As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Passo a passo do relatório de treinamento do Debugger XGBoost
Esta seção mostra o relatório de treinamento do DebuggerXGBoost. O relatório é agregado automaticamente, dependendo da expressão regular do tensor de saída, reconhecendo que tipo de seu trabalho de treinamento está entre classificação binária, classificação multiclasse e regressão.
Importante
No relatório, os gráficos e as recomendações são fornecidos para fins informativos e não são definitivos. Você é responsável por fazer sua própria avaliação independente das informações.
Tópicos
- Distribuição de rótulos verdadeiros do conjunto de dados
- Gráfico de perda versus etapas
- Importância do recurso
- Matriz de confusão
- Avaliação da matriz de confusão
- Taxa de precisão de cada elemento diagonal durante a iteração
- Curva característica de operação do receptor
- Distribuição de resíduos na última etapa salva
- Erro absoluto de validação por compartimento de etiquetas durante a iteração
Distribuição de rótulos verdadeiros do conjunto de dados
Esse histograma mostra a distribuição de classes rotuladas (para classificação) ou valores (para regressão) em seu conjunto de dados original. A distorção em seu conjunto de dados pode contribuir para imprecisões. Essa visualização está disponível para os seguintes tipos de modelo: classificação binária, multiclassificação e regressão.
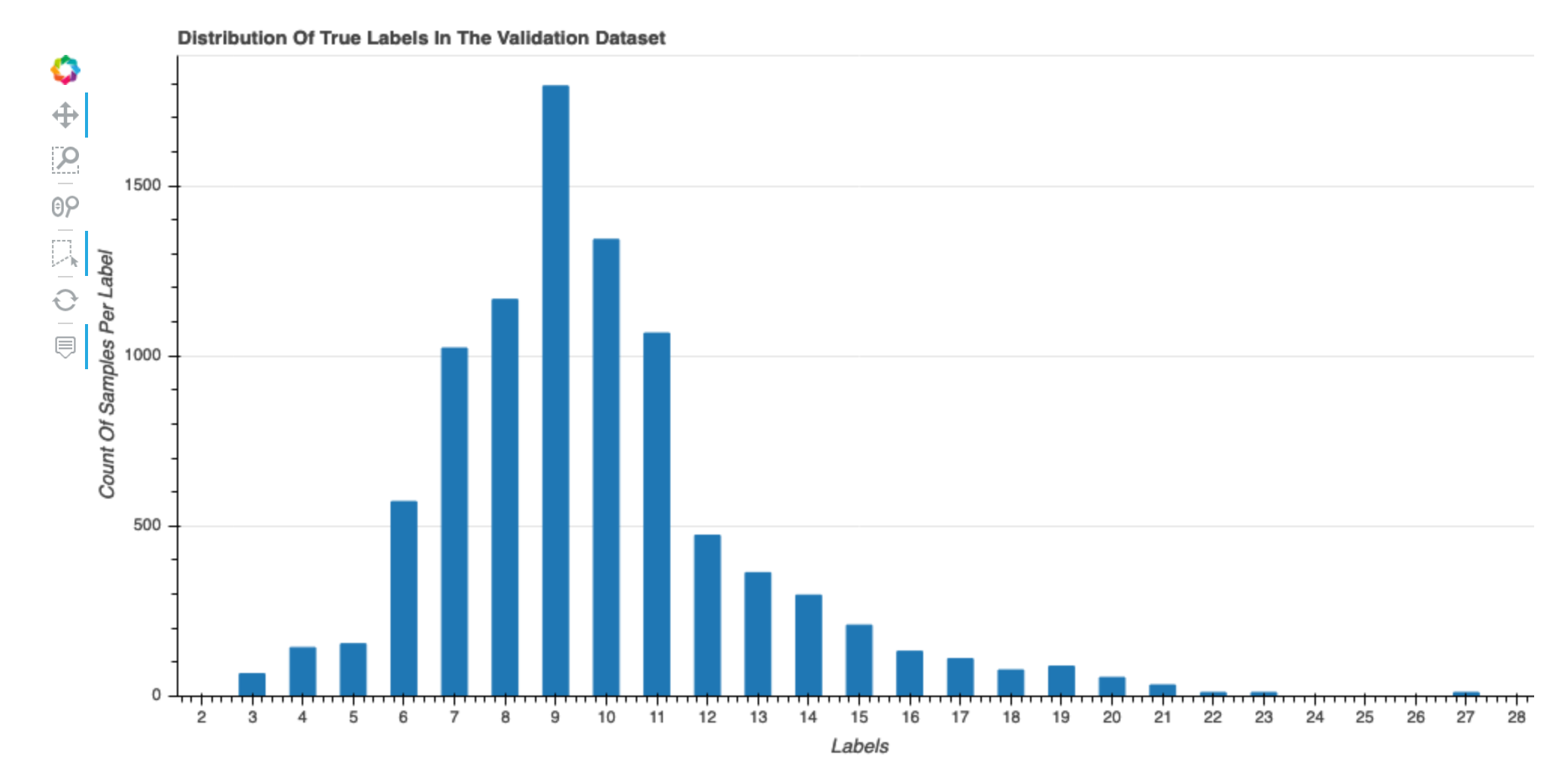
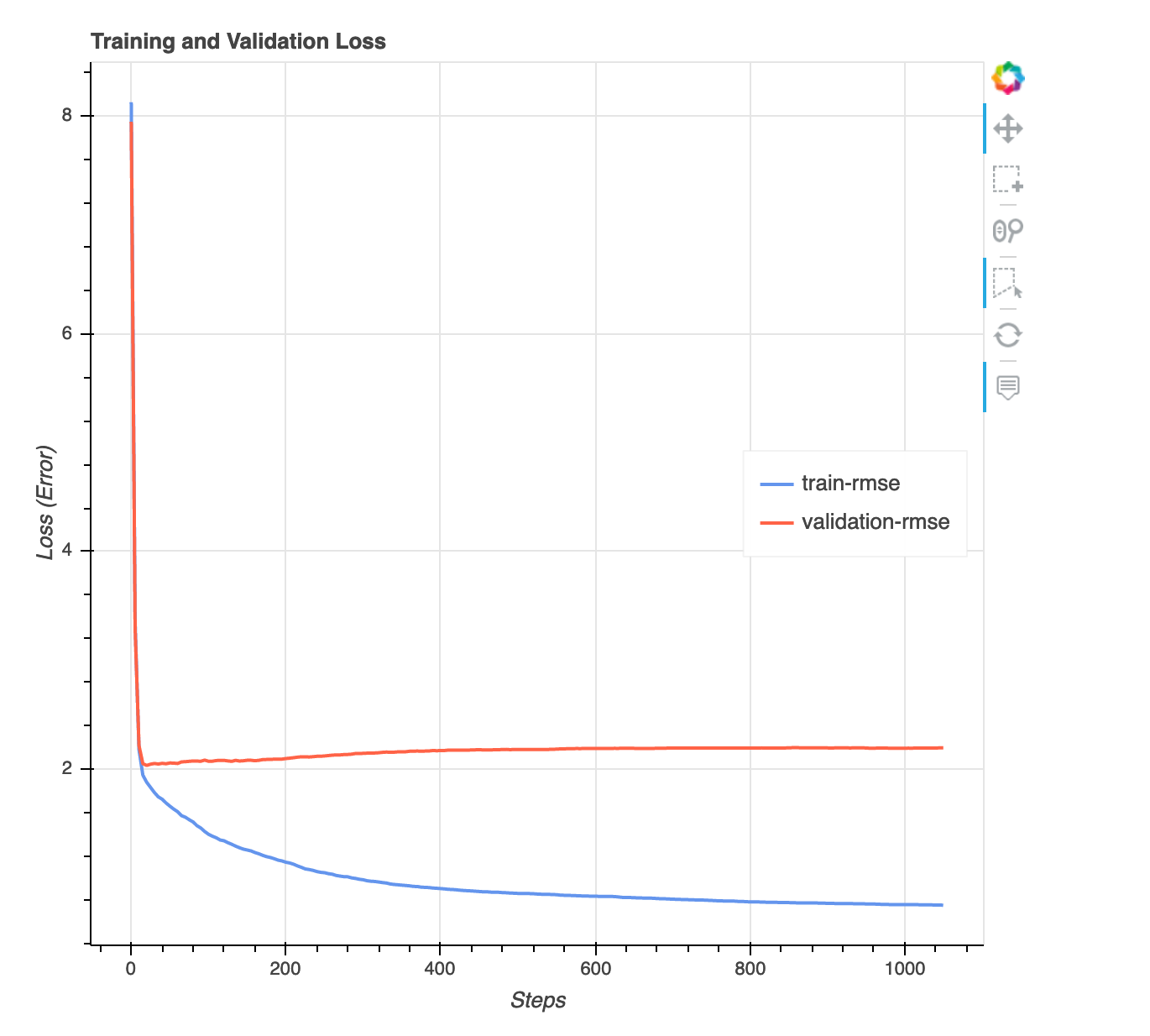
Gráfico de perda versus etapas
Este é um gráfico de linhas que mostra a progressão da perda nos dados de treinamento e nos dados de validação ao longo das etapas do treinamento. A perda é o que você definiu em sua função objetivo, como erro quadrático médio. Você pode avaliar se o ajuste do modelo está excessivo ou insuficiente a partir desse gráfico. Esta seção também fornece informações que você pode usar para determinar como resolver os problemas de ajuste excessivo e insuficiente. Essa visualização está disponível para os seguintes tipos de modelo: classificação binária, multiclassificação e regressão.
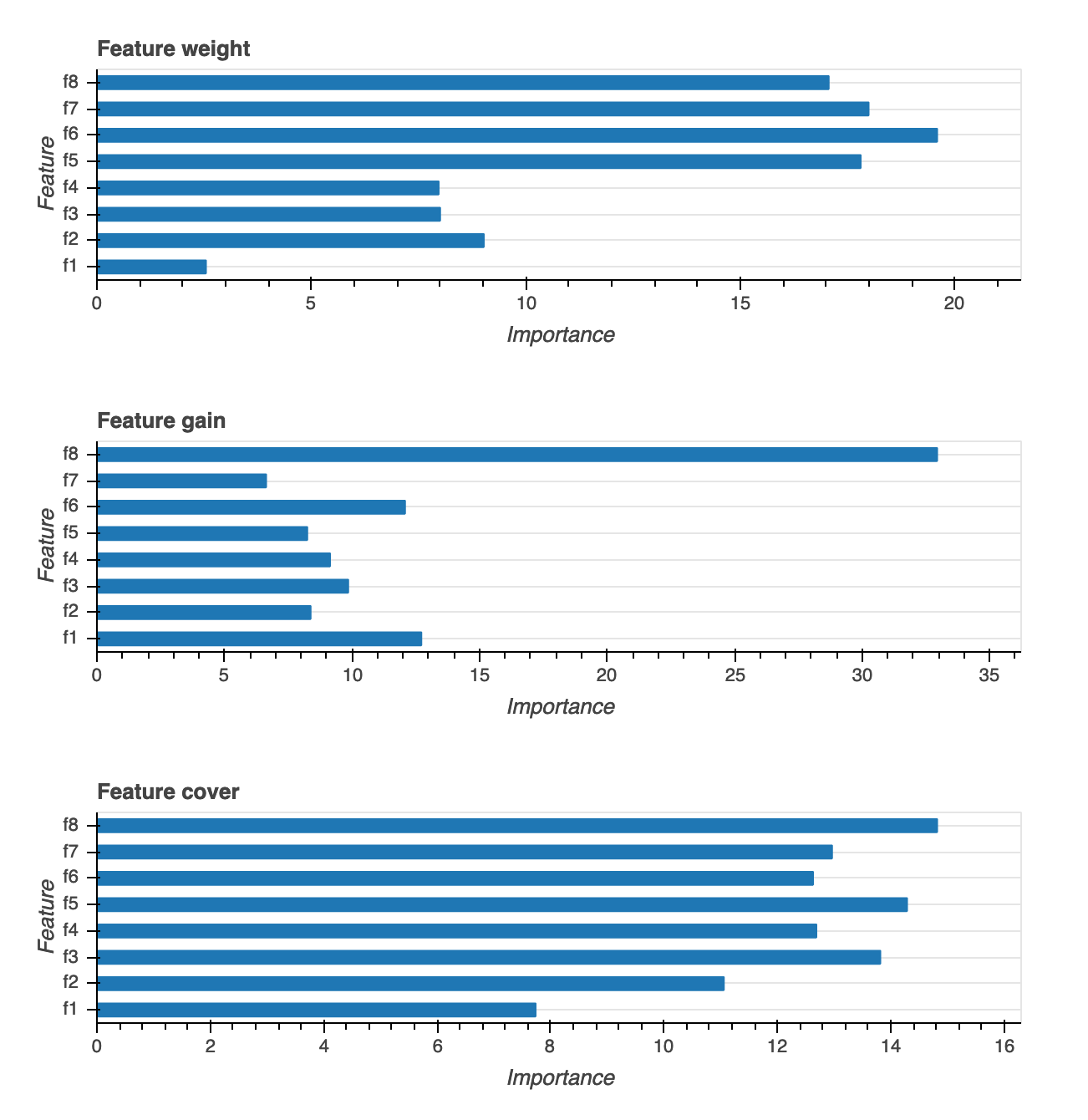
Importância do recurso
Há três tipos diferentes de visualizações de importância de atributos fornecidos: peso, ganho e cobertura. Fornecemos definições detalhadas para cada um dos três no relatório. As visualizações de importância do atributo ajudam você a aprender quais atributos em seu conjunto de dados de treinamento contribuíram para as previsões. As visualizações da importância do atributo estão disponívei para os seguintes tipos de modelo: classificação binária, multiclassificação e regressão.
Matriz de confusão
Essa visualização é aplicável somente aos modelos de classificação binária e multiclasse. A precisão por si só pode não ser suficiente para avaliar o desempenho do modelo. Para alguns casos de uso, como saúde e detecção de fraudes, também é importante conhecer a taxa de falsos positivos e a taxa de falsos negativos. Uma matriz de confusão fornece as dimensões adicionais para avaliar o desempenho do seu modelo.

Avaliação da matriz de confusão
Esta seção fornece mais informações sobre as métricas micro, macro e ponderadas sobre precisão, recall e pontuação F1 para seu modelo.
