As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Passo a passo do relatório de criação de perfil do Debugger
Esta seção o orienta no relatório de criação de perfil do Depurador, seção por seção. O relatório de criação de perfil é gerado baseado nas regras integradas para monitoramento e criação de perfil. O relatório mostra gráficos de resultados somente para as regras que encontraram problemas.
Importante
No relatório, os gráficos e as recomendações são fornecidos para fins informativos e não são definitivos. Você é responsável por fazer sua própria avaliação independente das informações.
Tópicos
Resumo do trabalho de treinamento
No início do relatório, o Debugger fornece um resumo do seu trabalho de treinamento. Nesta seção, você pode ter uma visão geral das durações e dos registros de data e hora em diferentes fases do treinamento.
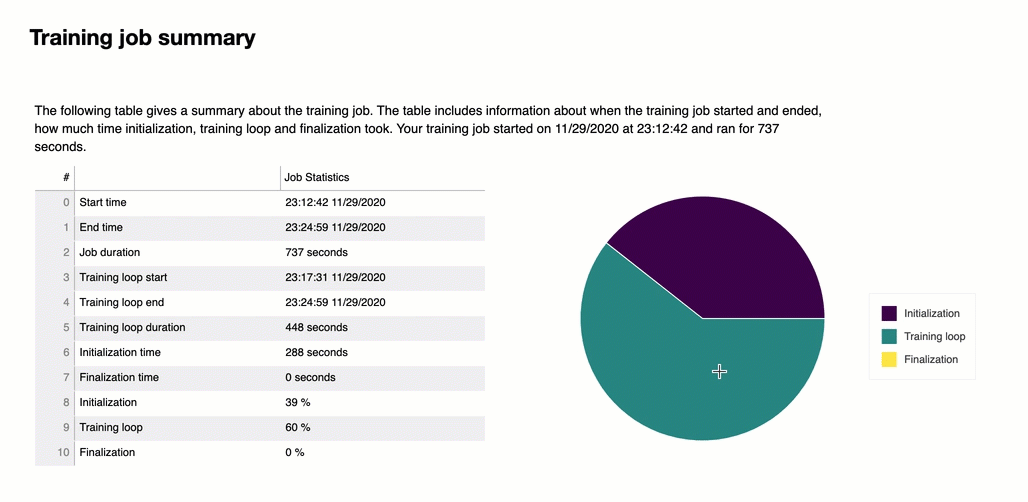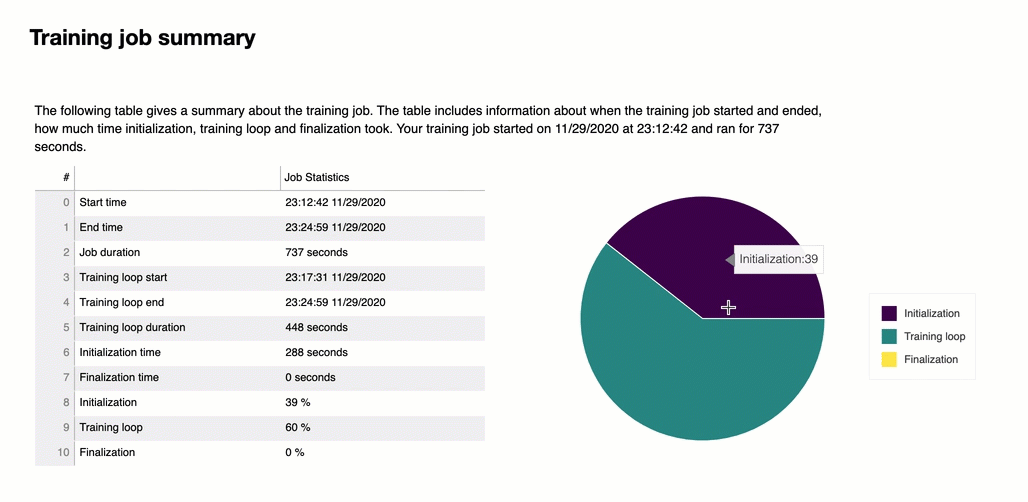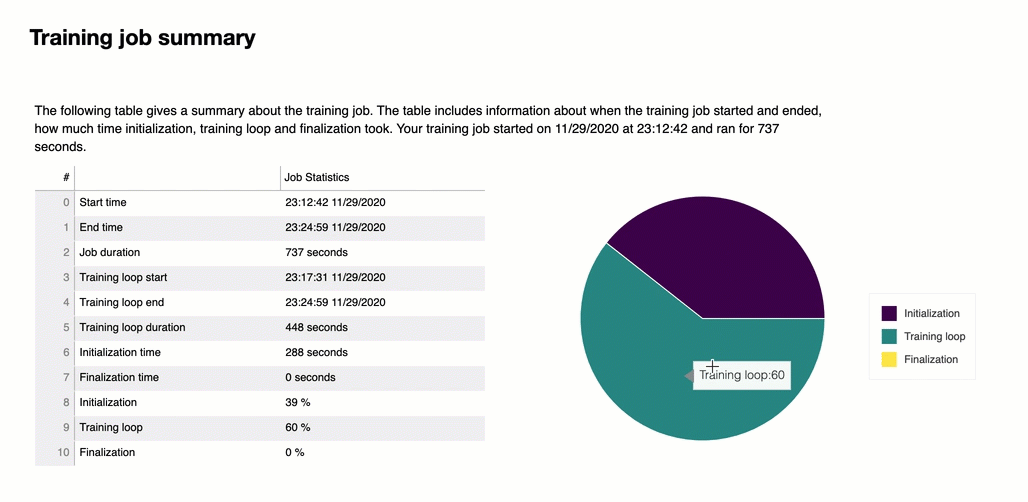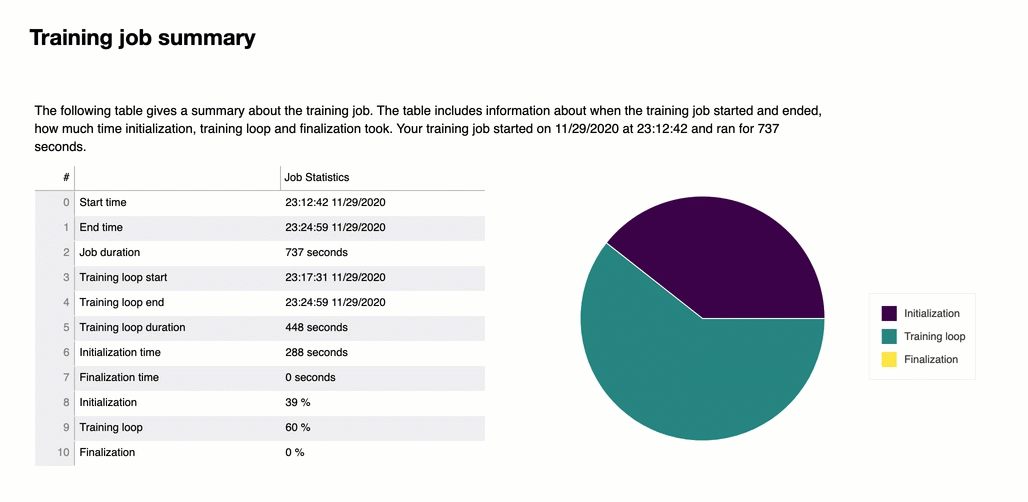
A tabela do resumo contém as seguintes informações:
-
start_time: A hora exata em que o trabalho de treinamento começou.
