As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Preparar conjuntos de dados
Nesta etapa, você carrega o conjunto de dados do Censo de adultos
Para executar o exemplo a seguir, cole o código de amostra em uma célula na sua instância de caderno.
Carregar conjunto de dados do censo de adultos usando SHAP
Usando a biblioteca SHAP, importe o conjunto de dados do Censo de Adultos conforme mostrado a seguir:
import shap X, y = shap.datasets.adult() X_display, y_display = shap.datasets.adult(display=True) feature_names = list(X.columns) feature_names
nota
Se o kernel atual do Jupyter não tiver a biblioteca SHAP, instale-a executando o seguinte comando conda:
%conda install -c conda-forge shap
Se estiver usando JupyterLab, você deve atualizar manualmente o kernel após a conclusão da instalação e das atualizações. Execute o seguinte script IPython para encerrar o kernel (o kernel será reiniciado automaticamente):
import IPython IPython.Application.instance().kernel.do_shutdown(True)
O objeto de lista feature_names deve retornar a seguinte lista de atributos:
['Age', 'Workclass', 'Education-Num', 'Marital Status', 'Occupation', 'Relationship', 'Race', 'Sex', 'Capital Gain', 'Capital Loss', 'Hours per week', 'Country']
dica
Se você está começando com dados não rotulados, você pode usar o Amazon SageMaker Ground Truth para criar um fluxo de trabalho de rotulagem de dados em minutos. Para saber mais, consulte Dados de rótulos.
Visão geral do conjunto de dados
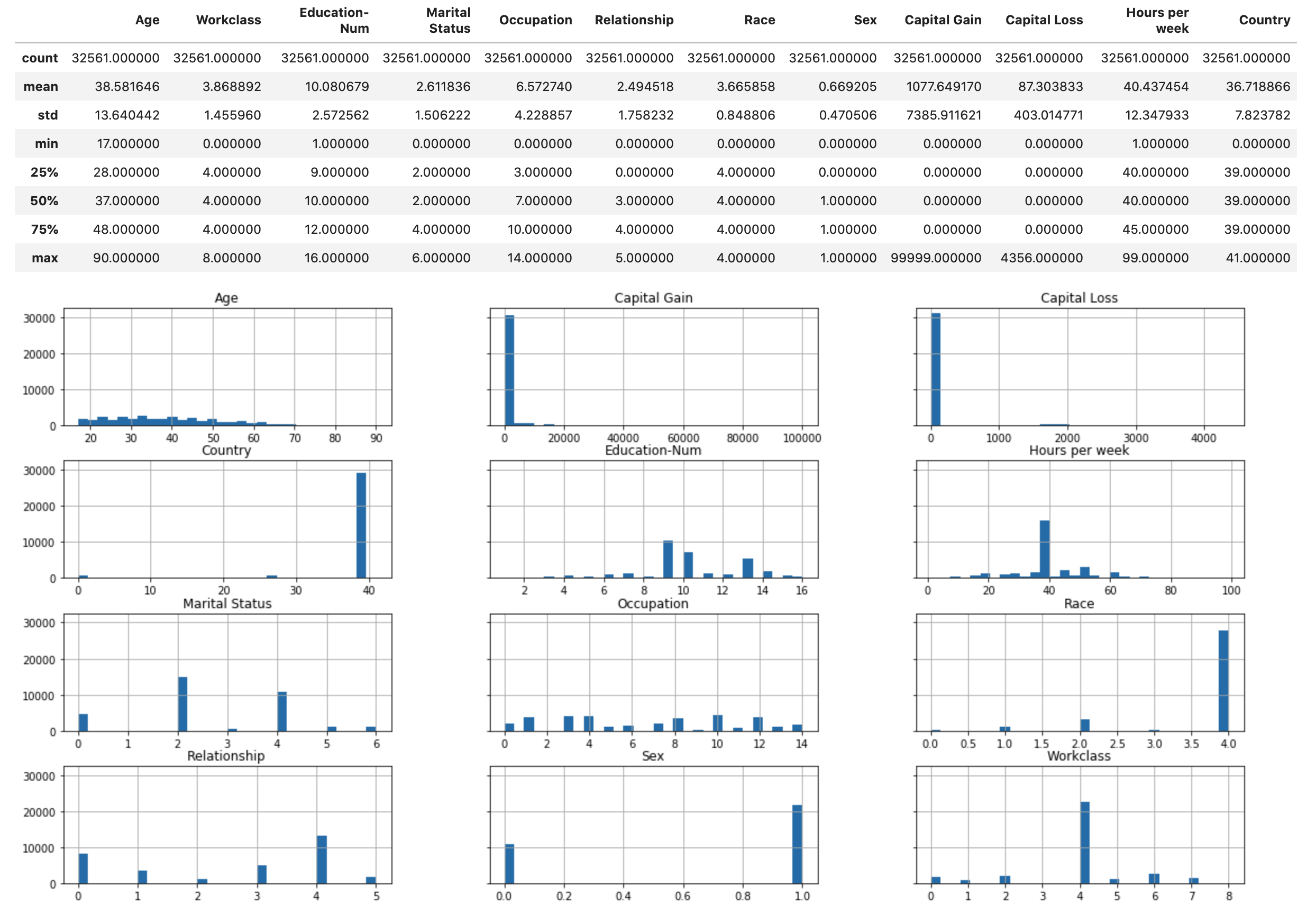
Execute o script a seguir para exibir a visão geral estatística do conjunto de dados e os histogramas dos atributos numéricos.