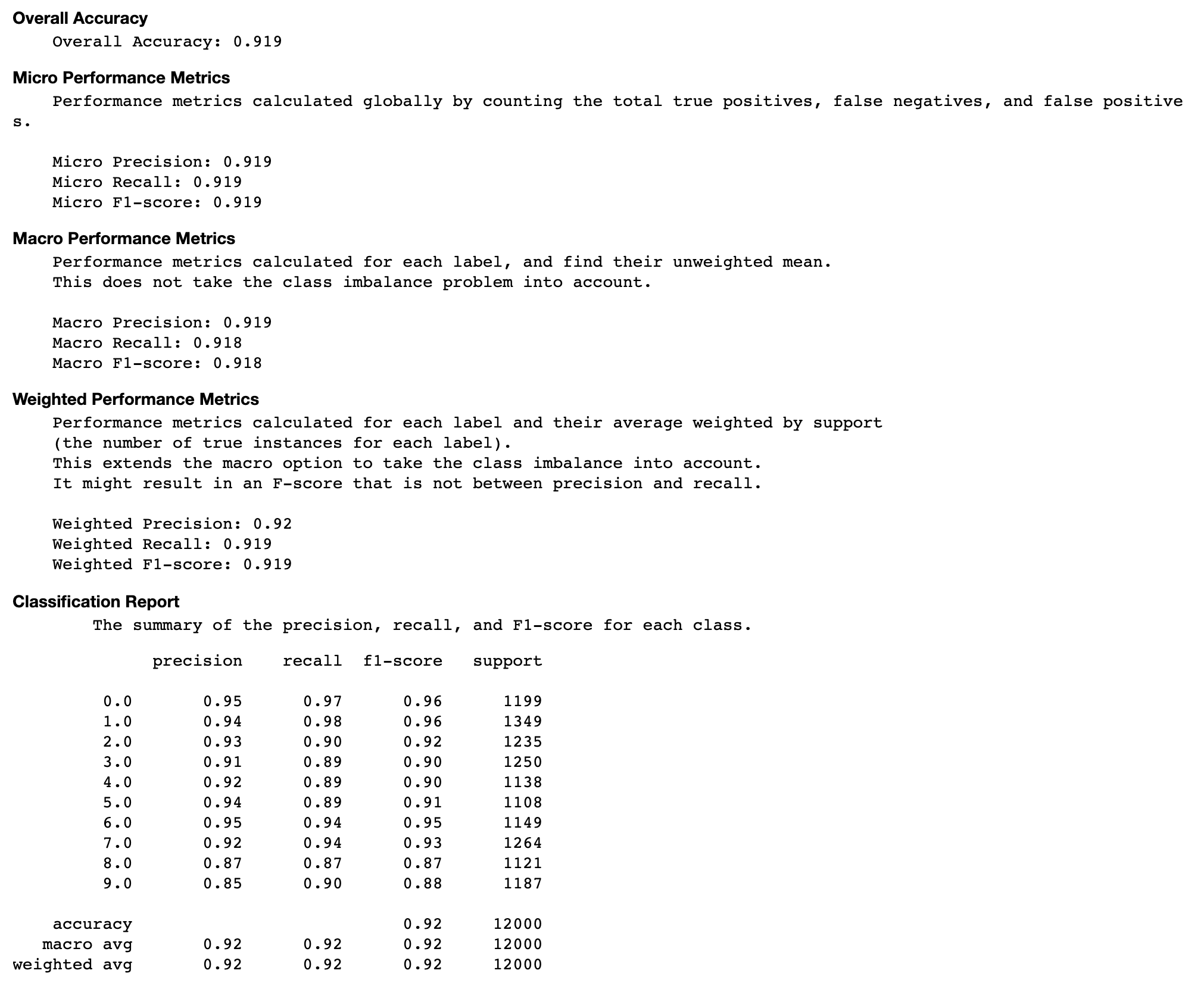
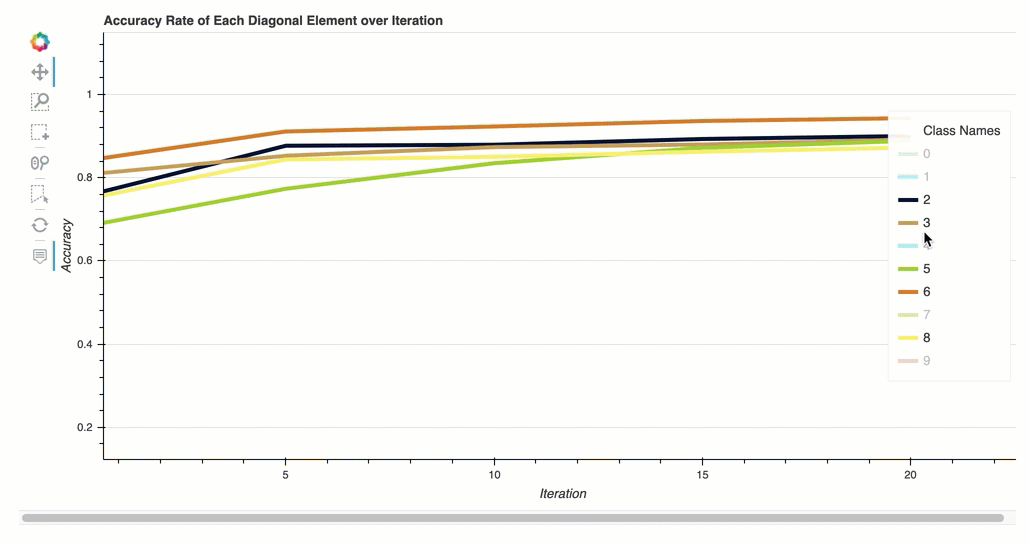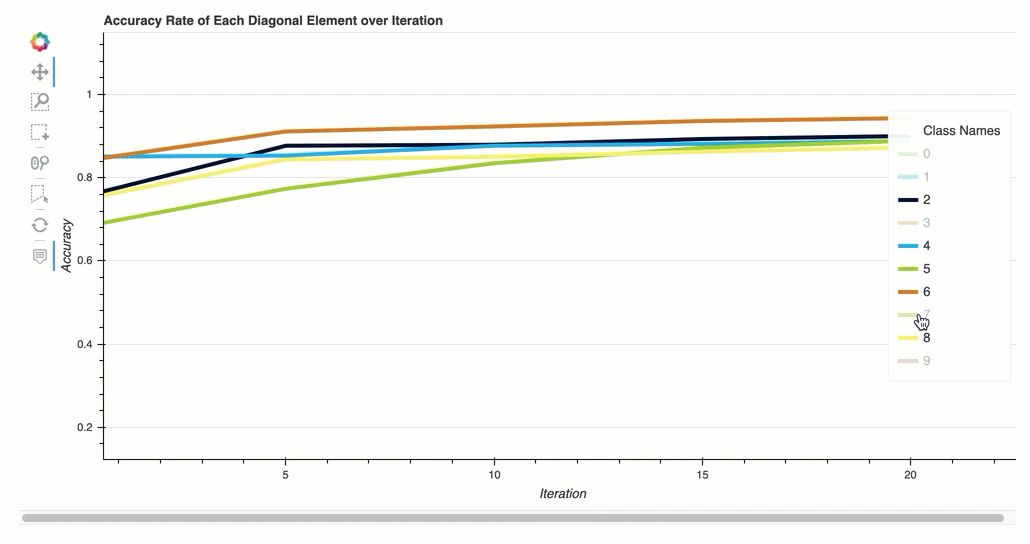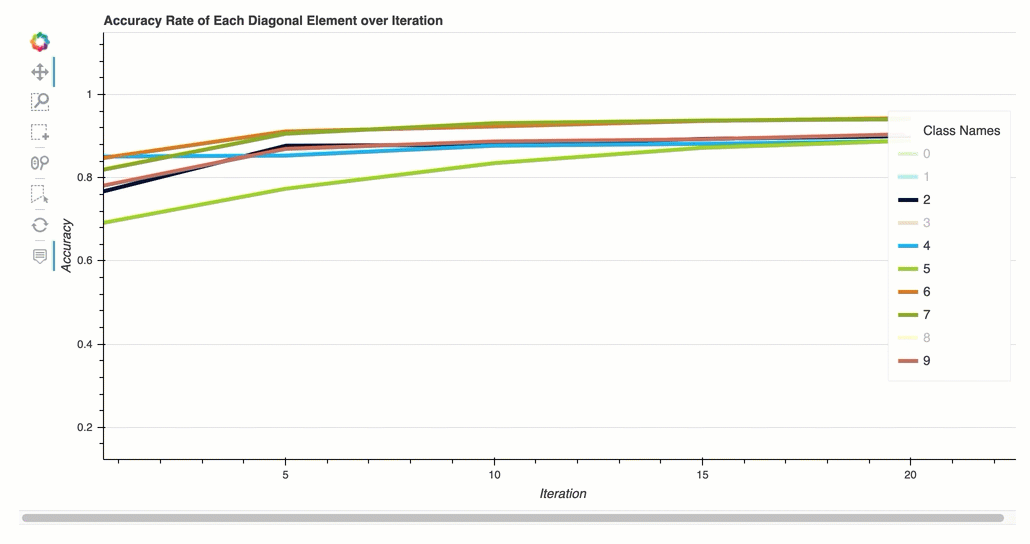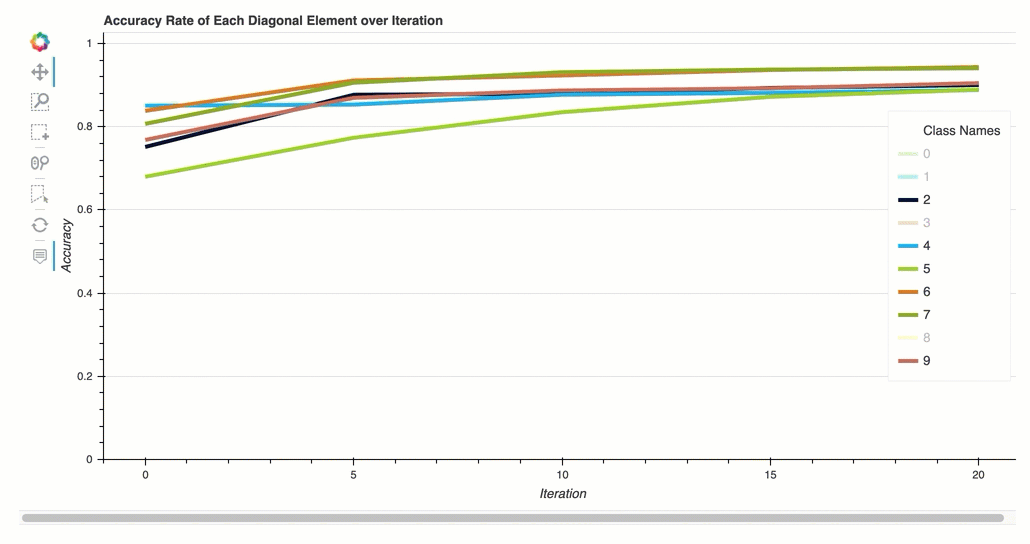
Taxa de precisão de cada elemento diagonal durante a iteração
Essa visualização é aplicável somente aos modelos de classificação binária e classificação multiclasse. Este é um gráfico de linhas que traça os valores diagonais na matriz de confusão ao longo das etapas de treinamento de cada classe. Este gráfico mostra como a precisão de cada classe progride ao longo das etapas do treinamento. Você pode identificar as classes com baixo desempenho nesse gráfico.
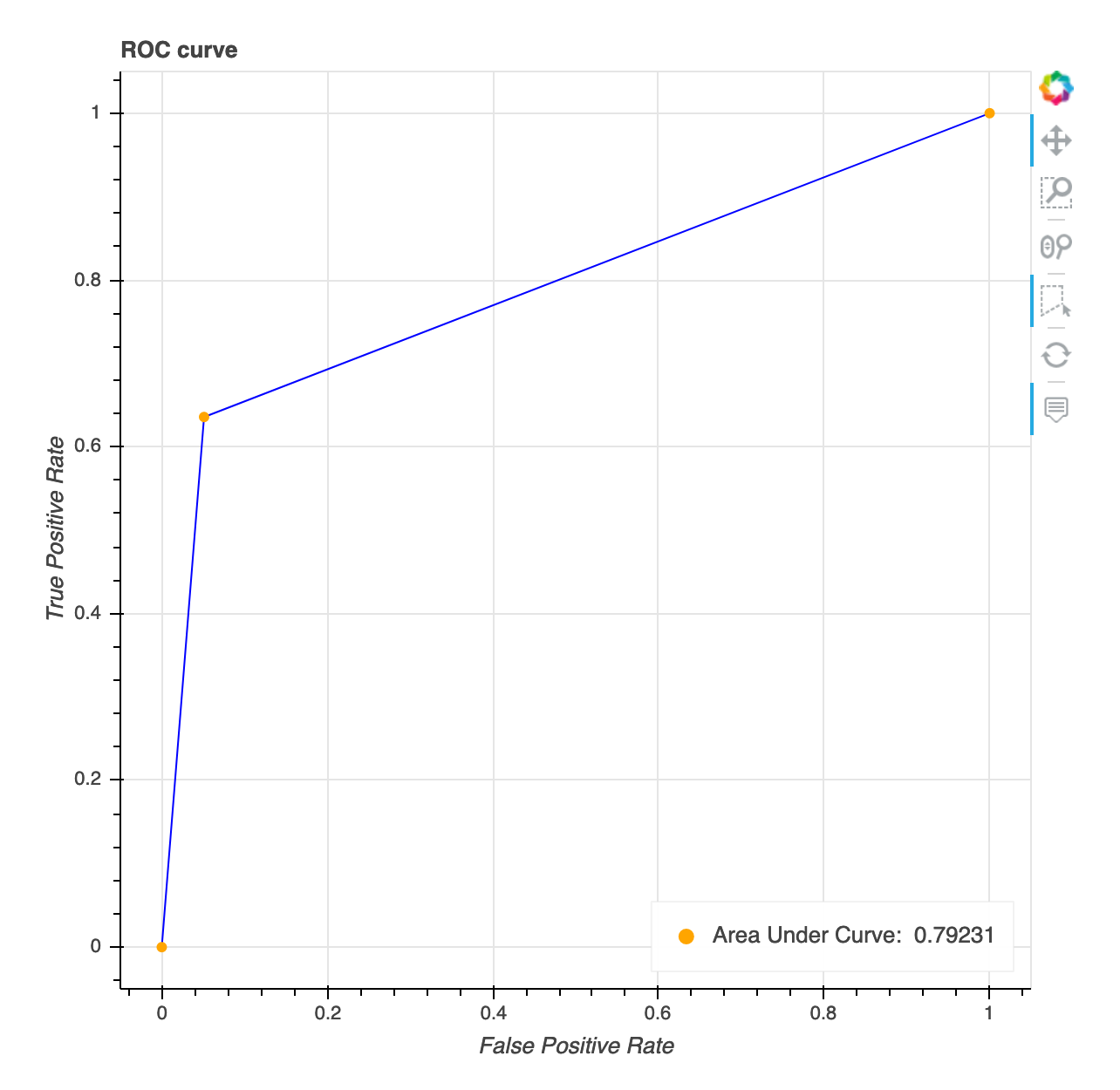
Curva característica de operação do receptor
Essa visualização é aplicável somente aos modelos de classificação binária. A curva característica de operação do receptor é comumente usada para avaliar o desempenho do modelo de classificação binária. O eixo y da curva é True Positive Rate (TPF) e o eixo x é falso positivo (FPR). O gráfico também exibe o valor da área abaixo da curva (AUC). Quanto maior o AUC valor, mais preditivo é o seu classificador. Você também pode usar a ROC curva para entender a compensação entre TPR FPR e identificar o limite de classificação ideal para seu caso de uso. O limite de classificação pode ser ajustado para ajustar o comportamento do modelo para reduzir mais de um ou outro tipo de erro (FP/FN).
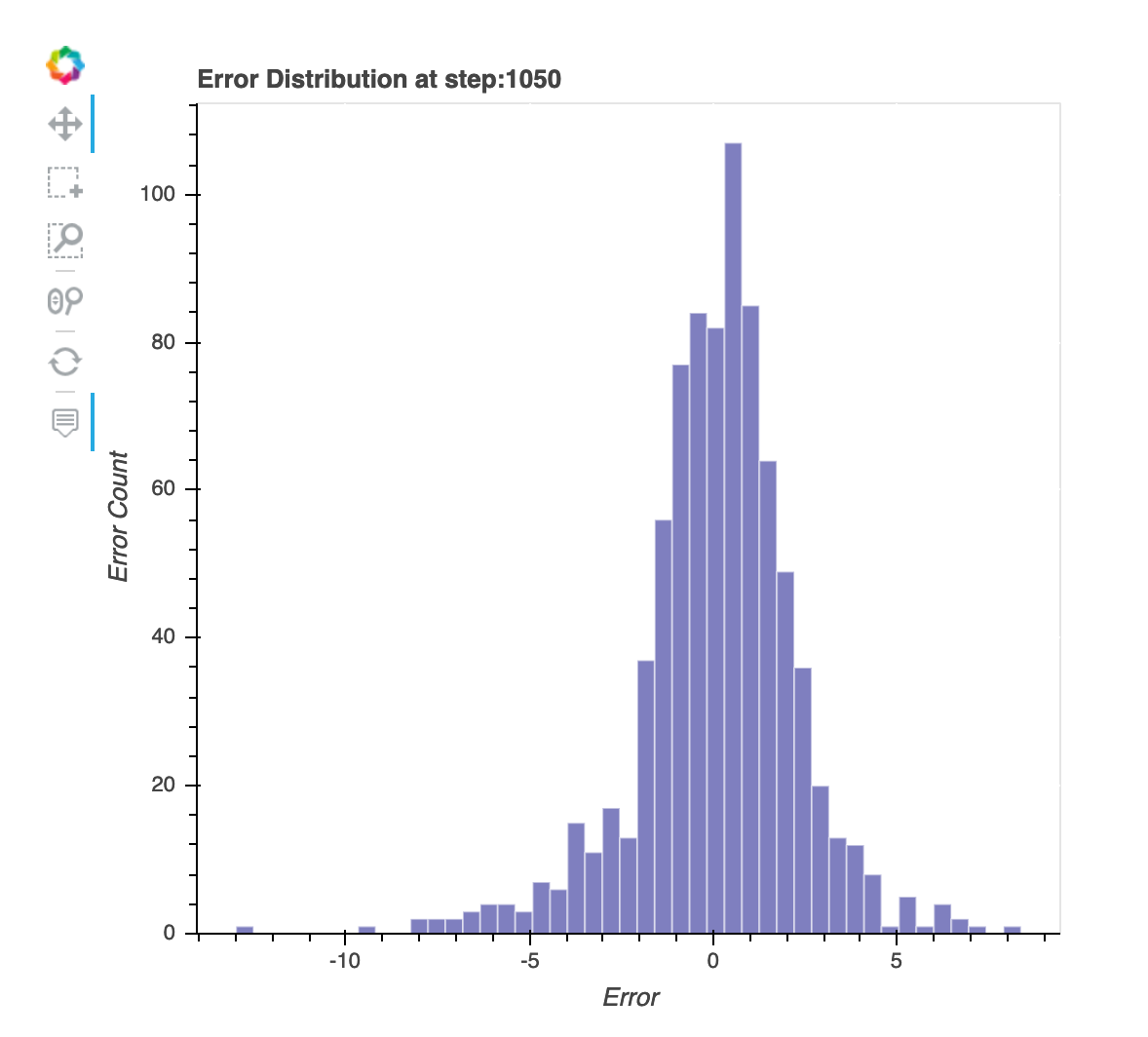
Distribuição de resíduos na última etapa salva
Essa visualização é um gráfico de colunas que mostra as distribuições residuais na última etapa que o Debugger captura. Nessa visualização, você pode verificar se a distribuição residual está próxima da distribuição normal centralizada em zero. Se os resíduos estiverem distorcidos, seus atributos podem não ser suficientes para prever os rótulos.