-
end_time: A hora exata em que o trabalho de treinamento foi concluído.
-
job_duration_in_seconds: O tempo total de treinamento do horário_inicial até o horário_final.
-
training_loop_start: A hora exata em que a primeira etapa da primeira época começou.
-
training_loop_start: A hora exata em que a primeira etapa da primeira época começou.
-
training_loop_duration_in_seconds: O tempo total entre a hora de início do ciclo de treinamento e a hora de término do ciclo de treinamento.
-
initialization_in_seconds: Tempo gasto na inicialização do trabalho de treinamento. A fase de inicialização abrange o período entre o start_time e o training_loop_start time. O tempo de inicialização é gasto na compilação do script de treinamento, na inicialização do script de treinamento, na criação e na inicialização do modelo, na inicialização de EC2 instâncias e no download dos dados de treinamento.
-
finalization_in_seconds — Tempo gasto na finalização do trabalho de treinamento, como finalizar o treinamento do modelo, atualizar os artefatos do modelo e fechar as instâncias. EC2 A fase de finalização abrange o período desde o momento training_loop_end ao end_time.
-
inicialização (%): A porcentagem de tempo gasto na inicialização sobre o total de job_duration_in_seconds.
-
ciclo de treinamento (%): A porcentagem de tempo gasto no ciclo de treinamento sobre o total de job_duration_in_seconds.
-
finalização (%): A porcentagem de tempo gasto na finalização sobre o total de job_duration_in_seconds.
Estatísticas de uso do sistema
Nesta seção, você pode ver uma visão geral das estatísticas de utilização do sistema.
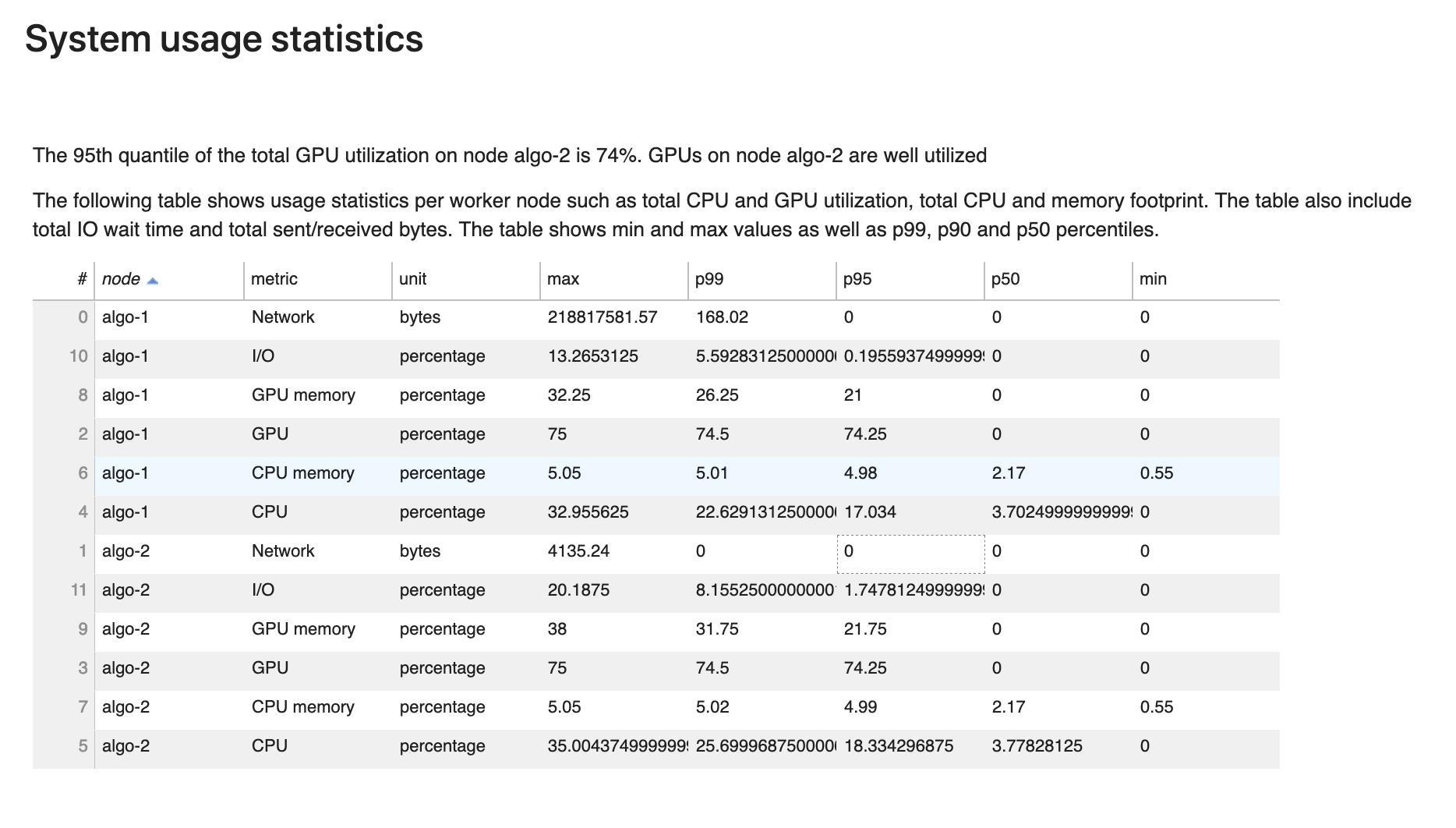
O relatório de criação de perfil inclui as seguintes informações:
-
nó: Lista o nome dos nós. Se estiver usando treinamento distribuído em vários nós (várias EC2 instâncias), os nomes dos nós estão no formato de
algo-n. -
métrica: As métricas do sistema coletadas pelo Debugger: CPU, GPU, memória da CPU, memória da GPU, E/S e métricas de rede.
-
unidade: A unidade das métricas do sistema.
-
max: O valor máximo de cada métrica do sistema.
-
p99: O 99º percentil de cada utilização do sistema.
-
p95: O 95º percentil de cada utilização do sistema.
-
p50: O 50º percentil (médio) de cada utilização do sistema.
-
min: O valor mínimo de cada métrica do sistema.
Resumo das métricas do framework
Nesta seção, os gráficos circulares a seguir mostram o detalhamento das operações da estrutura em CPUs GPUs e.
