As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Registre métricas, parâmetros e MLflow modelos durante o treinamento
Depois de se conectar ao seu Servidor de MLflow Rastreamento, você pode usar o MLflow SDK para registrar métricas, parâmetros e MLflow modelos.
Registre métricas de treinamento
Use mlflow.log_metric em uma corrida MLflow de treinamento para monitorar métricas. Para obter mais informações sobre o uso de métricas de registroMLflow, consultemlflow.log_metric.
with mlflow.start_run(): mlflow.log_metric("foo",1) print(mlflow.search_runs())
Esse script deve criar uma execução experimental e imprimir uma saída semelhante à seguinte:
run_id experiment_id status artifact_uri ... tags.mlflow.source.name tags.mlflow.user tags.mlflow.source.type tags.mlflow.runName 0 607eb5c558c148dea176d8929bd44869 0 FINISHED s3://dddd/0/607eb5c558c148dea176d8929bd44869/a... ... file.py user-id LOCAL experiment-code-name
Na MLflow interface do usuário, esse exemplo deve ser semelhante ao seguinte:
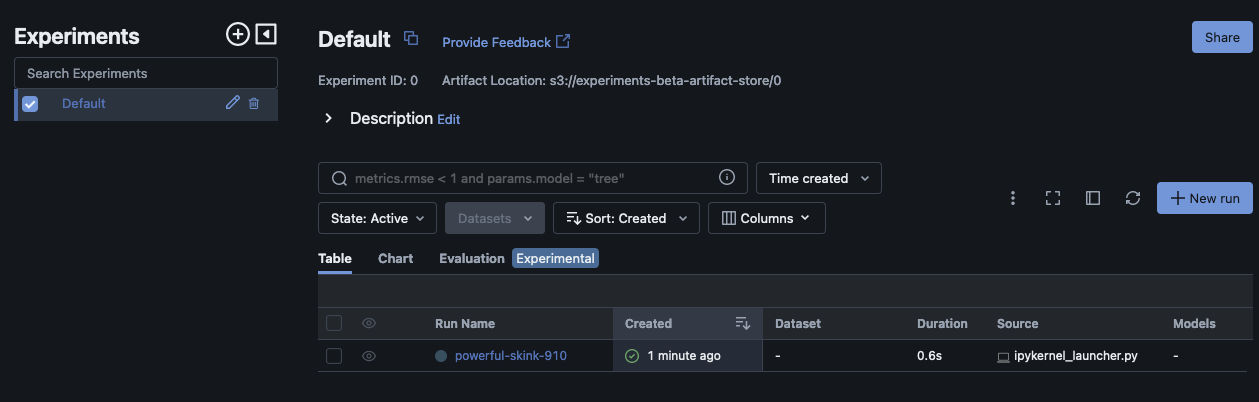
Escolha Nome da execução para ver mais detalhes da execução.
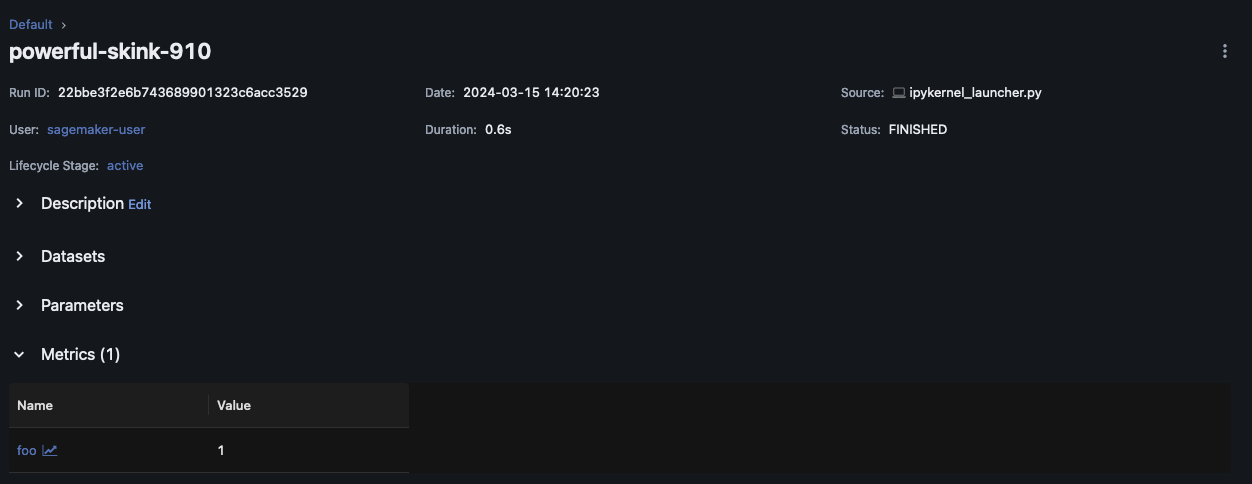
Parâmetros e modelos de log
nota
O exemplo a seguir exige que seu ambiente tenha s3:PutObject permissões. Essa permissão deve ser associada à IAM função que o MLflow SDK usuário assume ao fazer login ou se federar em sua AWS conta. Para obter mais informações, consulte Exemplos de políticas de usuário e função.
O exemplo a seguir mostra um fluxo de trabalho básico de treinamento de modelos usando SKLearn e mostra como monitorar esse modelo em uma execução de MLflow experimento. Este exemplo registra parâmetros, métricas e artefatos do modelo.
import mlflow from mlflow.models import infer_signature import pandas as pd from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # This is the ARN of the MLflow Tracking Server you created mlflow.set_tracking_uri(your-tracking-server-arn) mlflow.set_experiment("some-experiment") # Load the Iris dataset X, y = datasets.load_iris(return_X_y=True) # Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Define the model hyperparameters params = {"solver": "lbfgs", "max_iter": 1000, "multi_class": "auto", "random_state": 8888} # Train the model lr = LogisticRegression(**params) lr.fit(X_train, y_train) # Predict on the test set y_pred = lr.predict(X_test) # Calculate accuracy as a target loss metric accuracy = accuracy_score(y_test, y_pred) # Start an MLflow run and log parameters, metrics, and model artifacts with mlflow.start_run(): # Log the hyperparameters mlflow.log_params(params) # Log the loss metric mlflow.log_metric("accuracy",accuracy) # Set a tag that we can use to remind ourselves what this run was for mlflow.set_tag("Training Info","Basic LR model for iris data") # Infer the model signature signature = infer_signature(X_train, lr.predict(X_train)) # Log the model model_info = mlflow.sklearn.log_model( sk_model=lr, artifact_path="iris_model", signature=signature, input_example=X_train, registered_model_name="tracking-quickstart", )
Na MLflow interface do usuário, escolha o nome do experimento no painel de navegação esquerdo para explorar todas as execuções associadas. Escolha o nome da execução para ver mais informações sobre cada execução. Neste exemplo, a página de execução do experimento para essa execução deve ser semelhante à seguinte.
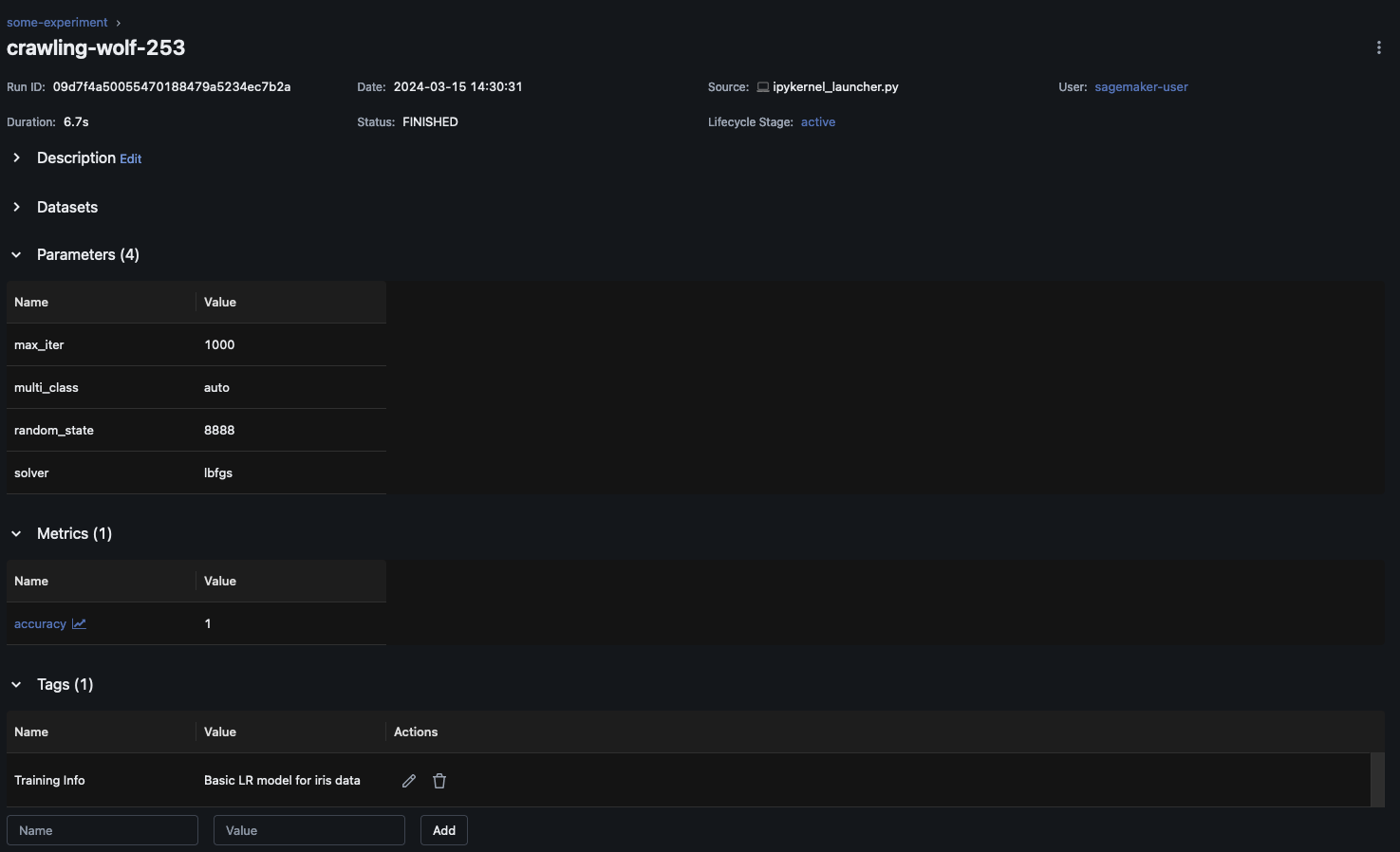
Este exemplo registra o modelo de regressão logística. Na MLflow interface do usuário, você também deve ver os artefatos do modelo registrados.

