As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Criar, armazenar e compartilhar atributos com o arquivo de atributos
O processo de desenvolvimento de machine learning (ML) inclui extrair dados brutos e transformá-los em atributos (entradas significativas para seu modelo de ML). Esses atributos são, então, armazenados de forma útil para exploração de dados, treinamento de ML e inferência de ML. A Amazon SageMaker Feature Store simplifica a forma como você cria, armazena, compartilha e gerencia recursos. Isso é feito fornecendo opções de arquivo de atributos e reduzindo o trabalho repetitivo de processamento e curadoria de dados.
Entre outras coisas, com o Feature Store, você pode:
-
Simplificar o processamento de atributos, o armazenamento, a recuperação e o compartilhamento de atributos para o desenvolvimento de ML entre contas ou em uma organização.
-
Acompanhe o desenvolvimento do código de processamento de atributos, aplique seu processador de atributos aos dados brutos e insira seus atributos no Feature Store de forma consistente. Isso reduz a distorção entre o que é treinado e o que é oferecido, um problema comum em ML, em que a diferença entre o desempenho durante o treinamento e o serviço pode afetar a precisão do seu modelo de ML.
-
Armazene seus atributos e metadados associados em grupos de atributos para que os atributos possam ser facilmente descobertos e reutilizados. Os grupos de atributos são mutáveis e podem evoluir seu esquema após a criação.
-
Crie grupos de atributos que podem ser configurados para incluir armazenamento offline ou online, ou ambos, para gerenciar seus atributos e automatizar a forma como os atributos são armazenados para suas tarefas de ML.
-
O armazenamento on-line retém somente os dados de atributos mais recentes. Isso foi projetado principalmente para oferecer compatibilidade com predições em tempo real que precisam de leituras de baixa latência de milissegundos e gravações de alto throughput.
-
O armazenamento offline mantém todos os registros de seus atributos como um banco de dados histórico. Isso se destina principalmente à exploração de dados, treinamento de modelos e predições em lote.
-
O diagrama a seguir mostra como você pode usar o Feature Store como parte do pipeline de ML. Depois de ler seus dados brutos, você pode usar o Feature Store para transformar os dados brutos em atributos e colocá-los em seu grupo de atributos. Os atributos podem ser colocados por streaming ou em lotes nos armazenamentos offline e online do grupo de atributos. Depois, os atributos podem ser fornecidos para exploração de dados, treinamento de modelos e inferência em tempo real ou em lote.
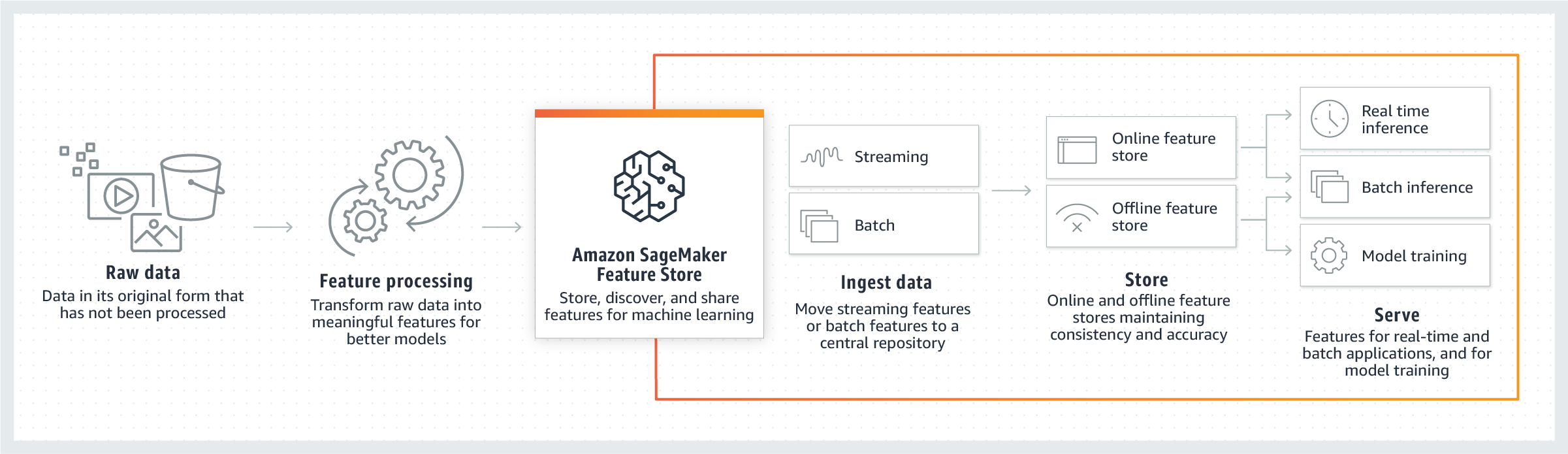
Como funciona o Feature Store
No Feature Store, os atributos são armazenados em uma coleção chamada grupo de atributos. Você pode visualizar um grupo de atributos como uma tabela na qual cada coluna é um atributo, com um identificador exclusivo para cada linha. Em princípio, um grupo de atributos é composto por atributos e valores específicos para cada atributo. Um Record é uma coleção de valores para atributos que correspondem a um RecordIdentifier único. Ao todo, o FeatureGroup é um grupo de atributos definidos em seu FeatureStore para descrever um Record.
Você pode usar o Feature Store nos seguintes modos:
-
Online: No modo online, os atributos são lidos com leituras de baixa latência (milissegundos) e usados para predições de alta throughput. Esse modo exige que um grupo de atributos seja armazenado em um armazenamento on-line.
-
Offline: No modo offline, grandes fluxos de dados são enviados para um armazenamento offline, que pode ser usado para treinamento e inferência em lote. Esse modo exige que um grupo de atributos seja armazenado em um armazenamento offline. O armazenamento offline usa seu bucket do S3 para armazenamento e também pode buscar dados usando consultas Athena.
-
On-line e offline: Incluem os modos on-line e offline.
Você pode ingerir dados em grupos de atributos no Feature Store de duas maneiras: streaming ou em lotes. Quando você ingere dados por meio de streaming, uma coleção de registros é enviada para o Feature Store chamando uma chamada de API PutRecord síncrona. Essa API permite que você mantenha os valores de atributos mais recentes no Feature Store e envie novos valores de atributos assim que uma atualização for detectada.
Como alternativa, o Feature Store pode processar e ingerir dados em lotes. Por exemplo, você pode criar recursos usando o Amazon SageMaker Data Wrangler e exportar um notebook do Data Wrangler. O notebook pode ser uma tarefa SageMaker de processamento que ingere os recursos em lotes em um grupo de recursos do Feature Store. Esse modo permite a ingestão em lote no armazenamento offline. Ele também é compatível com a ingestão no armazenamento on-line se o grupo de atributos estiver configurado para uso online e offline.
Criar grupo de atributos
Para ingerir atributos no Feature Store, você deve primeiro definir o grupo de atributos e as definições do atributo (nome do atributo e tipo de dados) para todos os atributos que pertencem ao grupo de atributos. Após serem criados, os grupos de atributos são mutáveis e podem evoluir seu esquema. Os nomes dos grupos de recursos são exclusivos em um Região da AWS Conta da AWS e. Ao criar um grupo de atributos, você também pode criar os metadados para ele. Os metadados podem conter uma breve descrição, configuração de armazenamento, atributos para identificar cada registro e a hora do evento. Além disso, os metadados podem incluir tags para armazenar informações como autor, fonte de dados, versão e muito mais.
Importante
Nomes ou metadados associados do FeatureGroup, como descrição ou tags, não devem conter nenhuma informação de identificação pessoal (PII) ou informação confidencial.
Encontrar, descobrir e compartilhar atributos
Depois de criar um grupo de atributos no Feature Store, outros usuários autorizados do Feature Store podem compartilhá-lo e descobri-lo. Os usuários podem navegar por uma lista de todos os grupos de atributos no Feature Store ou descobrir grupos de atributos existentes pesquisando por nome do grupo de atributos, descrição, nome do identificador de registro, data de criação e tags.
Real-time inferência para recursos armazenados na loja online
Com o Feature Store, você pode enriquecer seus atributos armazenados no armazenamento on-line em tempo real com dados de uma fonte de streaming (dados de fluxo limpo de outra aplicação) e fornecer os atributos com baixa latência de milissegundos para inferência em tempo real.
Você também pode realizar junções entre diferentes FeatureGroups para inferência em tempo real consultando dois FeatureGroups diferentes na aplicação cliente.
Armazenamento offline para treinamento de modelos e inferência em lote
O Feature Store fornece armazenamento offline para valores de atributos em seu bucket do S3. Seus dados são armazenados no bucket do S3 usando um esquema de prefixos com base no horário do evento. O armazenamento offline é um armazenamento somente para anexos, permitindo que o Feature Store mantenha um registro histórico de todos os valores dos atributos. Os dados são armazenados no armazenamento offline no formato Parquet para armazenamento otimizado e acesso às consultas.
Você pode consultar, explorar e visualizar atributos usando o Data Wrangler a partir do console. O Feature Store é compatível com a combinação de dados para produzir, treinar, validar e testar conjuntos de dados, além de permitir que você extraia dados em diferentes momentos.
Ingestão de dados de atributos
Os pipelines de geração de atributos podem ser criados para processar grandes lotes (1 milhão de linhas de dados ou mais) ou pequenos lotes e para gravar dados de atributos no armazenamento offline ou online. Fontes de streaming, como Transmissão gerenciada para Apache Kafka da Amazon ou Amazon Kinesis, também podem ser usados como fontes de dados das quais os atributos são extraídos e enviados diretamente ao armazenamento on-line para treinamento, inferência ou criação de atributos.
Você pode enviar registros para o Feature Store chamando a chamada de API PutRecord síncrona. Como essa é uma chamada de API síncrona, ela permite que pequenos lotes de atualizações sejam enviados em uma única chamada de API. Isso permite que você mantenha um alto nível de atualização dos valores do atributo e publique os valores assim que uma atualização for detectada. Esses também são chamados de atributos de streaming.
Quando os dados do atributo são ingeridos e atualizados, o Feature Store armazena dados históricos de todos os atributos no armazenamento offline. Para ingestão em lote, você pode extrair valores de atributos do seu bucket do S3 ou usar o Athena para fazer consultas. Você também pode usar o Data Wrangler para processar e criar novos atributos que podem ser exportados para um bucket S3 escolhido para serem acessados pelo Feature Store. Para ingestão em lote, você pode configurar um trabalho de processamento para ingerir em lote seus dados no Feature Store ou extrair valores de atributos do seu bucket do S3 usando o Athena.
Para remover um Record do seu armazenamento on-line, use a chamada de API DeleteRecord. Isso também adicionará o registro excluído ao armazenamento offline.
Resiliência no Feature Store
O Feature Store é distribuído em várias zonas de disponibilidade (AZs). Uma AZ é um local isolado dentro de uma Região da AWS. Se algumas AZs falharem, o Feature Store poderá usar outras AZs. Para obter mais informações sobre AZs, consulte Resiliência na Amazon AI SageMaker.