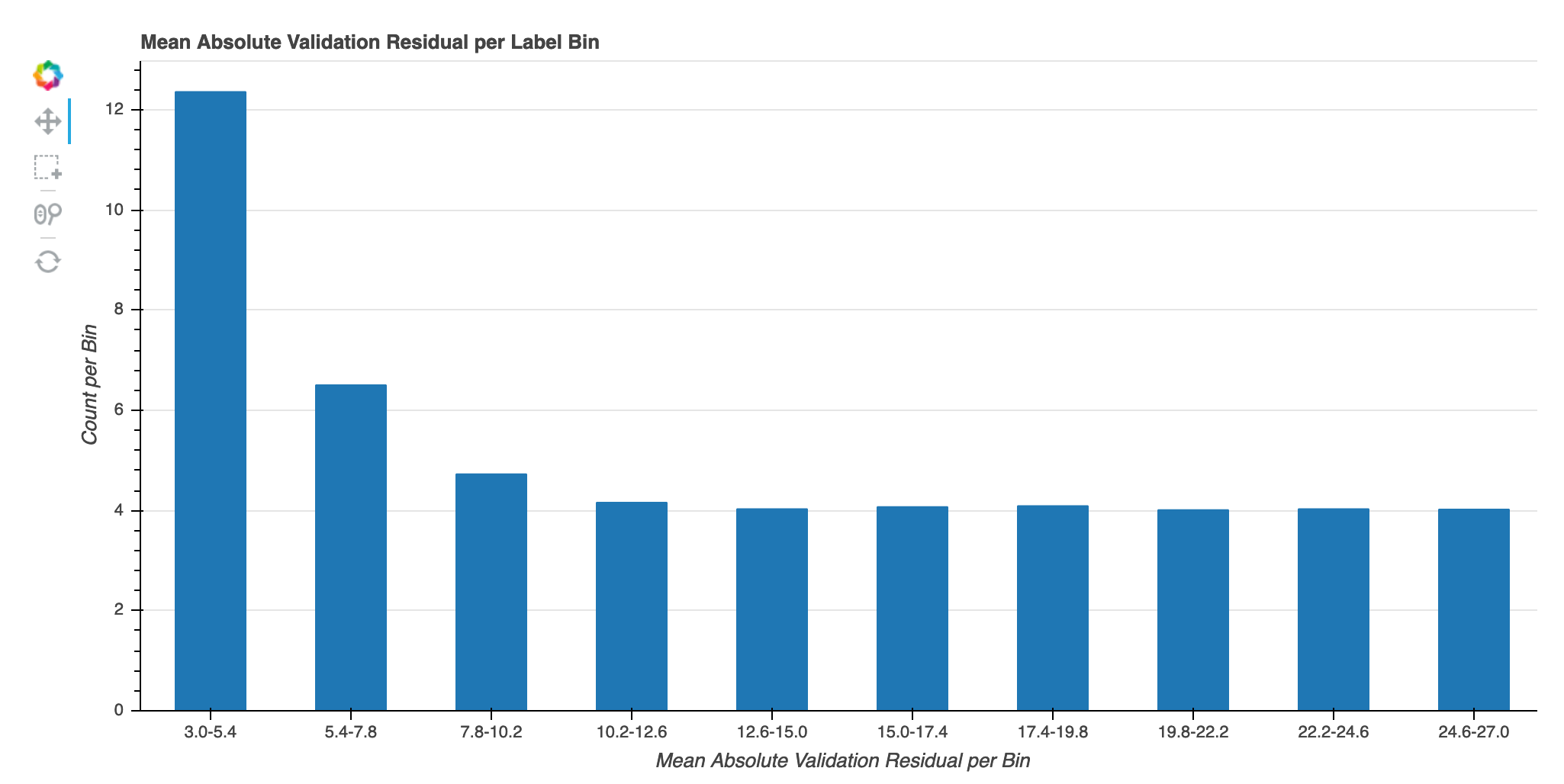
Erro absoluto de validação por compartimento de etiquetas durante a iteração
Essa visualização é aplicável somente para modelos de regressão. Os valores-alvo reais são divididos em 10 intervalos. Essa visualização mostra como os erros de validação progridem em cada intervalo ao longo das etapas de treinamento nos gráficos de linha. O erro absoluto de validação é o valor absoluto da diferença entre a previsão e o real durante a validação. Você pode identificar os intervalos de baixo desempenho nessa visualização.