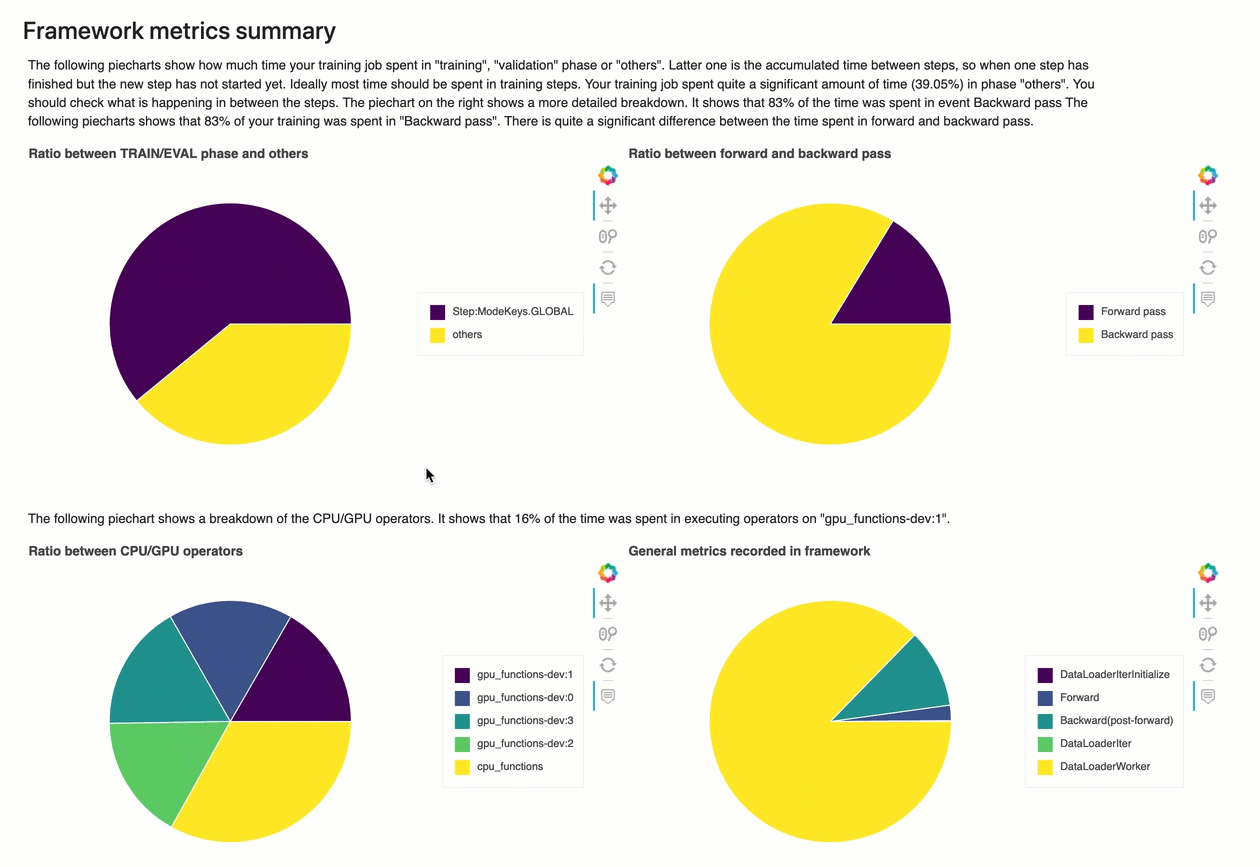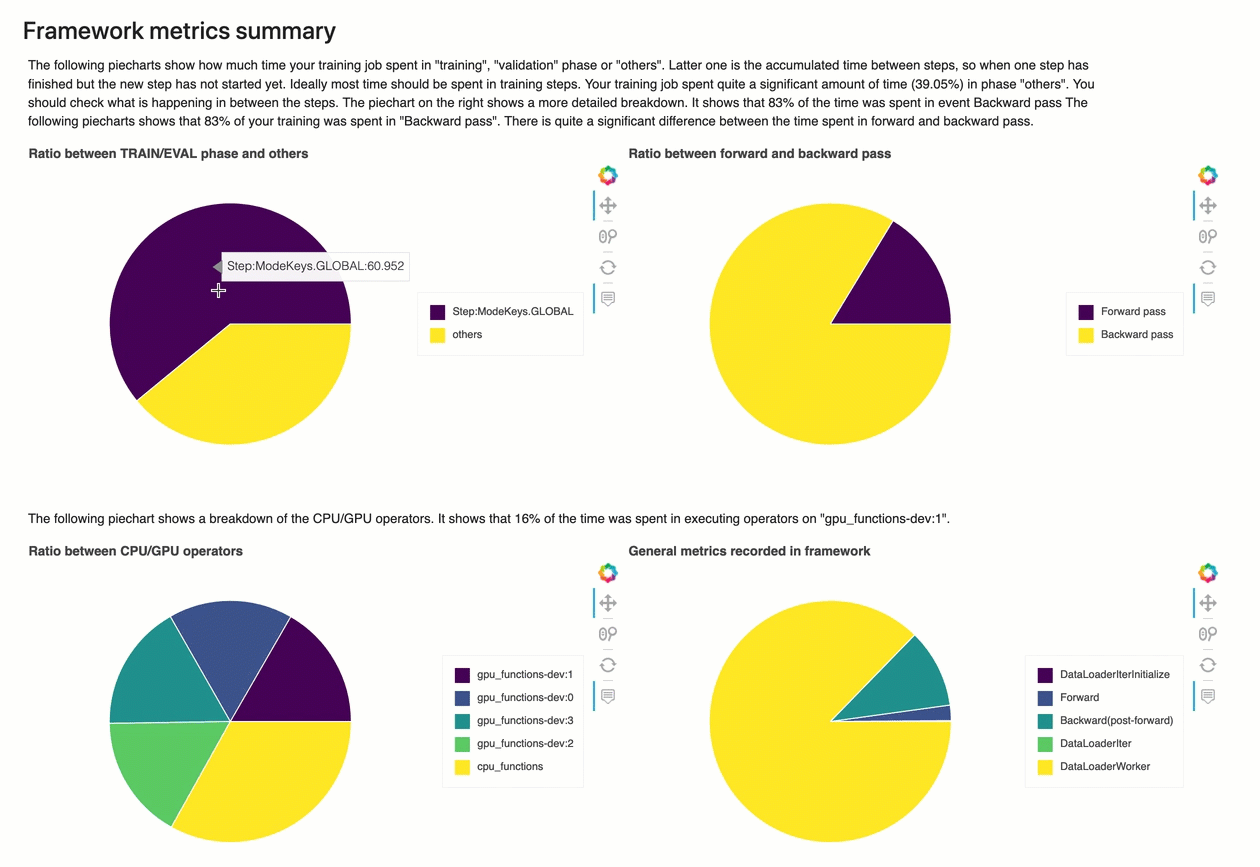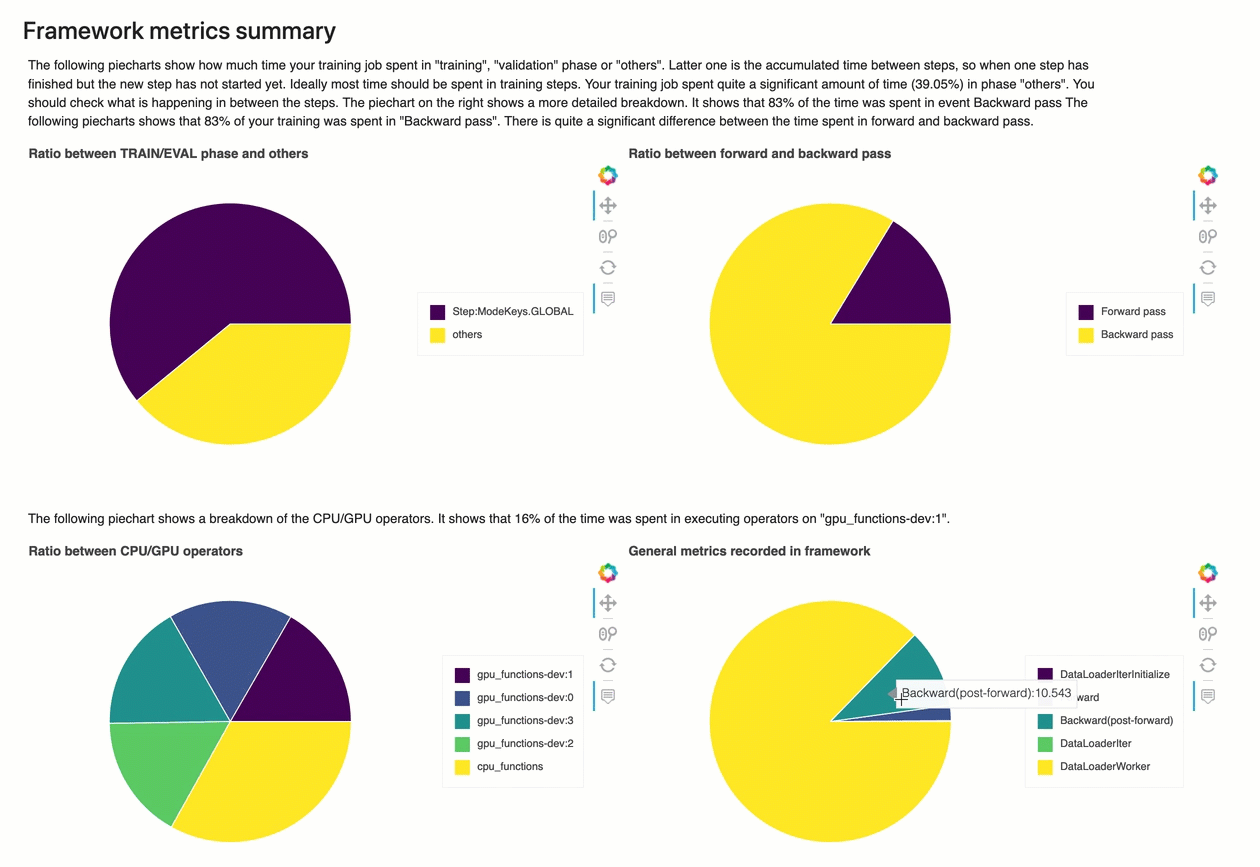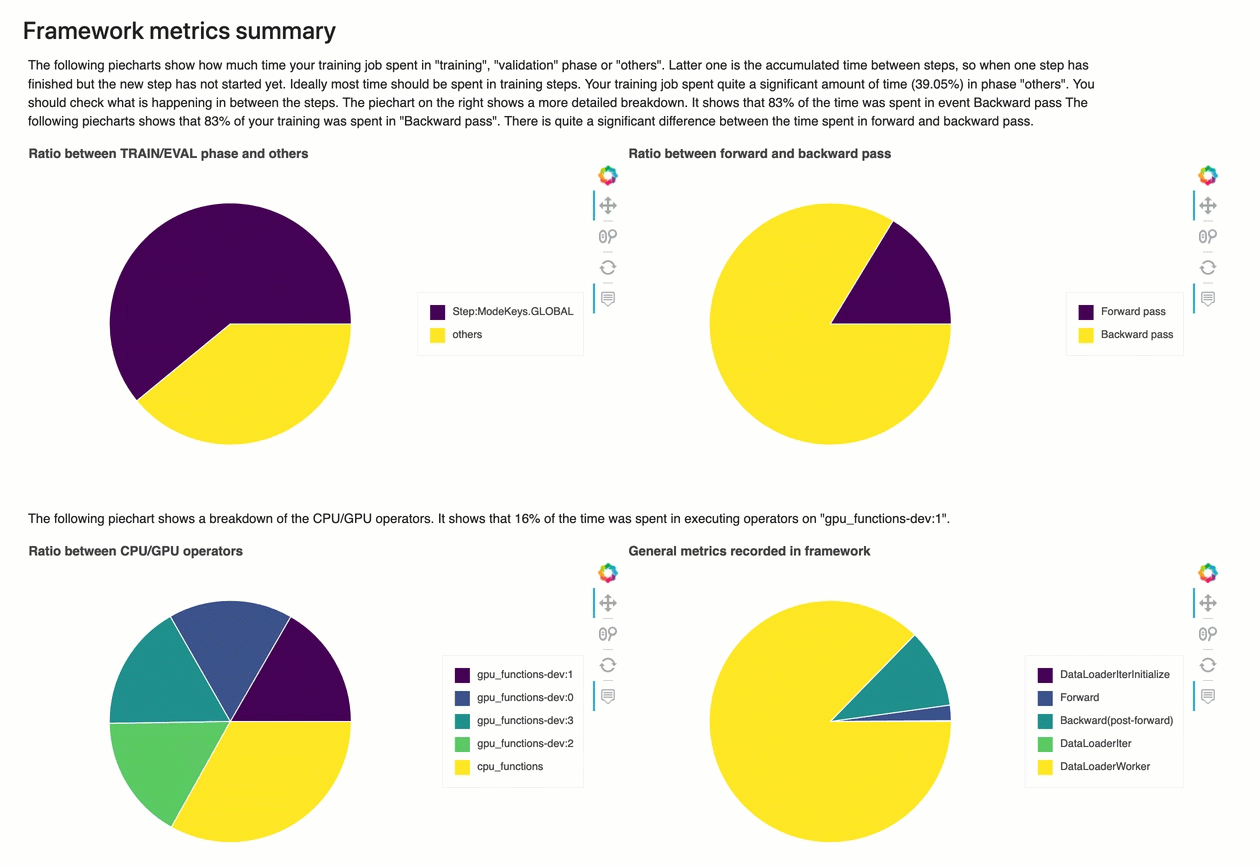
Cada um dos gráficos circulares analisa as métricas da framework coletadas em vários aspectos, da seguinte forma:
-
Proporção entre a fase TRAIN/EVAL e outras: Mostra a proporção entre as durações de tempo gastas em diferentes fases de treinamento.
-
Razão entre passe para frente e para trás: Mostra a proporção entre as durações de tempo gastas no passe para frente e para trás no ciclo de treinamento.
-
Proporção entre operadores de CPU/GPU: Mostra a proporção entre o tempo gasto em operadores executados em CPU ou GPU, como operadores convolucionais.
-
Métricas gerais registradas na framework: Mostra a proporção entre o tempo gasto nas principais métricas da framework, como carregamento de dados, avanço e retrocesso.
Visão geral: operadores de CPU
Esta seção fornece informações detalhadas sobre os operadores da CPU. A tabela mostra a porcentagem do tempo e o tempo cumulativo absoluto gasto nos operadores de CPU mais frequentemente chamados.
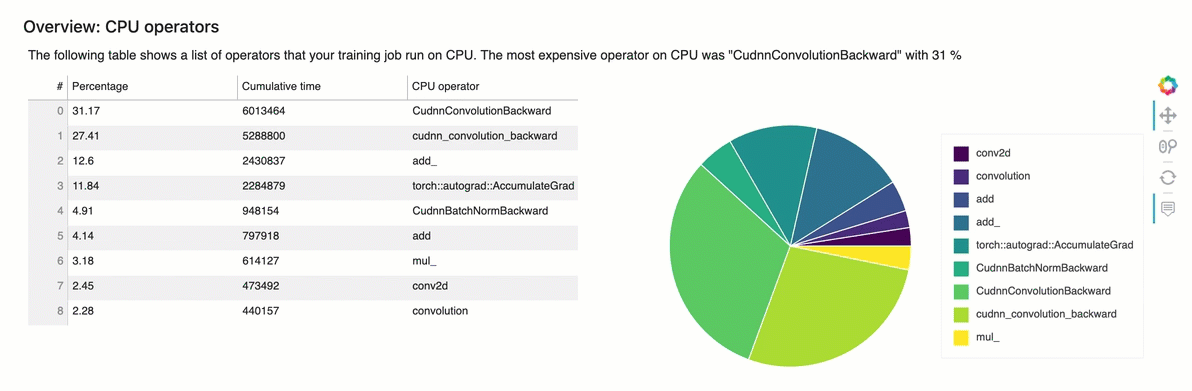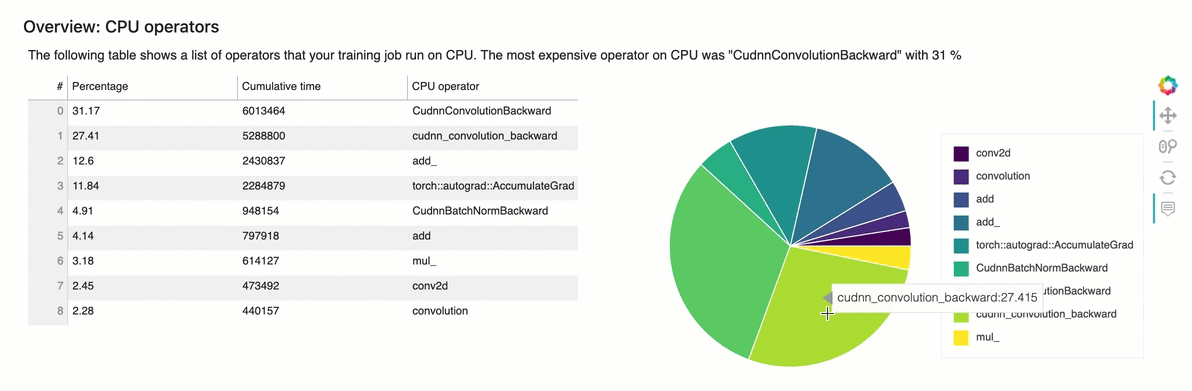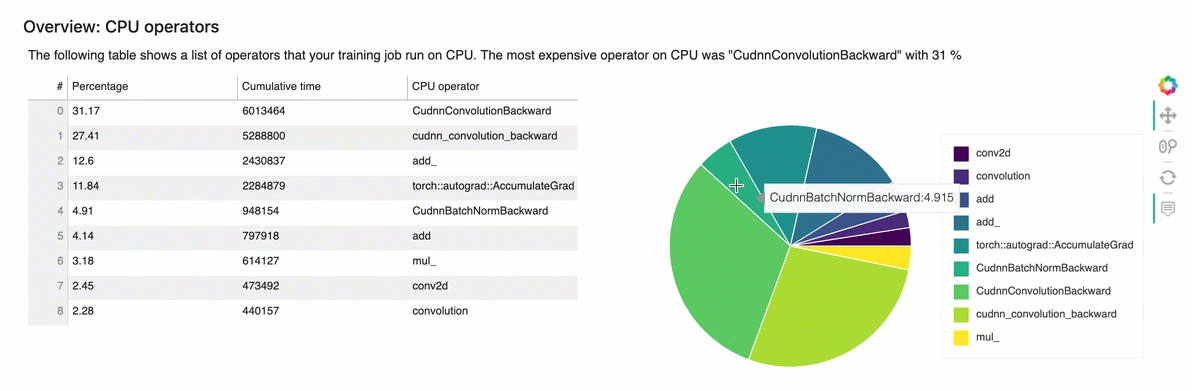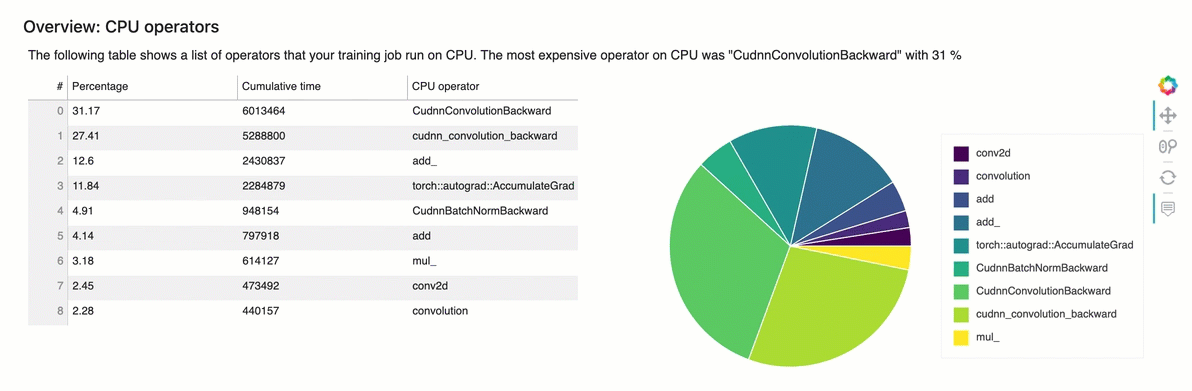
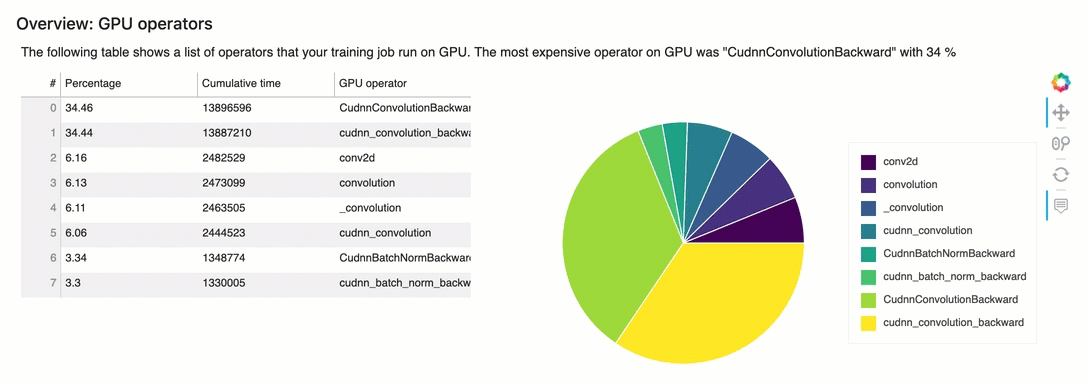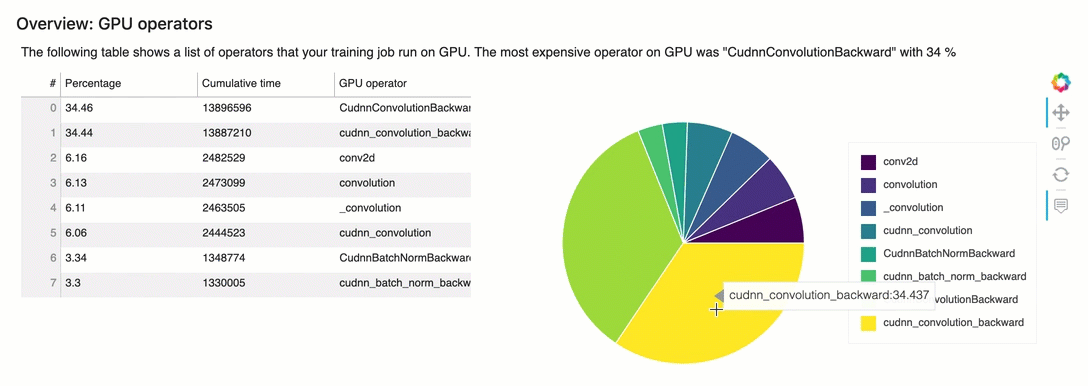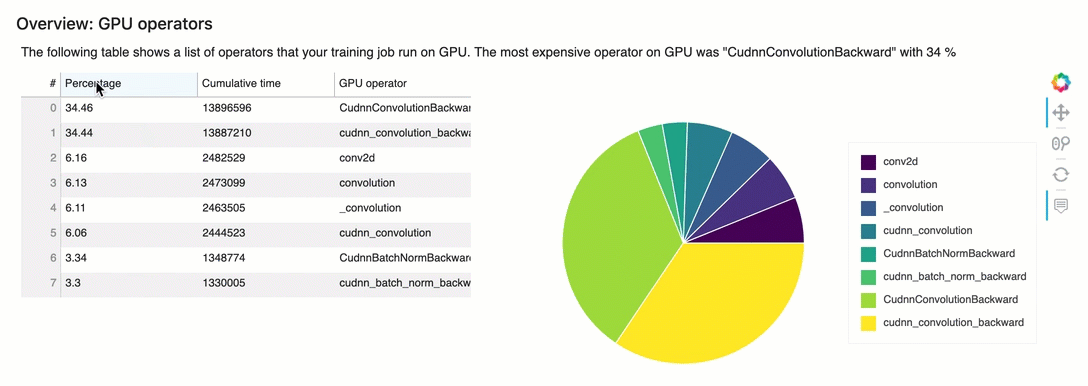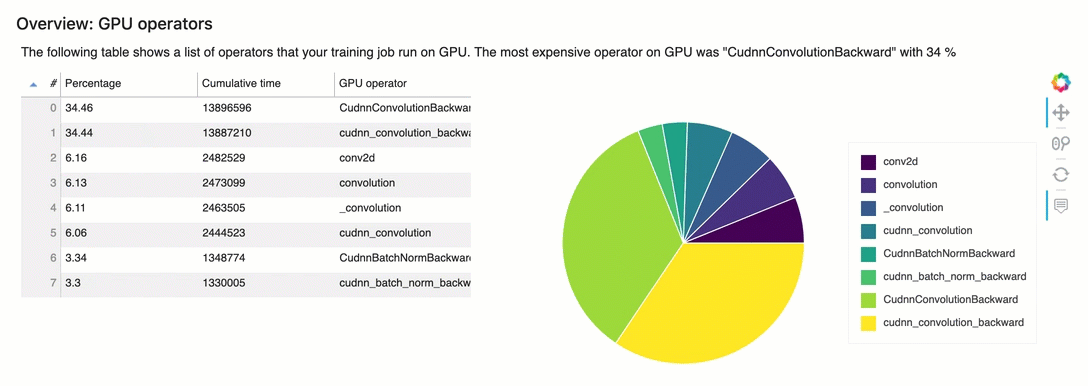
Visão geral: operadores de GPU