display(X.describe()) hist = X.hist(bins=30, sharey=True, figsize=(20, 10))
dica
Se você quiser usar um conjunto de dados que precisa ser limpo e transformado, você pode simplificar e agilizar o pré-processamento de dados e a engenharia de recursos usando o Amazon SageMaker Data Wrangler. Para saber mais, consulte Preparar dados de ML com o Amazon SageMaker Data Wrangler.
Divida o conjunto de dados em treinamento, validação e teste
Usando o Sklearn, divida o conjunto de dados em um conjunto de treinamento e um conjunto de testes. O conjunto de treinamento é usado para treinar o modelo, enquanto o conjunto de teste é usado para avaliar o desempenho do modelo final treinado. O conjunto de dados é classificado aleatoriamente com a semente aleatória fixa: 80% do conjunto de dados para o conjunto de treinamento e 20% para um conjunto de teste.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) X_train_display = X_display.loc[X_train.index]
Divida o conjunto de treinamento para separar um conjunto de validação. O conjunto de validação é usado para avaliar o desempenho do modelo treinado enquanto ajusta os hiperparâmetros do modelo. 75% do conjunto de treinamento se torna o conjunto de treinamento final e o restante é o conjunto de validação.
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=1) X_train_display = X_display.loc[X_train.index] X_val_display = X_display.loc[X_val.index]
Usando o pacote pandas, alinhe explicitamente cada conjunto de dados concatenando os atributos numéricos com os rótulos verdadeiros.
import pandas as pd train = pd.concat([pd.Series(y_train, index=X_train.index, name='Income>50K', dtype=int), X_train], axis=1) validation = pd.concat([pd.Series(y_val, index=X_val.index, name='Income>50K', dtype=int), X_val], axis=1) test = pd.concat([pd.Series(y_test, index=X_test.index, name='Income>50K', dtype=int), X_test], axis=1)
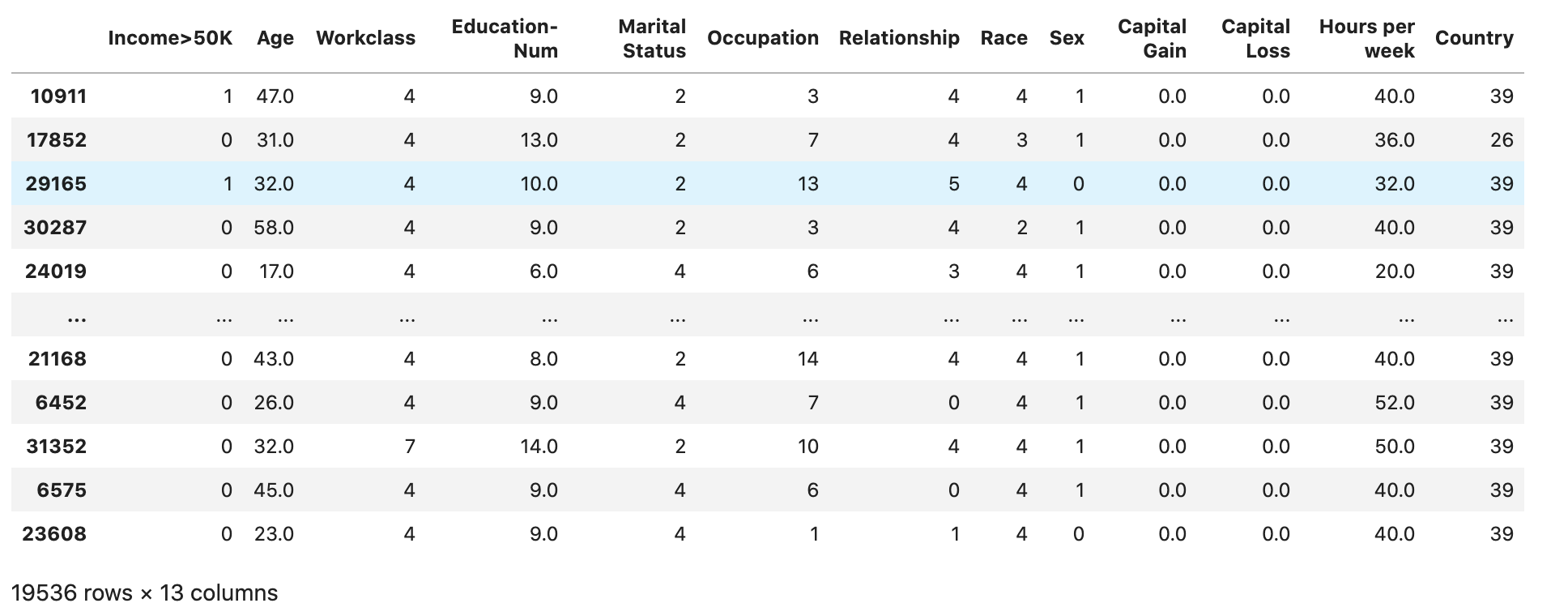
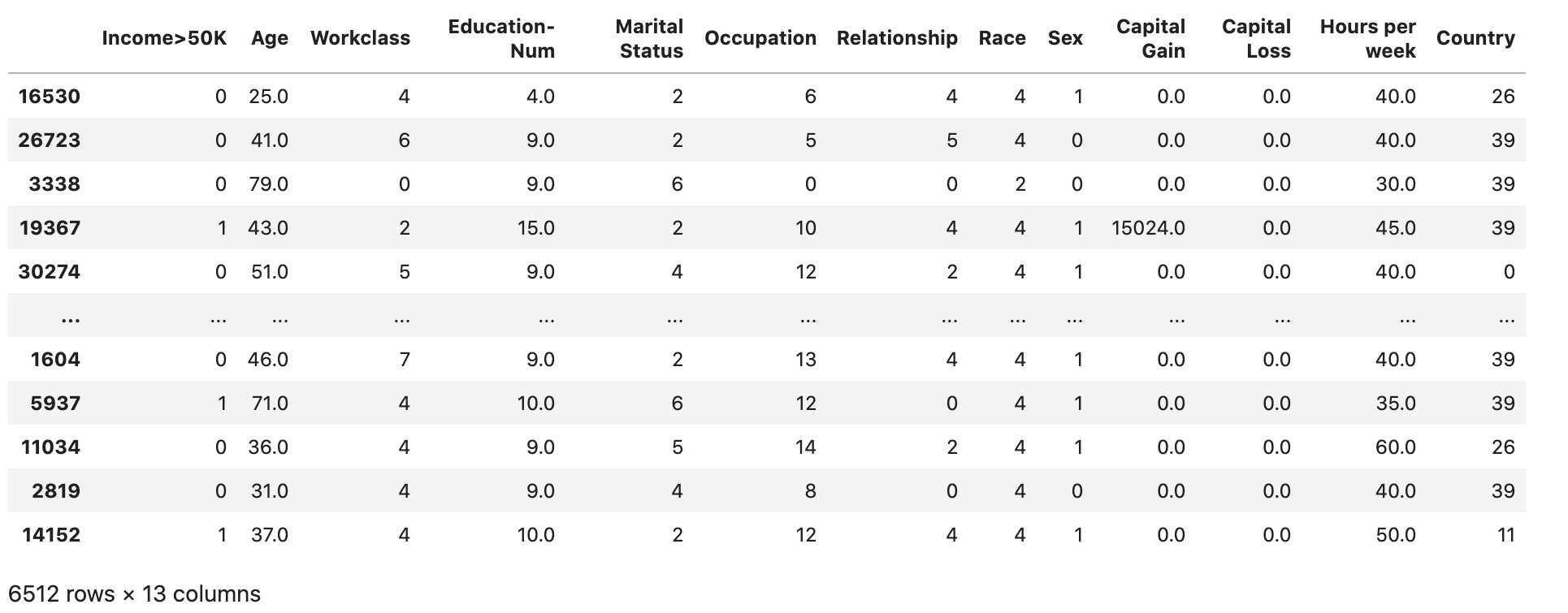
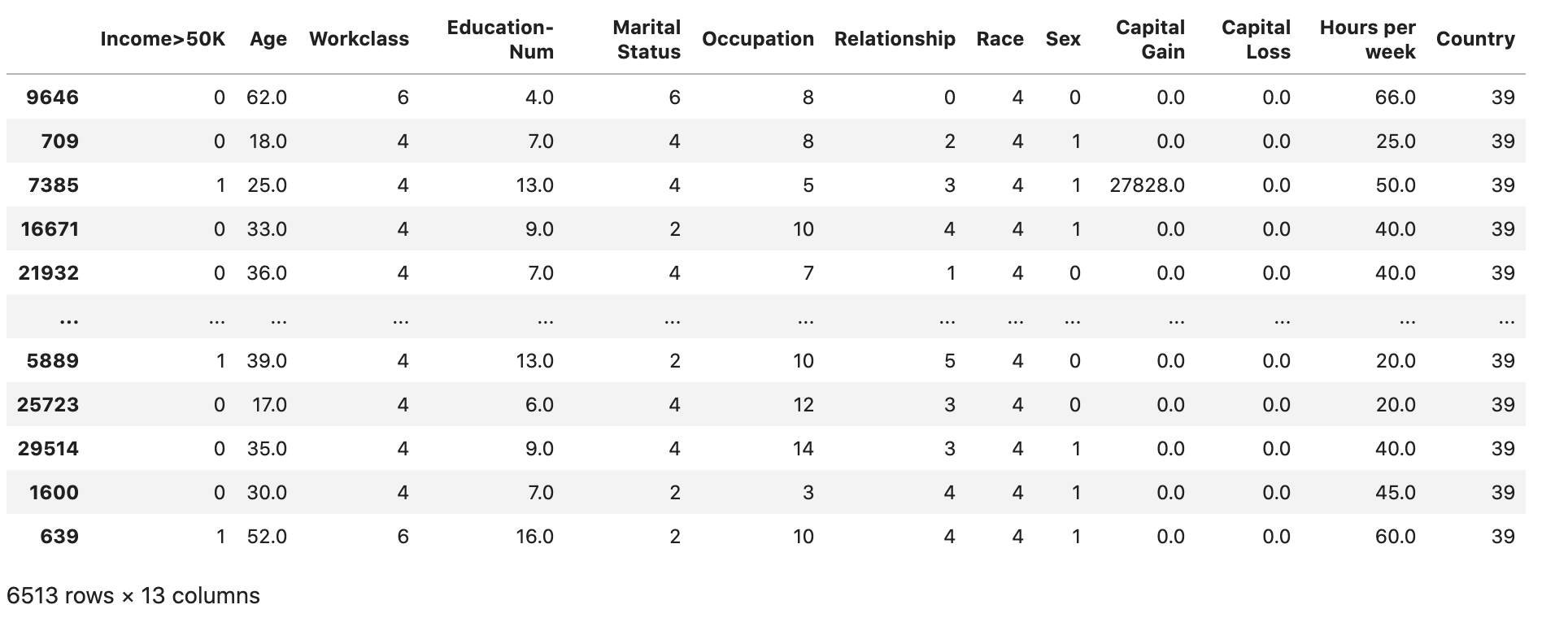
Verifique se o conjunto de dados está dividido e estruturado conforme o esperado:
train
validation
test
Converter os conjuntos de dados de treinamento e validação em arquivos CSV
Converta os objetos train e o dataframe validation em arquivos CSV para corresponder ao formato do arquivo de entrada do algoritmo XGBoost.
# Use 'csv' format to store the data # The first column is expected to be the output column train.to_csv('train.csv', index=False, header=False) validation.to_csv('validation.csv', index=False, header=False)
Carregar os conjuntos de dados no Amazon S3
Usando a SageMaker IA e o Boto3, faça o upload dos conjuntos de dados de treinamento e validação para o bucket padrão do Amazon S3. Os conjuntos de dados no bucket do S3 serão usados por uma instância otimizada para computação no SageMaker Amazon EC2 para treinamento.
O código a seguir configura o URI padrão do bucket do S3 para sua sessão atual de SageMaker IA, cria uma nova demo-sagemaker-xgboost-adult-income-prediction pasta e carrega os conjuntos de dados de treinamento e validação na subpasta. data
import sagemaker, boto3, os bucket = sagemaker.Session().default_bucket() prefix = "demo-sagemaker-xgboost-adult-income-prediction" boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/train.csv')).upload_file('train.csv') boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/validation.csv')).upload_file('validation.csv')
Execute o seguinte AWS CLI para verificar se os arquivos CSV foram carregados com sucesso no bucket do S3.
! aws s3 ls {bucket}/{prefix}/data --recursive
Essa saída deve retornar o seguinte resultado:

