As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como funcionam as máquinas de fatoração
A tarefa de predição para um modelo de máquina de fatoração é estimar uma função ŷ de um conjunto de atributos xi para um domínio de destino. Esse domínio é de valor real para regressão e binário para classificação. O modelo Factorization Machines é supervisionado e portanto possui um conjunto de dados de treinamento (xi,yj) disponível. As vantagens desse modelo estão na maneira como ele usa uma parametrização fatorada para capturar as interações de atributos par a par. Ele pode ser representado matematicamente da seguinte maneira:
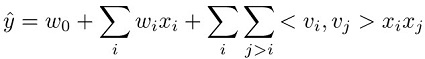
Os três termos nesta equação correspondem respectivamente aos três componentes do modelo:
-
O termo w0 representa a polarização global.
-
Os wi termos lineares modelam a força da i-ésima variável.
-
Os termos de fatoração <vi,vj> modelam a interação de pares entre a i-ésima e a j-ésima variáveis.
Os termos de polaridade global e lineares são os mesmos que os de um modelo linear. As interações de atributos par a par são modeladas no terceiro termo como o produto interno dos fatores correspondentes aprendidos para cada atributo. Os fatores aprendidos também podem ser considerados vetores de incorporação para cada atributo. Por exemplo, em uma tarefa de classificação, se um par de atributos tendesse a coocorrer com mais frequência em amostras rotuladas positivas, o produto interno de seus fatores seria grande. Em outras palavras, os vetores de incorporação estariam próximos uns dos outros em uma similaridade de cosseno. Para obter mais informações sobre o modelo de máquinas de fatoração, consulte Máquinas de fatoração
Para tarefas de regressão, o modelo é treinado minimizando o erro quadrático entre a predição de modelo ŷn e o valor de destino yn. Isso é conhecido como perda quadrada:
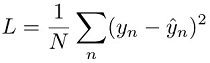
Para uma tarefa de classificação, o modelo é treinado minimizando a perda de entropia cruzada, também conhecida como perda de log:
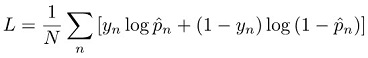
em que:
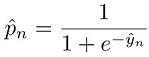
Para obter mais informações sobre funções de perda para classificação, consulte Funções de perda para classificação
