As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Relatório de performance do modelo
Um relatório de qualidade de SageMaker modelo da Amazon (também conhecido como relatório de desempenho) fornece insights e informações de qualidade para o melhor candidato a modelo gerado por um trabalho no AutoML. Isso inclui informações sobre os detalhes do trabalho, o tipo de problema do modelo, a função objetivo e várias métricas. Esta seção detalha o conteúdo de um relatório de desempenho para problemas de classificação de imagens e explica como acessar as métricas como dados brutos em um JSON arquivo.
Você pode encontrar o prefixo Amazon S3 para os artefatos do relatório de qualidade do modelo gerados para o melhor candidato na resposta a DescribeAutoMLJobV2 em BestCandidate.CandidateProperties.CandidateArtifactLocations.ModelInsights.
O relatório de desempenho contém duas seções:
-
A primeira seção contém detalhes sobre o trabalho do Autopilot que produziu o modelo.
-
A segunda seção contém um relatório de qualidade do modelo com várias métricas de performance.
Detalhes do trabalho do Autopilot
Esta primeira seção do relatório fornece algumas informações gerais sobre o trabalho do Autopilot que produziu o modelo. Esses detalhes incluem as seguintes informações:
-
Nome do candidato ao Autopilot: o nome do candidato do melhor modelo.
-
Nome do trabalho do Autopilot: o nome do trabalho.
-
Tipo de problema: o tipo de problema. No nosso caso, classificação de imagens.
-
Métrica objetiva: a métrica objetiva usada para otimizar o desempenho do modelo. No nosso caso, Precisão.
-
Direção da otimização: indica se a métrica objetiva deve ser minimizada ou maximizada.
Relatório de qualidade do modelo
As informações de qualidade do modelo são geradas pelos insights de modelo do Autopilot. O conteúdo do relatório gerado depende do tipo de problema abordado. O relatório especifica o número de linhas que foram incluídas no conjunto de dados da avaliação e a hora em que a avaliação ocorreu.
Tabelas de métricas
A primeira parte do relatório de qualidade do modelo contém tabelas de métricas. Eles são apropriados para o tipo de problema abordado pelo modelo.
A imagem a seguir é um exemplo de uma tabela de métricas gerada pelo Autopilot para um problema de classificação de imagens ou textos. Ele mostra o nome, o valor e o desvio padrão da métrica.
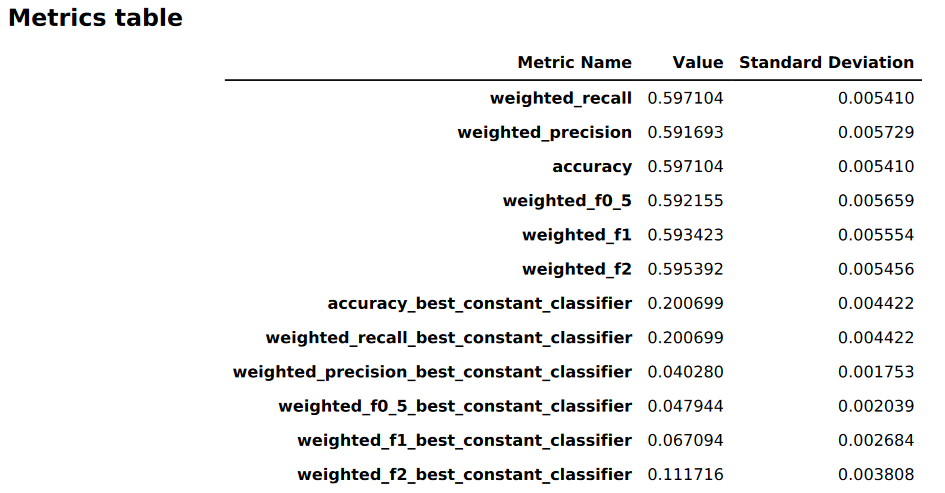
Informações gráficas de performance do modelo
A segunda parte do relatório de qualidade do modelo contém informações gráficas para ajudá-lo a avaliar a performance do modelo. O conteúdo desta seção depende do tipo de problema selecionado.
Matriz de confusão
Uma matriz de confusão fornece uma maneira de visualizar a precisão das previsões feitas por um modelo para classificação binária e multiclasse para problemas diferentes.
Um resumo dos componentes do gráfico da taxa de falsos positivos (FPR) e da taxa de verdadeiros positivos (TPR) é definido da seguinte forma.
-
Previsões corretas
-
Positivo verdadeiro (TP): o valor previsto é 1 e o valor verdadeiro é 1.
-
Negativo verdadeiro (TN): o valor previsto é 0 e o valor verdadeiro é 0.
-
-
Previsões incorretas
-
Falso-positivo (FP): o valor previsto é 1, mas o valor verdadeiro é 0.
-
Falso-negativo (FN): o valor previsto é 0, mas o valor verdadeiro é 1.
-
A matriz de confusão no relatório de qualidade do modelo contém o seguinte.
-
O número e a porcentagem de previsões corretas e incorretas para os rótulos reais
-
O número e a porcentagem de previsões precisas na diagonal do canto superior esquerdo ao canto inferior direito
-
O número e a porcentagem de previsões imprecisas na diagonal do canto superior direito ao canto inferior esquerdo
As previsões incorretas em uma matriz de confusão são os valores de confusão.
O diagrama a seguir é um exemplo de matriz de confusão para um problema de classificação multiclasse. A matriz de confusão no relatório de qualidade do modelo contém o seguinte.
-
O eixo vertical é dividido em três linhas contendo três rótulos reais diferentes.
-
O eixo horizontal é dividido em três colunas contendo rótulos que foram previstos pelo modelo.
-
A barra de cores atribui um tom mais escuro a um número maior de amostras para indicar visualmente o número de valores que foram classificados em cada categoria.
No exemplo abaixo, o modelo previu corretamente os valores reais de 354 para o rótulo f, 1094 valores para o rótulo i e 852 valores para o rótulo m. A diferença de tom indica que o conjunto de dados não está balanceado porque há muito mais rótulos para o valor i do que para f ou m.
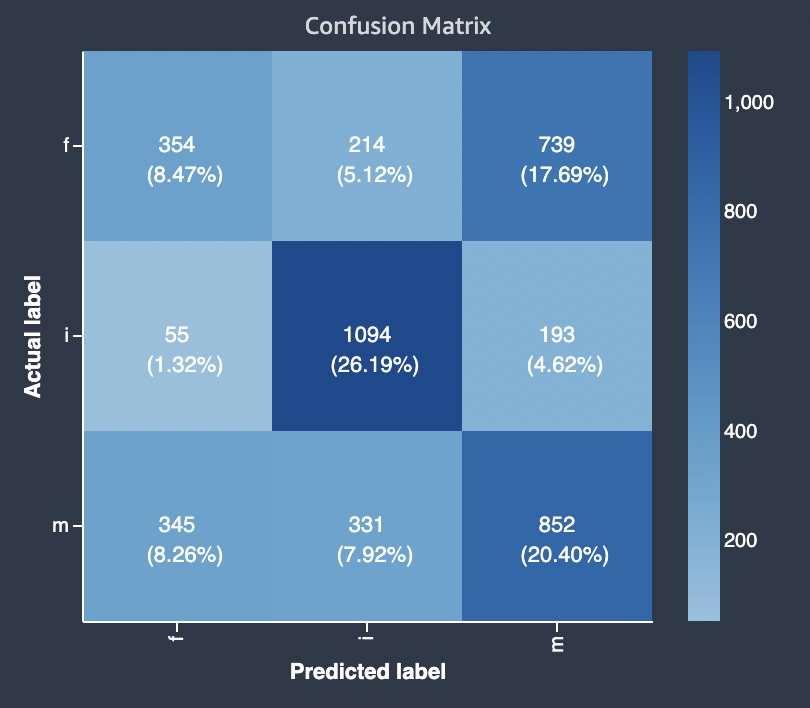
A matriz de confusão no relatório de qualidade do modelo fornecido pode acomodar no máximo 15 rótulos para tipos de problemas de classificação multiclasse. Se uma linha correspondente a um rótulo mostrar um valor Nan, isso significa que o conjunto de dados da validação usado para verificar as previsões do modelo não contém dados com esse rótulo.
