uma etapa de transformação. O fluxo tem uma série de nós que representam a importação de seus dados e as transformações que você realizou. Para obter um exemplo de nós, consulte as imagens a seguir.
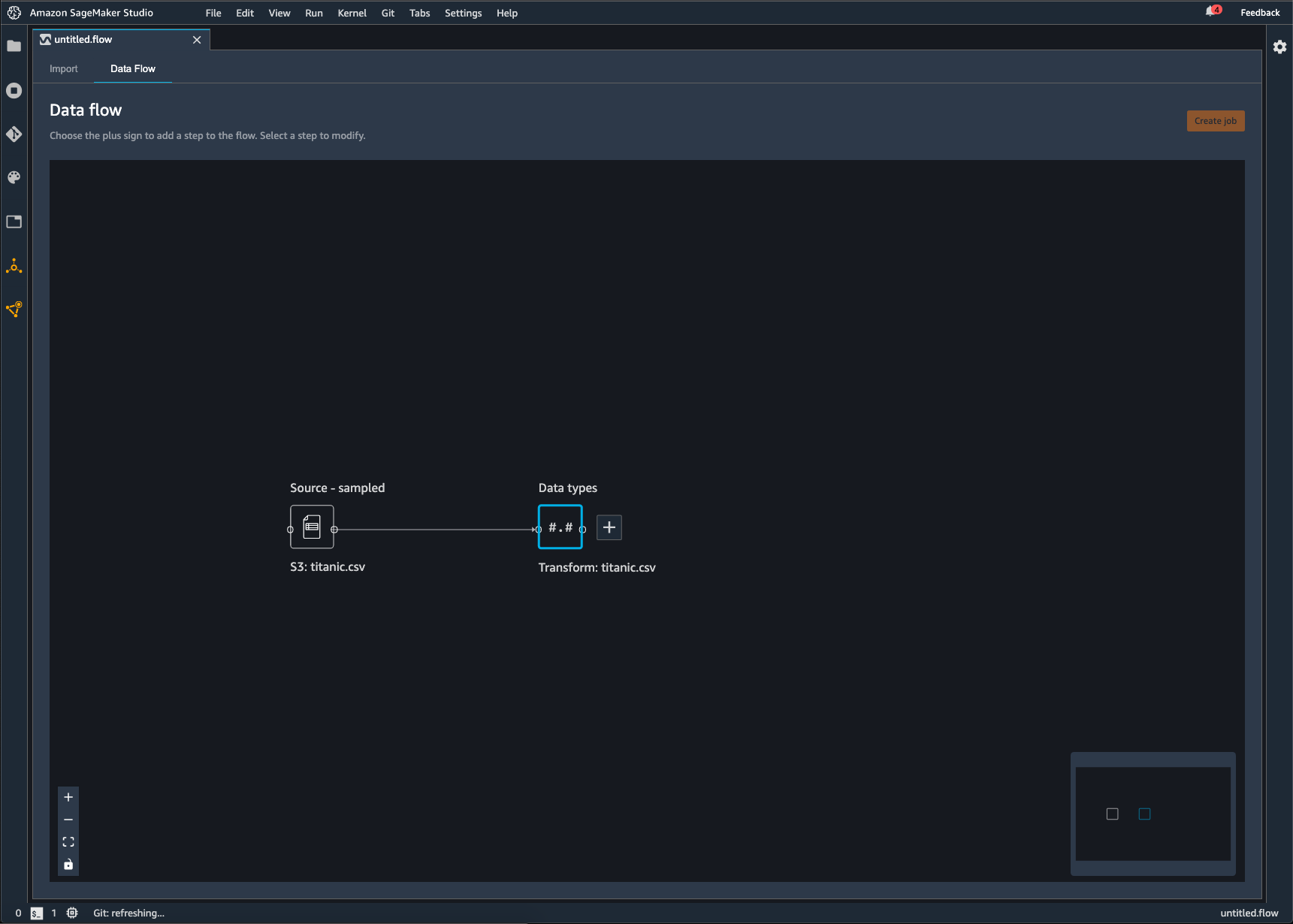
A imagem anterior mostra um fluxo do Data Wrangler com dois nós. O nó Fonte - amostra mostra a fonte de dados da qual você importou seus dados. O nó Tipos de dados indica que o Data Wrangler realizou uma transformação para converter o conjunto de dados em um formato utilizável.
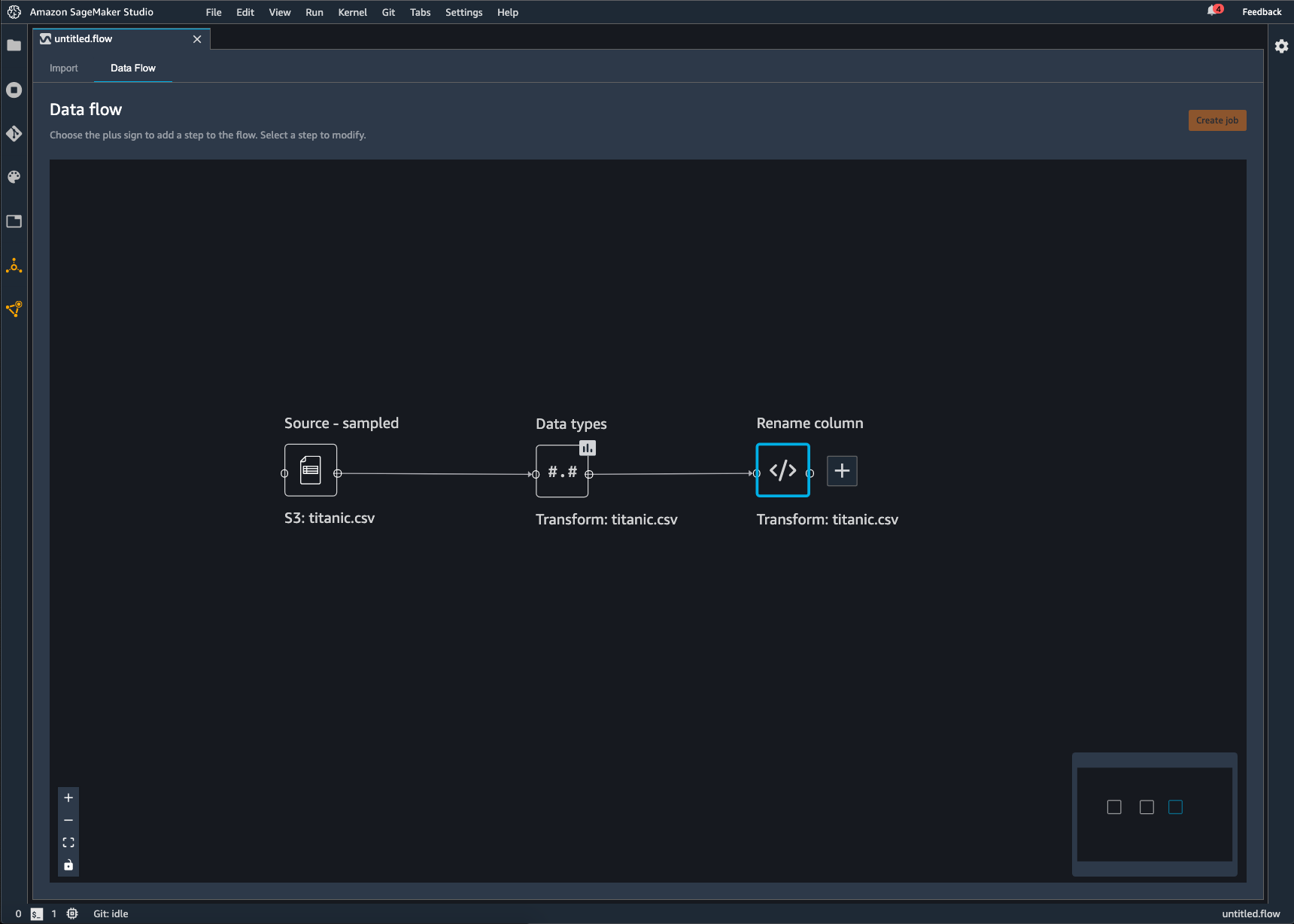
Cada transformação que você adiciona ao fluxo do Data Wrangler aparece como um nó adicional. Para obter mais informações sobre as transformações que você pode adicionar, consulte Transformar dados. A imagem a seguir mostra um fluxo do Data Wrangler que tem um Rename-columnnó para alterar o nome de uma coluna em um conjunto de dados.
Você pode exportar suas transformações de dados para o seguinte:
-
Amazon S3
-
Pipelines
-
Loja de SageMaker recursos da Amazon
-
Código Python
Importante
Recomendamos que você use a política AmazonSageMakerFullAccess gerenciada do IAM para conceder AWS permissão para usar o Data Wrangler. Se você não usar a política gerenciada, poderá usar uma política do IAM que conceda ao Data Wrangler acesso a um bucket do Amazon S3. Para obter mais informações sobre a política, consulte Segurança e permissões.
Ao exportar seu fluxo de dados, você é cobrado pelos AWS recursos que usa. Você pode usar tags de alocação de custos para organizar e gerenciar os custos desses recursos. Você cria essas tags para seu perfil de usuário e o Data Wrangler as aplica automaticamente aos recursos usados para exportar o fluxo de dados. Para obter mais informações, consulte Usar tags de alocação de custos.
Exportar para o Amazon S3.
O Data Wrangler oferece a capacidade de exportar seus dados para um local dentro de um bucket do Amazon S3. Você pode especificar o local usando um dos seguintes métodos:
-
Nó de destino: Onde o Data Wrangler armazena os dados depois de processá-los.
-
Exportar para: Exporta os dados resultantes de uma transformação para o Amazon S3.
-
Exportar dados: Para conjuntos de dados pequenos, pode exportar rapidamente os dados que você transformou.
Use as seções a seguir para saber mais sobre cada um desses métodos.
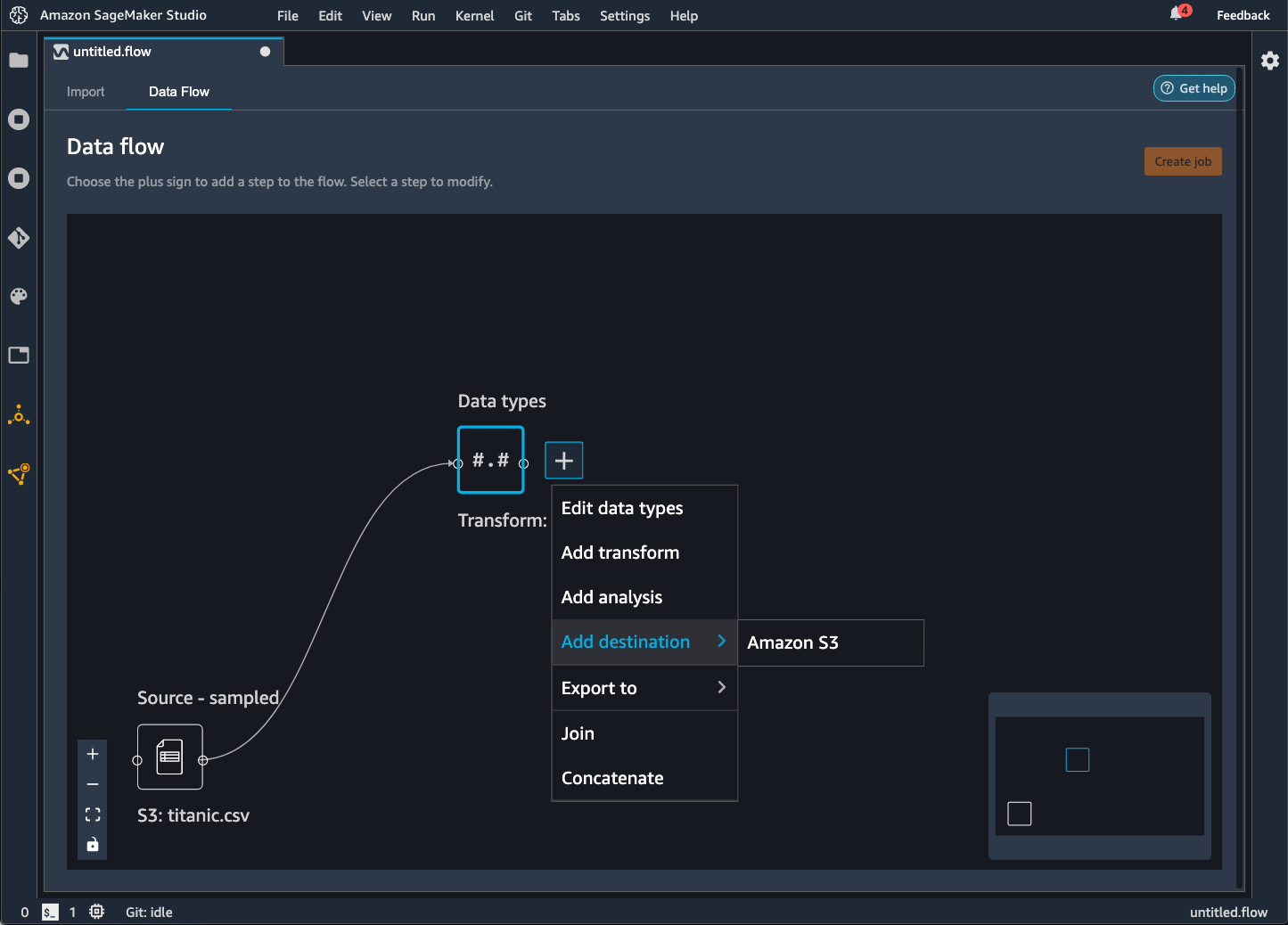
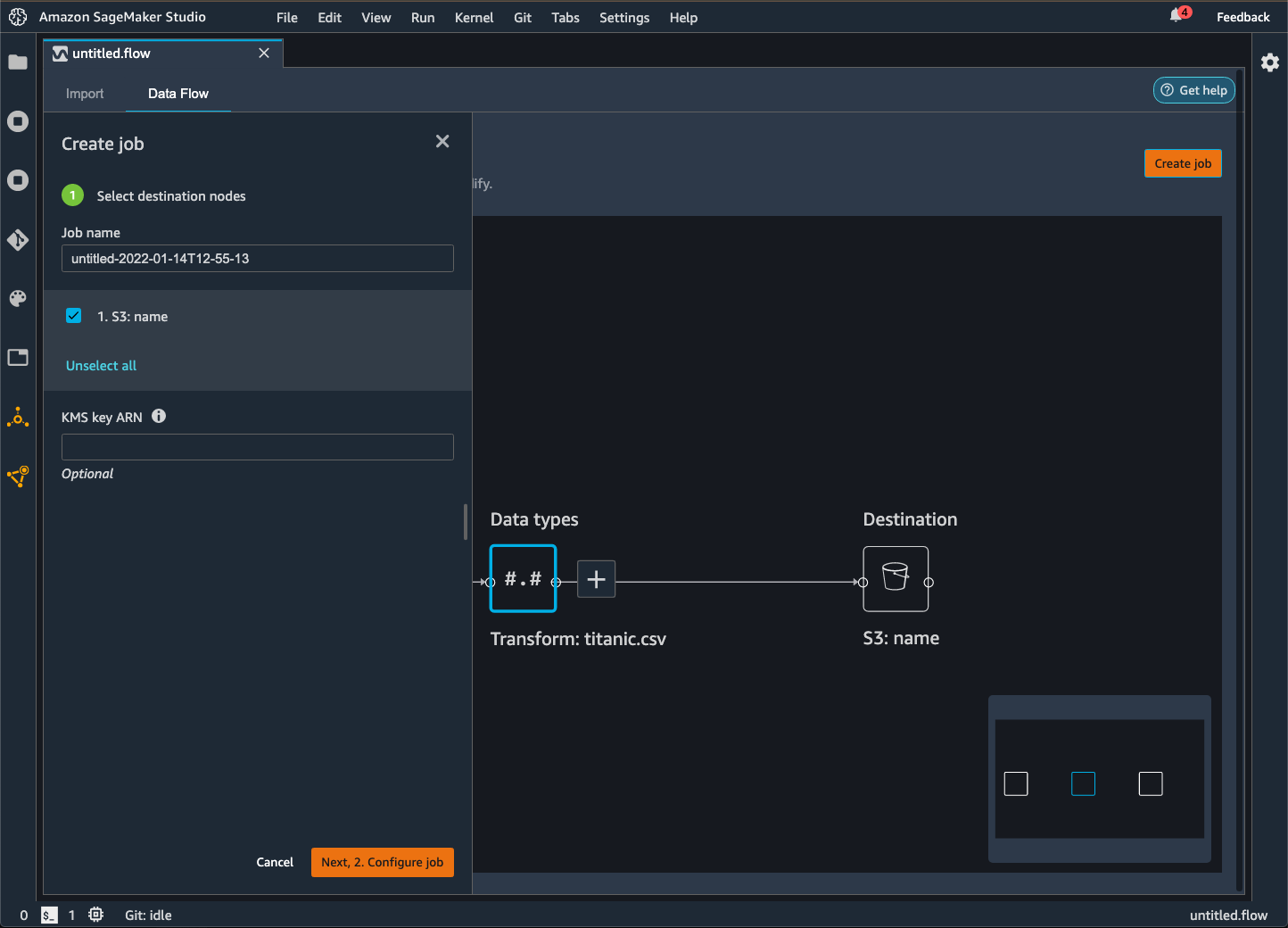
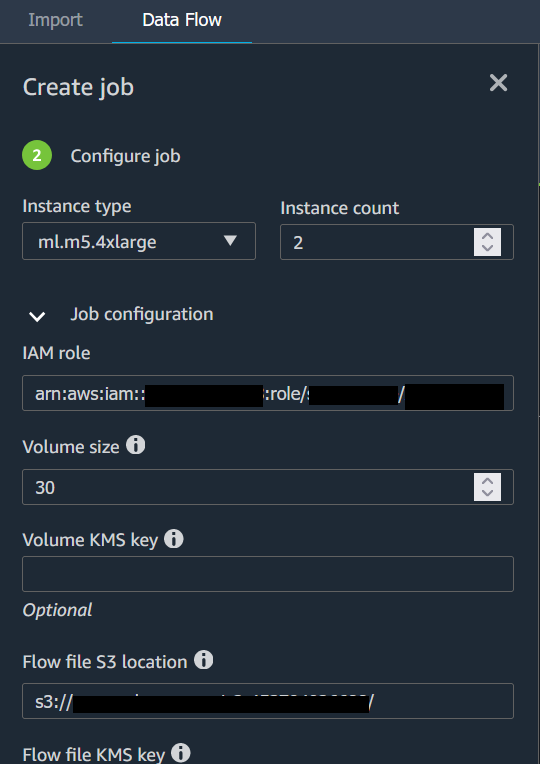
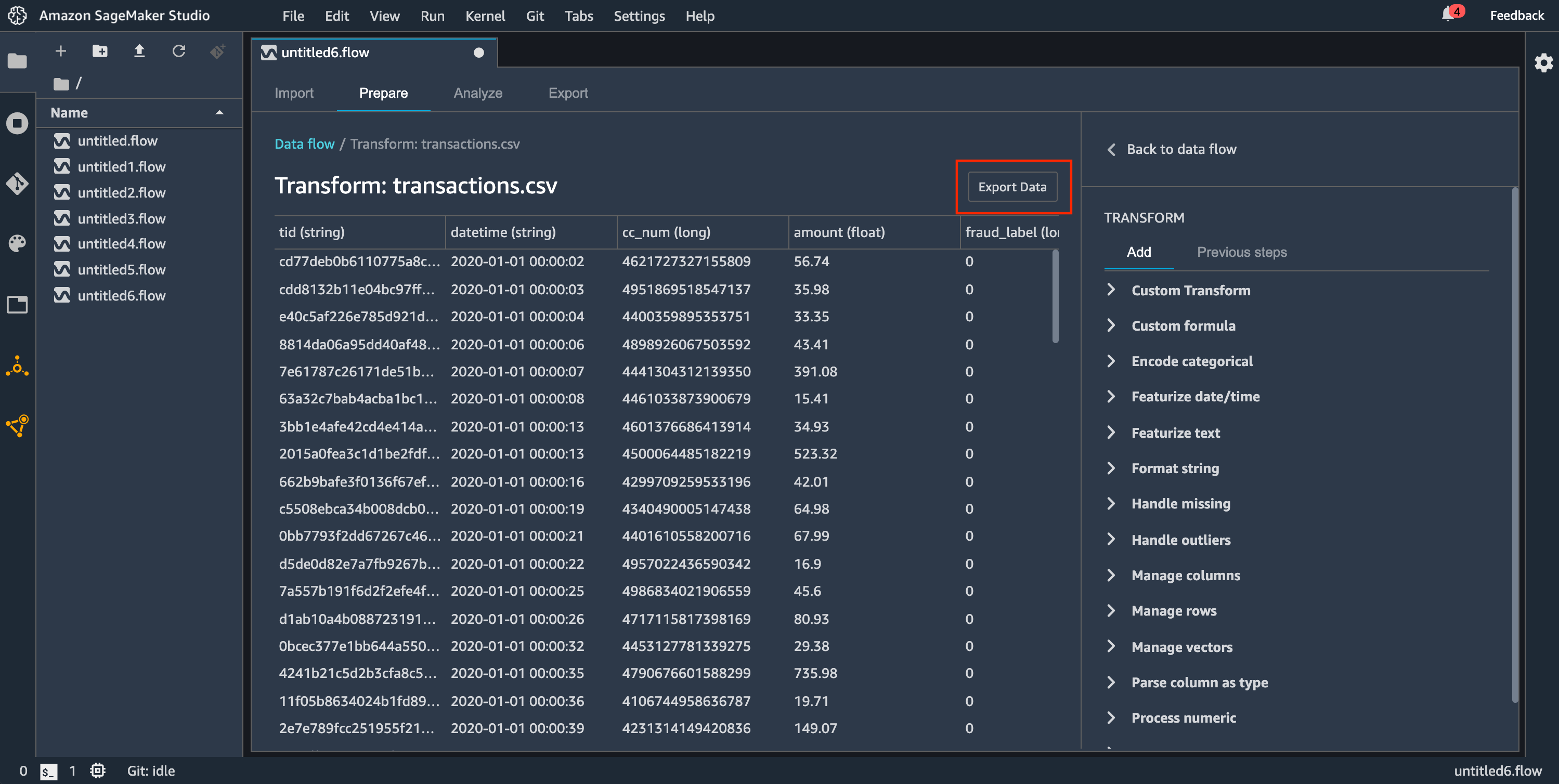
Quando você exporta seu fluxo de dados para um bucket do Amazon S3, o Data Wrangler armazena uma cópia do arquivo de fluxo no bucket do S3. Ele armazena o arquivo de fluxo sob o prefixo data_wrangler_flows. Se você usar o bucket padrão do Amazon S3 para armazenar seus arquivos de fluxo, ele usa a seguinte convenção de nomenclatura: sagemaker-. Por exemplo, se o número da sua conta for 111122223333 e você estiver usando o Studio Classic em us-east-1, seus conjuntos de dados importados serão armazenados em region-account
numbersagemaker-us-east-1-111122223333. Neste exemplo, seus arquivos.flow criados em us-east-1 são armazenados em s3://sagemaker-. region-account
number/data_wrangler_flows/
Exportar para o Pipelines
Quando quiser criar e implantar fluxos de trabalho de aprendizado de máquina (ML) em grande escala, você pode usar o Pipelines para criar fluxos de trabalho que gerenciam e implantam trabalhos de IA. SageMaker Com o Pipelines, você pode criar fluxos de trabalho que gerenciam suas tarefas de preparação de dados de SageMaker IA, treinamento de modelos e implantação de modelos. Você pode usar os algoritmos primários que a SageMaker IA oferece usando Pipelines. Para obter mais informações sobre pipelines, consulte SageMaker Pipelines.
Quando você exporta uma ou mais etapas do seu fluxo de dados para o Pipelines, o Data Wrangler cria um caderno Jupyter que você pode usar para definir, instanciar, executar e gerenciar um pipeline.
Use um caderno Jupyter para criar um pipeline
Use o procedimento a seguir para criar um caderno Jupyter para exportar seu fluxo do Data Wrangler para o Pipelines.
Use o procedimento a seguir para gerar um caderno Jupyter e executá-lo para exportar seu fluxo do Data Wrangler para o Pipelines.
-
Escolha o + próximo ao nó que você deseja separar.
-
Selecione Exportar para.
-
Escolha Pipelines (via caderno Jupyter).
-
Executar o caderno Jupyter.

Você pode usar o caderno Jupyter que o Data Wrangler produz para definir um pipeline. O pipeline inclui as etapas de processamento de dados que são definidas pelo fluxo do Data Wrangler.
Você pode adicionar etapas adicionais ao seu pipeline adicionando etapas à lista steps no código a seguir no caderno:
pipeline = Pipeline( name=pipeline_name, parameters=[instance_type, instance_count], steps=[step_process], #Add more steps to this list to run in your Pipeline )
Para obter mais informações sobre como definir pipelines, consulte Definir o SageMaker AI Pipeline.
Exportar para um endpoint de inferência
Use seu fluxo do Data Wrangler para processar dados no momento da inferência criando um pipeline de inferência serial de SageMaker IA a partir do seu fluxo do Data Wrangler. Um pipeline de inferência é uma série de etapas que resulta em um modelo treinado fazendo predições sobre novos dados. Um pipeline de inferência serial no Data Wrangler transforma os dados brutos e os fornece ao modelo de machine learning para uma predição. Você cria, executa e gerencia o pipeline de inferência por meio de um caderno Jupyter no Studio Classic. Para obter mais informações sobre o acesso ao caderno, consulte Use um caderno Jupyter para criar um endpoint de inferência.
No caderno, você pode treinar um modelo de machine learning ou especificar um que já tenha treinado. Você pode usar o Amazon SageMaker Autopilot ou o XGBoost para treinar o modelo usando os dados que você transformou em seu fluxo do Data Wrangler.
O pipeline fornece a capacidade de realizar inferências em lote ou em tempo real. Você também pode adicionar o fluxo do Data Wrangler ao SageMaker Model Registry. Para obter mais informações sobre modelos de host, consulte Multi-model endpoints.
Importante
Você não pode exportar seu fluxo do Data Wrangler para um endpoint de inferência se ele tiver as seguintes transformações:
-
Ingressar
-
concatenar
-
Agrupar por
Se você precisar usar as transformações anteriores para preparar seus dados, use o procedimento a seguir.
Para preparar seus dados para inferência com transformações sem compatibilidade
-
Crie um fluxo do Data Wrangler.
-
Aplique as transformações anteriores que não são compatíveis.
-
Exportar os dados para um bucket do Amazon S3.
-
Crie um fluxo de Data Wrangler separado.
-
Importe os dados que você exportou do fluxo anterior.
-
Aplique as transformações restantes.
-
Crie um pipeline de inferência serial usando o caderno Jupyter que fornecemos.
Para obter informações sobre como exportar dados para um bucket do Amazon S3, consulte Exportar para o Amazon S3.. Para obter informações sobre como abrir o caderno Jupyter usado para criar o pipeline de inferência serial, consulte Use um caderno Jupyter para criar um endpoint de inferência.
O Data Wrangler ignora as transformações que removem dados no momento da inferência. Por exemplo, o Data Wrangler ignora a transformação Processamento de valores ausentes se você usar a configuração Drop missing.
Se você reajustou as transformações em todo o seu conjunto de dados, as transformações são transferidas para seu pipeline de inferência. Por exemplo, se você usou o valor mediano para imputar valores ausentes, o valor médio do reajuste da transformação será aplicado às suas solicitações de inferência. Você pode reajustar as transformações do seu fluxo do Data Wrangler ao usar o caderno Jupyter ou ao exportar seus dados para um pipeline de inferência. Para informações sobre reajustar transformações, consulte Reajuste as transformações em todo o conjunto de dados e exporte-as.
O pipeline de inferência serial é compatível com os seguintes tipos de dados para as cadeias de caracteres de entrada e saída: Cada tipo de dados tem um conjunto de requisitos.
Tipos de dados compatíveis
-
text/csv: o tipo de dados para cadeias de caracteres CSV-
A string não pode ter um cabeçalho.
-
Os atributos usados para o pipeline de inferência devem estar na mesma ordem dos atributos no conjunto de dados de treinamento.
-
Deve haver um delimitador de vírgula entre os atributos.
-
Os registros devem ser delimitados por um caractere de nova linha.
Veja a seguir um exemplo de uma string CSV com formatação válida que você pode fornecer em uma solicitação de inferência.
abc,0.0,"Doe, John",12345\ndef,1.1,"Doe, Jane",67890 -
-
application/json: o tipo de dados para strings JSON-
Os atributos usados no conjunto de dados para o pipeline de inferência devem estar na mesma ordem dos atributos no conjunto de dados de treinamento.
-
Os dados devem ter um esquema específico. Você define o esquema como um único objeto
instancesque tem um conjunto defeatures. Cada objetofeaturesrepresenta uma observação.
Veja a seguir um exemplo de uma string JSON formatada validamente que você pode fornecer em uma solicitação de inferência.
{ "instances": [ { "features": ["abc", 0.0, "Doe, John", 12345] }, { "features": ["def", 1.1, "Doe, Jane", 67890] } ] } -
Use um caderno Jupyter para criar um endpoint de inferência
Use o procedimento a seguir para exportar seu fluxo do Data Wrangler para criar um pipeline de inferência.
Para criar um pipeline de inferência usando um caderno Jupyter, faça o seguinte:
-
Escolha o + próximo ao nó que você deseja separar.
-
Selecione Exportar para.
-
Escolha o SageMaker AI Inference Pipeline (via Jupyter Notebook).
-
Executar o caderno Jupyter.
Quando você executa o caderno Jupyter, ele cria um artefato de fluxo de inferência. Um artefato de fluxo de inferência é um arquivo de fluxo do Data Wrangler com metadados adicionais usados para criar o pipeline de inferência serial. O nó que você está exportando abrange todas as transformações dos nós anteriores.
Importante
O Data Wrangler precisa do artefato do fluxo de inferência para executar o pipeline de inferência. Você não pode usar seu próprio arquivo de fluxo como artefato. Você deve criá-lo usando o procedimento anterior.
Exportar para código Python
Para exportar todas as etapas do fluxo de dados para um arquivo Python que você possa integrar manualmente a qualquer fluxo de trabalho de processamento de dados, use o procedimento a seguir.
Use o procedimento a seguir para gerar um caderno Jupyter e executá-lo para exportar seu fluxo do Data Wrangler para o código Python.
-
Escolha o + próximo ao nó que você deseja separar.
-
Selecione Exportar para.
-
Escolha Python Code.
-
Executar o caderno Jupyter.
Pode ser necessário configurar o script Python para que seja executado no seu pipeline. Por exemplo, se você estiver executando um ambiente Spark, certifique-se de executar o script em um ambiente que tenha permissão para acessar AWS recursos.
Exportar para a Amazon SageMaker Feature Store
Você pode usar o Data Wrangler para exportar recursos que você criou para a Amazon SageMaker Feature Store. Um atributo é uma coluna no seu conjunto de dados. O Feature Store é uma loja centralizada para atributos e seus metadados associados. Você pode usar o Feature Store para criar, compartilhar e gerenciar dados selecionados para o desenvolvimento de machine learning (ML). Armazenamentos centralizados tornam seus dados mais detectáveis e reutilizáveis. Para obter mais informações sobre a Feature Store, consulte Amazon SageMaker Feature Store.
Um conceito central no Feature Store é um grupo de atributos. Um grupo de atributos é uma coleção de atributos, seus registros (observações) e metadados associados. É semelhante a uma tabela em um banco de dados.
Você pode usar o Data Wrangler para realizar uma destas ações:
-
Atualize um grupo de atributos existente com novos registros. Um registro é uma observação no conjunto de dados.
-
Crie um novo grupo de atributos a partir de um nó em seu fluxo do Data Wrangler. O Data Wrangler adiciona as observações de seus conjuntos de dados como registros em seu grupo de atributos.
Se você estiver atualizando um grupo de atributos existente, o esquema do seu conjunto de dados deverá corresponder ao esquema do grupo de atributos. Todos os registros no grupo de atributos são substituídos pelas observações em seu conjunto de dados.
Você pode usar um caderno Jupyter ou um nó de destino para atualizar seu grupo de atributos com as observações no conjunto de dados.
Se seus grupos de recursos com o formato de tabela Iceberg tiverem uma chave de criptografia de loja off-line personalizada, certifique-se de conceder ao IAM que você está usando para o trabalho do Amazon SageMaker Processing permissões para usá-lo. No mínimo, você deve conceder permissões para criptografar os dados que você está gravando no Amazon S3. Para conceder as permissões, dê à função do IAM a capacidade de usar GenerateDataKeyo. Para obter mais informações sobre como conceder permissões aos papéis do IAM para usar AWS KMS chaves, consulte https://docs.aws.amazon.com/kms/latest/developerguide/key-policies.html
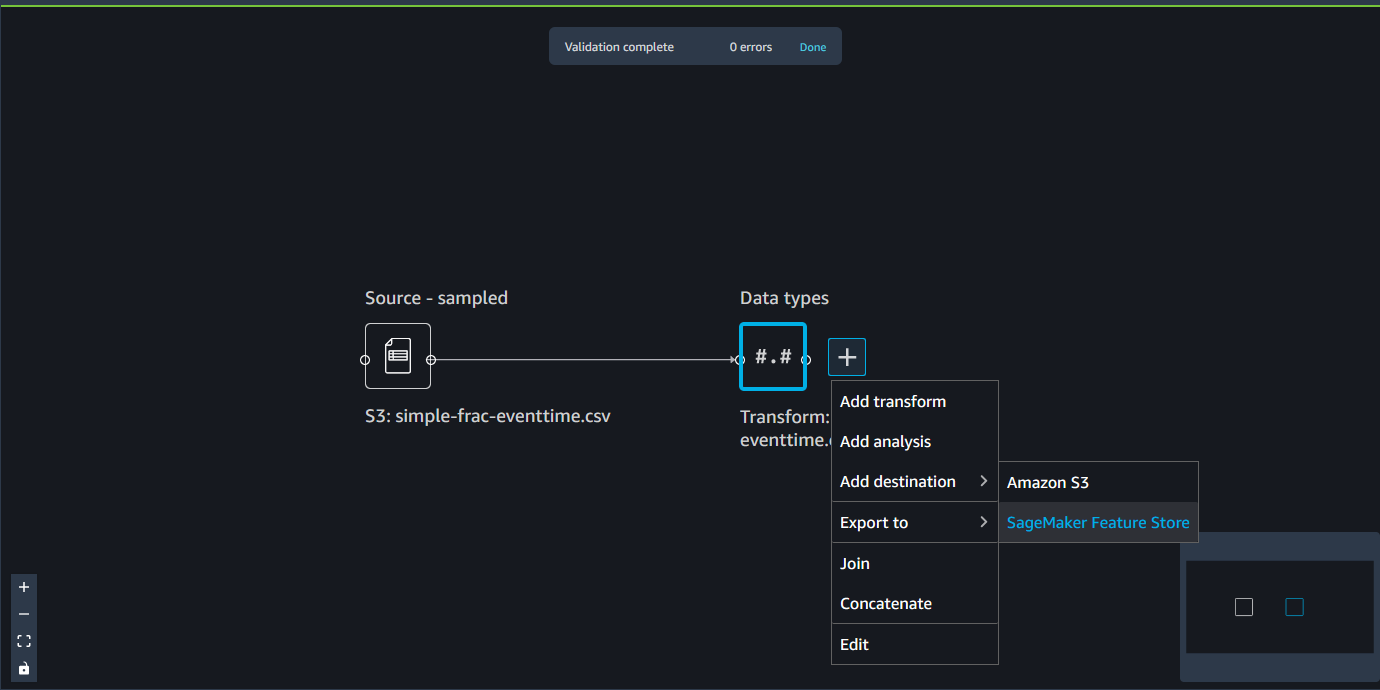
O caderno usa essas configurações para criar um grupo de atributos, processar seus dados em grande escala e, em seguida, ingerir os dados processados em seus repositórios de atributos online e offline. Para saber mais, consulte Fontes de dados e ingestão.
Reajuste as transformações em todo o conjunto de dados e exporte-as
Quando você importa dados, o Data Wrangler usa uma amostra dos dados para aplicar as codificações. Por padrão, o Data Wrangler usa as primeiras 50.000 linhas como amostra, mas você pode importar todo o conjunto de dados ou usar um método de amostragem diferente. Para obter mais informações, consulte Importar.
As transformações a seguir usam seus dados para criar uma coluna no conjunto de dados:
Se você usou a amostragem para importar seus dados, as transformações anteriores usarão somente os dados da amostra para criar a coluna. A transformação pode não ter usado todos os dados relevantes. Por exemplo, se você usar a transformação Codificar Categórica, pode ter havido uma categoria em todo o conjunto de dados que não estava presente na amostra.
Você pode usar um nó de destino ou um caderno Jupyter para reajustar as transformações em todo o conjunto de dados. Quando o Data Wrangler exporta as transformações no fluxo, ele cria uma SageMaker tarefa de processamento. Quando o trabalho de processamento é concluído, o Data Wrangler salva os seguintes arquivos no local padrão do Amazon S3 ou em um local do S3 que você especificar:
-
O arquivo de fluxo do Data Wrangler que especifica as transformações que são reajustadas ao conjunto de dados
-
O conjunto de dados com as transformações de reajuste aplicadas a ele
Você pode abrir um arquivo de fluxo do Data Wrangler no Data Wrangler e aplicar as transformações em um conjunto de dados diferente. Por exemplo, se você aplicou as transformações a um conjunto de dados de treinamento, pode abrir e usar o arquivo de fluxo do Data Wrangler para aplicar as transformações a um conjunto de dados usado para inferência.
Para obter informações sobre o uso de nós de destino para reajustar transformações e exportar, consulte as seguintes páginas:
Use o procedimento a seguir para executar um caderno Jupyter para reajustar as transformações e exportar os dados.
Para executar um caderno Jupyter, reajustar as transformações e exportar seu fluxo do Data Wrangler, faça o seguinte:
-
Escolha o + próximo ao nó que você deseja separar.
-
Selecione Exportar para.
-
Escolha o local para o qual você está exportando os dados.
-
Para o objeto
refit_trained_params, definarefitcomoTrue. -
Para o campo
output_flow, especifique o nome do arquivo de fluxo de saída com as transformações de reajuste. -
Executar o caderno Jupyter.
Crie um cronograma para processar automaticamente novos dados
Se você estiver processando dados periodicamente, poderá criar um cronograma para executar o trabalho de processamento automaticamente. Por exemplo, você pode criar uma programação que execute um trabalho de processamento automaticamente quando você obtiver novos dados. Para obter mais informações sobre esses processos, consulte Exportar para o Amazon S3. e Exportar para a Amazon SageMaker Feature Store.
Ao criar um trabalho, você deve especificar um perfil do IAM que tenha permissões para criar o trabalho. Por padrão, o perfil do IAM que você usa para acessar o Data Wrangler é o SageMakerExecutionRole.
As permissões a seguir permitem que o Data Wrangler acesse EventBridge e execute trabalhos EventBridge de processamento:
-
Adicione a seguinte política AWS gerenciada à função de execução do Amazon SageMaker Studio Classic, que fornece ao Data Wrangler permissões de uso: EventBridge
arn:aws:iam::aws:policy/AmazonEventBridgeFullAccessPara obter mais informações sobre a política, consulte políticas AWS gerenciadas para EventBridge.
-
Adicione a seguinte política à perfil do IAM que você especificou ao criar um trabalho no Data Wrangler:
Se você estiver usando a função padrão do IAM, você adiciona a política anterior à função de execução do Amazon SageMaker Studio Classic.
Adicione a seguinte política de confiança à função para permitir que você EventBridge a assuma.
{ "Effect": "Allow", "Principal": { "Service": "events.amazonaws.com" }, "Action": "sts:AssumeRole" }
Importante
Quando você cria uma agenda, o Data Wrangler cria uma eventRule entrada. EventBridge Você incorre em cobranças pelas regras de eventos que você cria e pelas instâncias usadas para executar o trabalho de processamento.
Para obter informações sobre EventBridge preços, consulte EventBridge Preços da Amazon
É possível criar uma programação usando um dos seguintes métodos:
-
nota
O Data Wrangler não é compatível com as seguintes expressões:
-
LW#
-
Abreviações para dias
-
Abreviações para meses
-
-
Recorrente: defina um intervalo de hora em hora ou diário para executar o trabalho.
-
Horário específico: defina dias e horários específicos para executar o trabalho.
As seções a seguir fornecem procedimentos para criar empregos.
Você pode usar o Amazon SageMaker Studio Classic para ver os trabalhos que estão programados para execução. Seus trabalhos de processamento são executados dentro do Pipelines. Cada trabalho de processamento tem seu próprio pipeline. Ele é executado como uma etapa de processamento dentro do pipeline. Você pode ver as agendas que você criou em um funil. Para obter informações sobre como visualizar um pipeline, consulte Visualizar os detalhes de um pipeline.
Use o procedimento a seguir para visualizar os trabalhos que você programou.
Para obter os trabalhos que você programou, faça o seguinte:
-
Abra o Amazon SageMaker Studio Classic.
-
Abra o Pipelines
-
Veja os pipelines dos trabalhos que você criou.
O pipeline que executa o trabalho usa o nome do trabalho como prefixo. Por exemplo, se você criou um trabalho chamado
housing-data-feature-enginnering, o nome do pipeline édata-wrangler-housing-data-feature-engineering. -
Escolha o pipeline que contém seu trabalho.
-
Visualize o status dos pipelines. Pipelines com status de Bem-sucedido executaram o trabalho de processamento com êxito.
Para interromper a execução do trabalho de processamento, faça o seguinte:
Para interromper a execução de um trabalho de processamento, exclua a regra de evento que especifica a programação. A exclusão de uma regra de evento interrompe a execução de todos os trabalhos associados à programação. Para obter informações sobre como excluir uma regra, consulte Como desativar ou excluir uma regra da Amazon. EventBridge
Você também pode interromper e excluir os pipelines associados aos agendamentos. Para obter informações sobre como interromper um pipeline, consulte StopPipelineExecution. Para obter informações sobre como excluir um pipeline, consulte DeletePipeline.