Esta seção fornece informações detalhadas sobre os operadores de GPU. A tabela mostra a porcentagem de tempo e o tempo acumulado absoluto gasto nos operadores de GPU chamados com mais frequência.
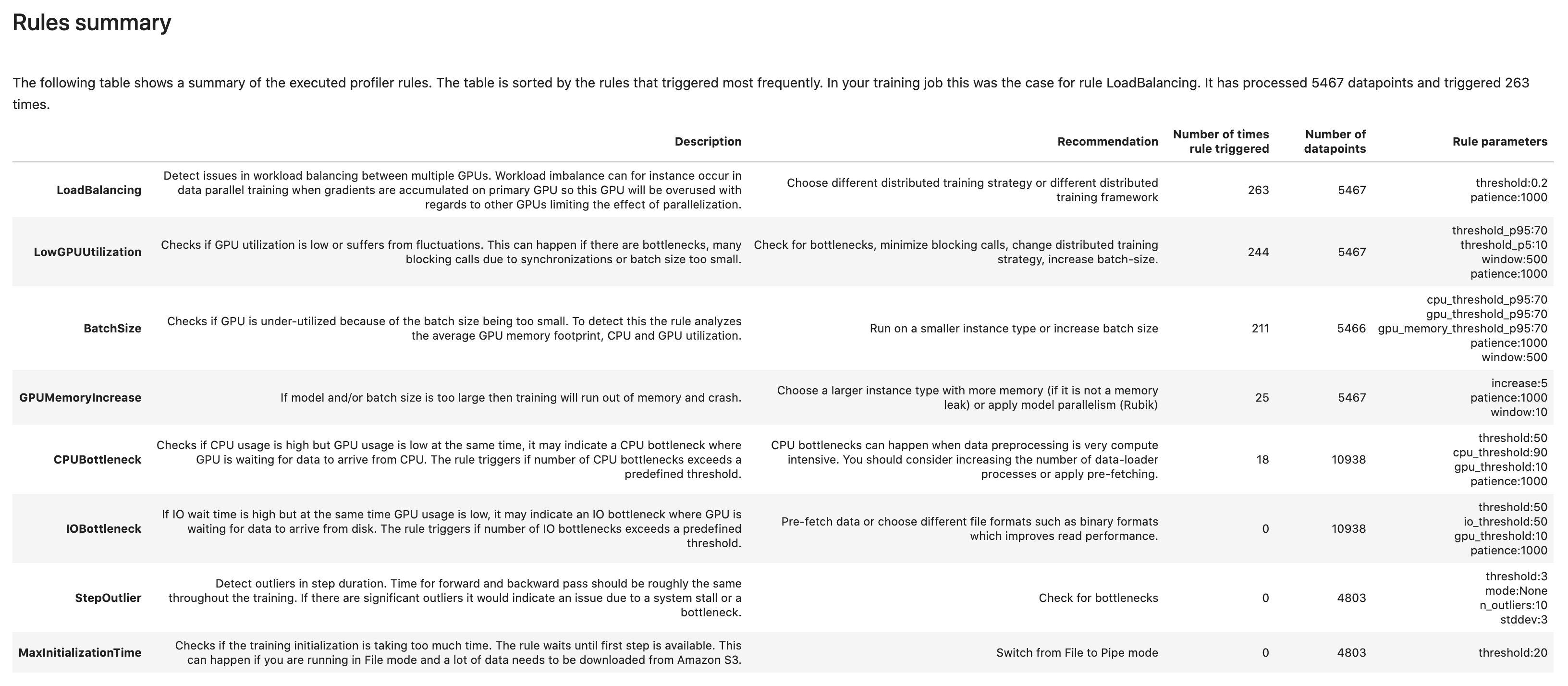
Resumo das regras
Nesta seção, o Debugger agrega todos os resultados da avaliação de regras, análises, descrições de regras e sugestões.
