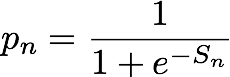As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como funciona o IP Insights
O Amazon SageMaker IP Insights é um algoritmo não supervisionado que consome dados observados na forma de pares (entidade, endereço IPv4) que associam entidades a endereços IP. O IP Insights determina a probabilidade de uma entidade usar um determinado endereço IP, aprendendo representações vetoriais latentes para entidades e endereços IP. A distância entre essas duas representações pode servir como substituto para a probabilidade dessa associação.
O algoritmo IP Insights usa uma rede neural para aprender as representações de vetores latentes para entidades e endereços IP. Primeiramente, as entidades são codificadas em hash para um espaço de hash grande, mas fixo, e depois codificadas por uma camada de incorporação simples. As strings de caracteres, como nomes de usuário ou IDs de conta, podem ser alimentadas diretamente no IP Insights à medida que aparecem nos arquivos de log. Você não precisa pré-processar os dados para identificadores de entidade. É possível fornecer entidades como um valor de string arbitrário durante o treinamento e a inferência. O tamanho do hash deve ser configurado com um valor que seja alto o suficiente para garantir que o número de colisões, que ocorrem quando entidades distintas são mapeadas para o mesmo vetor latente, permaneça insignificante. Para obter mais informações sobre como selecionar tamanhos de hash apropriados, consulte Hash de recursos para aprendizagem multitarefas em grande escala
Durante o treinamento, o IP Insights gera automaticamente amostras negativas, emparelhando entidades e endereços IP aleatoriamente. Essas amostras negativas representam dados com a menor probabilidade de ocorrer em uma situação real. O modelo é treinado para discriminar entre amostras positivas que são observadas nos dados de treinamento e essas amostras negativas geradas. Mais especificamente, o modelo é treinado para minimizar a entropia cruzada, também conhecida como perda de log, definida da seguinte maneira:
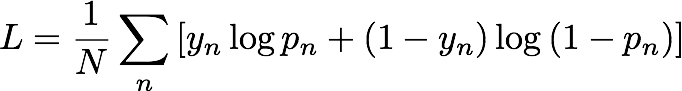
yn é o rótulo que indica se a amostra é da distribuição real que governa os dados observados (yn=1) ou da distribuição gerando amostras negativas (yn=0). pn é a probabilidade de que a amostra seja da distribuição real, conforme previsto pelo modelo.
A geração de amostras negativas é um processo importante usado para obter um modelo preciso dos dados observados. Se amostras negativas forem extremamente improváveis, por exemplo, se todos os endereços IP em amostras negativas forem 10.0.0.0, o modelo aprenderá trivialmente a distinguir amostras negativas e não conseguirá caracterizar com precisão o conjunto de dados real observado. Para manter as amostras negativas mais realistas, o IP Insights gera amostras negativas gerando endereços IP aleatoriamente e escolhendo endereços IP aleatoriamente dos dados de treinamento. Você pode configurar o tipo de amostragem negativa e as taxas nas quais as amostras negativas são geradas com os hiperparâmetros random_negative_sampling_rate e shuffled_negative_sampling_rate.
Dado um enésimo (par de entidade, endereço IP), o modelo IP Insights produz uma pontuação, Sn, que indica o quão compatível é a entidade com o endereço IP. Essa pontuação corresponde à proporção de chances de log para uma determinada (entidade, endereço IP) do par proveniente de uma distribuição real em comparação com aquela proveniente de uma distribuição negativa. Ela é definida da seguinte maneira:
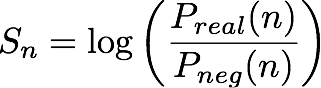
A pontuação é essencialmente uma medida da semelhança entre as representações vetoriais da enésima entidade e endereço IP. Isso pode ser interpretado como uma probabilidade muito maior de observar esse evento na realidade do que em um conjunto de dados gerado aleatoriamente. Durante o treinamento, o algoritmo usa essa pontuação para calcular uma estimativa da probabilidade de uma amostra proveniente da distribuição real, pn, para uso na minimização da entropia cruzada, em que: