As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Entenda as opções para implantar modelos e obter inferências na Amazon SageMaker
Para ajudar você a começar a usar a SageMaker inferência, consulte as seções a seguir, que explicam suas opções para implantar seu modelo SageMaker e obter inferências. A Opções de inferência na Amazon SageMaker seção pode ajudá-lo a determinar qual recurso é mais adequado ao seu caso de uso para inferência.
Você pode consultar a Recursos seção para obter mais informações sobre solução de problemas e referência, blogs e exemplos para ajudar você a começar, além de informações comunsFAQs.
Tópicos
Antes de começar
Esses tópicos pressupõem que você tenha criado e treinado um ou mais modelos de machine learning e esteja pronto para implantá-los. Você não precisa treinar seu modelo para implantá-lo SageMaker e obter inferências. SageMaker Se você não tem seu próprio modelo, também pode usar SageMaker algoritmos integrados ou modelos pré-treinados.
Se você é novato SageMaker e ainda não escolheu um modelo para implantar, siga as etapas do SageMaker tutorial Get Started with Amazon. Use o tutorial para se familiarizar com a forma como SageMaker gerencia o processo de ciência de dados e como ele lida com a implantação do modelo. Para obter mais informações sobre treinar um modelo, consulte Treinar modelos.
Para informações adicionais, referência e exemplos, consulte o Recursos.
Etapas para a implantação do modelo
Para endpoints de inferência, o fluxo de trabalho geral consiste no seguinte:
Crie um modelo no SageMaker Inference apontando para artefatos de modelo armazenados no Amazon S3 e uma imagem de contêiner.
Selecionar uma opção de inferência. Para obter mais informações, consulte Opções de inferência na Amazon SageMaker.
Crie uma configuração de endpoint de SageMaker inferência escolhendo o tipo de instância e o número de instâncias que você precisa por trás do endpoint. Você pode usar o Amazon SageMaker Inference Recommender para obter recomendações para tipos de instância. Para Inferência Serverless, você só precisa fornecer a configuração de memória necessária com base no tamanho do seu modelo.
Crie um endpoint de SageMaker inferência.
Invoque seu endpoint para receber uma inferência como resposta.
O diagrama a seguir mostra o fluxo de trabalho anterior.
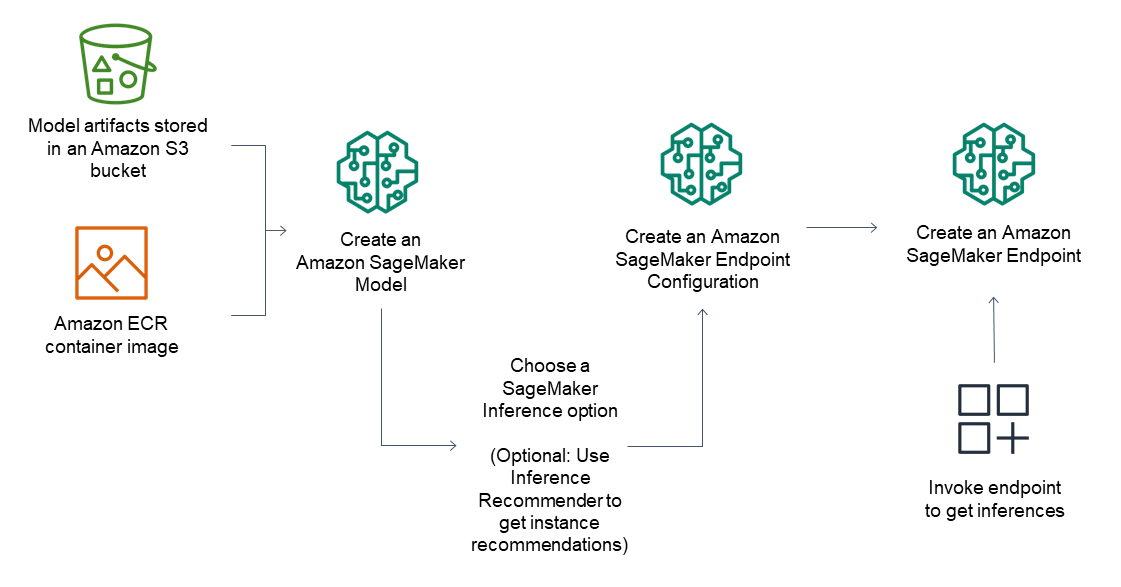
Você pode realizar essas ações usando o AWS console, o AWS SDKs, o SageMaker Python SDK AWS CloudFormation ou o. AWS CLI
Para inferência em lote com transformação em lote, aponte para os artefatos do modelo e os dados de entrada e crie um trabalho de inferência em lote. Em vez de hospedar um endpoint para inferência, SageMaker envia suas inferências para um local Amazon S3 de sua escolha.