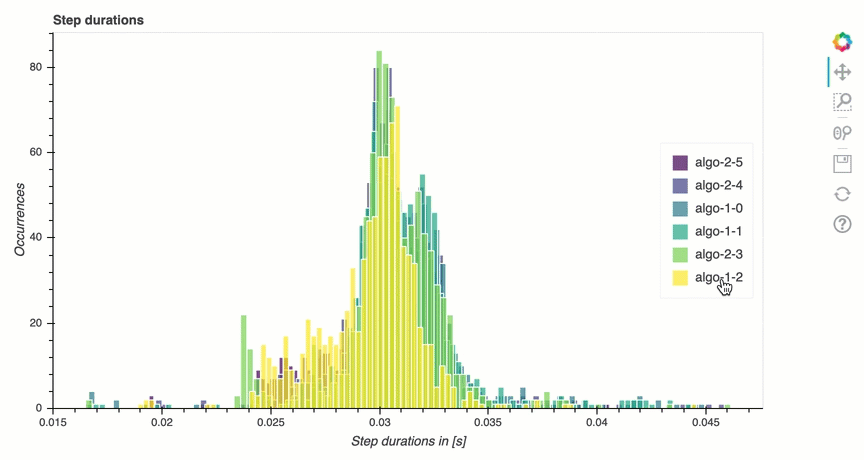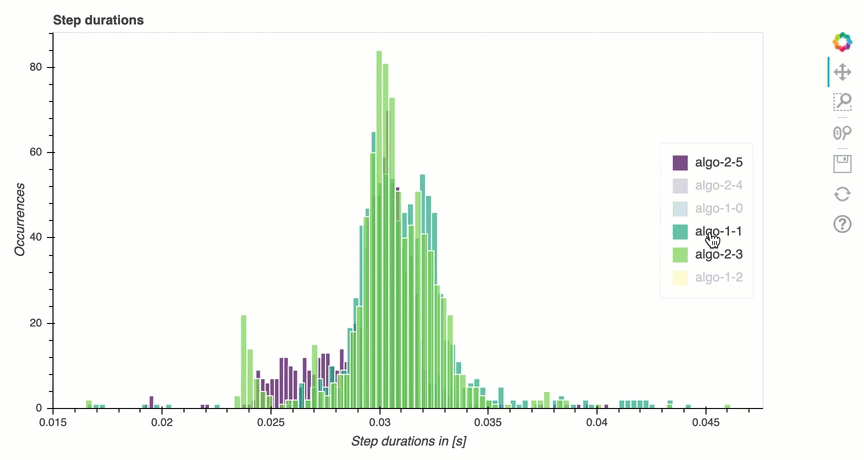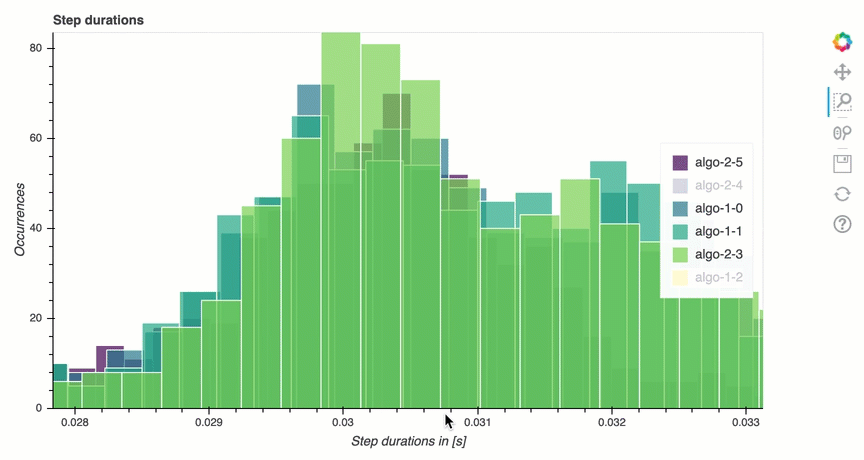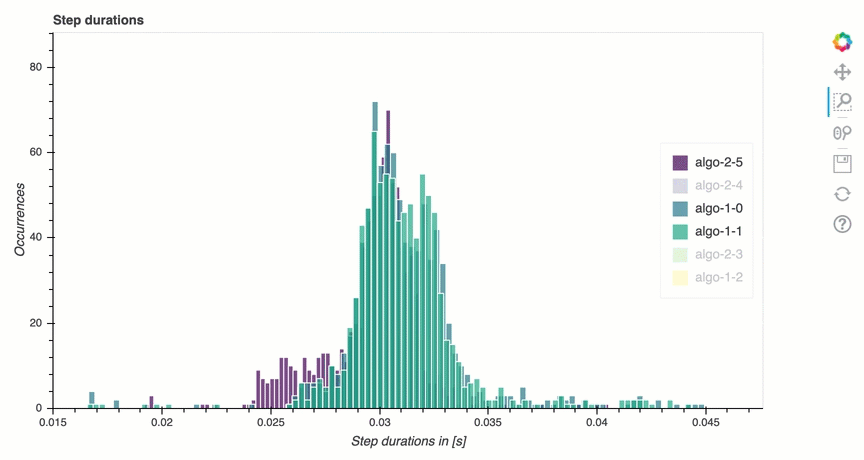
Analisando o ciclo de treinamento: durações das etapas
Nesta seção, você pode encontrar estatísticas detalhadas das durações das etapas em cada núcleo da GPU de cada nó. O depurador avalia valores médios, máximos, p99, p95, p50 e mínimos das durações das etapas e avalia os valores discrepantes das etapas. O histograma a seguir mostra as durações das etapas capturadas em diferentes nós de trabalho e. GPUs Você pode ativar ou desativar o histograma de cada operador escolhendo as legendas do lado direito. Você pode verificar se há uma GPU específica que está causando valores atípicos na duração da etapa.
Análise de utilização da GPU
Esta seção mostra as estatísticas detalhadas sobre a utilização do núcleo da GPU com base na regra LowGPUUtilization . Ele também resume as estatísticas de utilização da GPU, média, p95 e p5 para determinar se o trabalho de treinamento está subutilizado. GPUs
Tamanho do lote
Esta seção mostra as estatísticas detalhadas da utilização total da CPU, das utilizações individuais da GPU e da área ocupada pela memória da GPU. A BatchSize regra determina se você precisa alterar o tamanho do lote para melhor utilizar GPUs o. Você pode verificar se o tamanho do lote é muito pequeno, resultando em subutilização, ou muito grande, causando superutilização e problemas de falta de memória. No gráfico, as caixas mostram os intervalos percentuais p25 e p75 (preenchidos com roxo escuro e amarelo brilhante, respectivamente) da mediana (p50), e as barras de erro mostram o percentil 5 para o limite inferior e o percentil 95 para o limite superior.

Problemas com a CPU
Nesta seção, você pode detalhar os gargalos de CPU que a CPUBottleneck regra detectou em seu trabalho de treinamento. A regra verifica se a utilização da CPU está acima cpu_threshold (90% por padrão) e também se a utilização da GPU está abaixo gpu_threshold (10% por padrão).
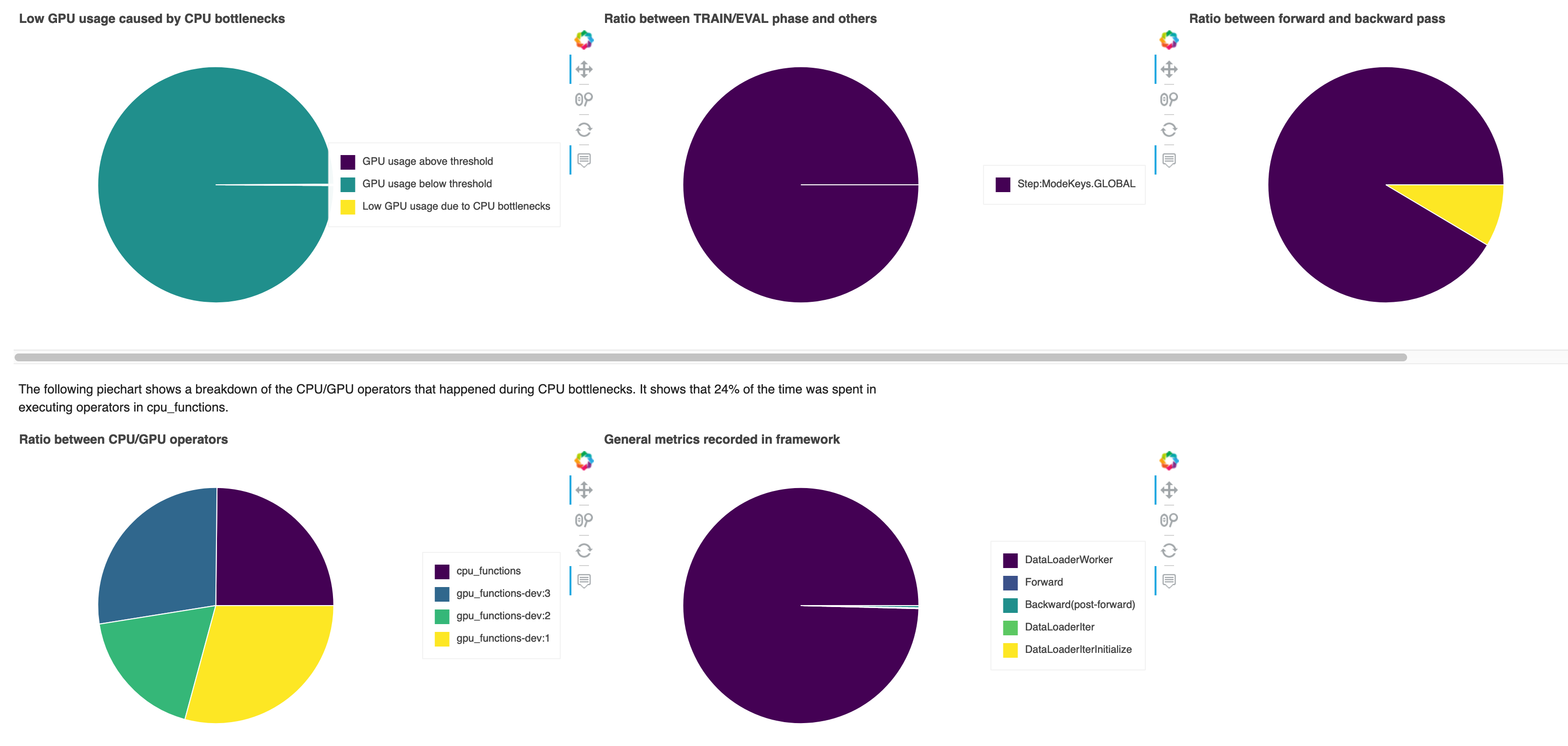
Os gráficos circulares mostram as seguintes informações:
-
Baixo uso da GPU causado por gargalos da CPU: Mostra a proporção de pontos de dados entre aqueles com utilização da GPU acima e abaixo do limite e aqueles que correspondem aos critérios de gargalo da CPU.
-
Proporção entre a fase TRAIN/EVAL e outras: Mostra a proporção entre as durações de tempo gastas em diferentes fases de treinamento.
-
Razão entre passe para frente e para trás: Mostra a proporção entre as durações de tempo gastas no passe para frente e para trás no ciclo de treinamento.
-
Proporção entre operadores de CPU/GPU — Mostra a proporção entre as durações de tempo gastas em e GPUs por operadores CPUs Python, como processos de carregador de dados e operadores de passagem para frente e para trás.
-
Métricas gerais registradas na estrutura: Mostra as principais métricas da estrutura e a proporção entre as durações de tempo gastas nas métricas.
Problemas de E/S
Nesta seção, você pode encontrar um resumo dos problemas de E/S. A regra avalia o tempo de espera de E/S e as taxas de utilização da GPU e monitora se o tempo gasto nas solicitações de E/S excede uma porcentagem limite do tempo total de treinamento. Isso pode indicar gargalos de E/S que GPUs aguardam a chegada dos dados do armazenamento.
Balanceamento de carga no treinamento com várias GPUs
Nesta seção, você pode identificar problemas de balanceamento da carga de trabalho em 1. GPUs
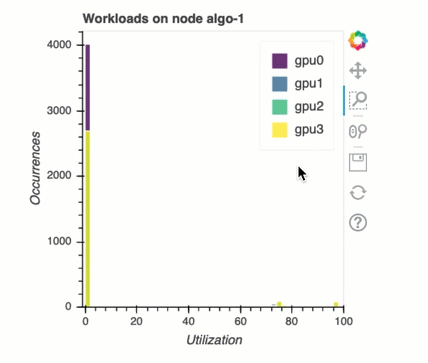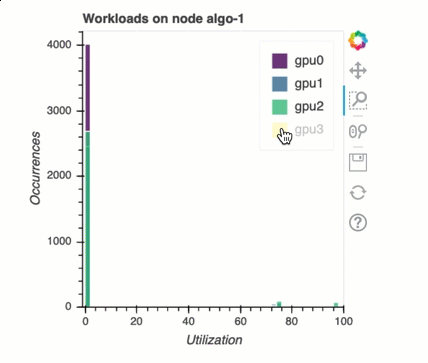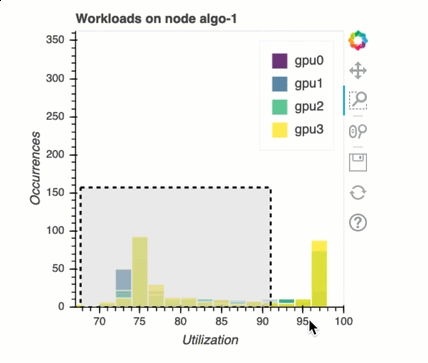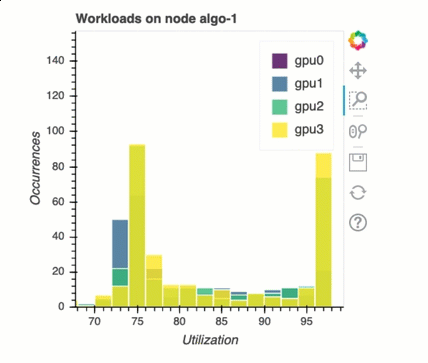
Análise de memória da GPU
Nesta seção, você pode analisar a utilização da memória da GPU coletada pela regra Increase GPUMemory. No gráfico, as caixas mostram os intervalos percentuais p25 e p75 (preenchidos com roxo escuro e amarelo brilhante, respectivamente) da mediana (p50), e as barras de erro mostram o percentil 5 para o limite inferior e o percentil 95 para o limite superior.

