As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Teste de modelos com variantes de produção
Nos fluxos de trabalho de ML de produção, engenheiros e cientistas de dados frequentemente tentam melhorar o desempenho de várias maneiras, como realizando Ajuste automático do modelo com SageMaker IA, treinando em dados adicionais ou mais recentes e melhorando a seleção de atributos usando instâncias atualizadas e contêineres de serviço. Você pode usar variantes de produção para comparar seus modelos, instâncias e contêineres e escolher o candidato com melhor desempenho para responder às solicitações de inferência.
Com os endpoints multivariantes de SageMaker IA, você pode distribuir solicitações de invocação de endpoints em várias variantes de produção, fornecendo a distribuição de tráfego para cada variante, ou você pode invocar uma variante específica diretamente para cada solicitação. Neste tópico, analisamos ambos os métodos para testar modelos de ML.
Tópicos
Testar modelos especificando a distribuição de tráfego
Para testar vários modelos distribuindo o tráfego entre eles, especifique a porcentagem do tráfego que é roteada para cada modelo especificando o peso de cada variante de produção na configuração do endpoint. Para mais informações, consulte CreateEndpointConfig. O diagrama a seguir mostra como isso funciona mais detalhadamente.
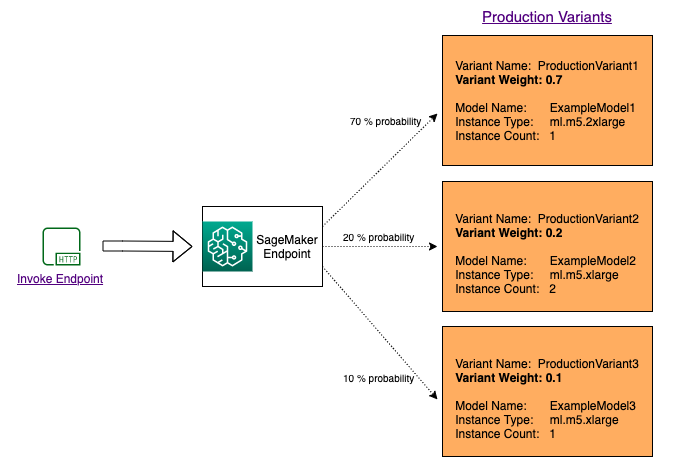
Testar modelos invocando variantes específicas
Para testar vários modelos invocando modelos específicos para cada solicitação, especifique a versão específica do modelo que você deseja invocar fornecendo um valor para o TargetVariant parâmetro ao chamar. InvokeEndpoint SageMaker A IA garante que a solicitação seja processada pela variante de produção que você especificar. Se você já forneceu distribuição de tráfego e especificou um valor para o parâmetro TargetVariant, o roteamento direcionado substituirá a distribuição de tráfego aleatória. O diagrama a seguir mostra como isso funciona mais detalhadamente.
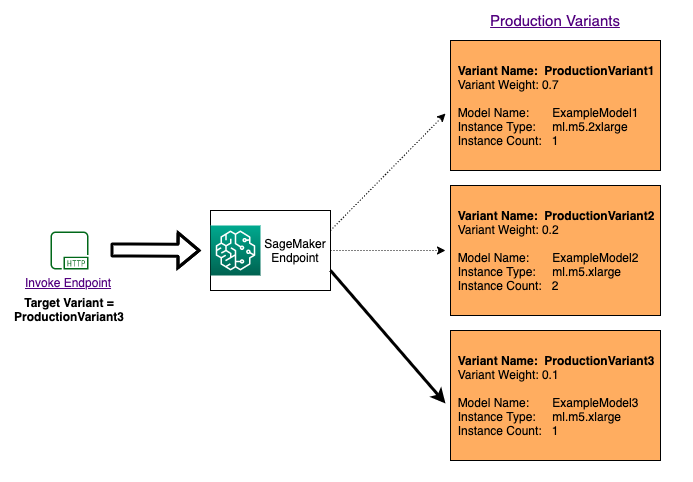
Exemplo de A/B teste de modelo
Realizar A/B testes entre um modelo novo e um modelo antigo com tráfego de produção pode ser uma etapa final eficaz no processo de validação de um novo modelo. Nos A/B testes, você testa diferentes variantes de seus modelos e compara o desempenho de cada variante. Se a versão mais recente do modelo oferecer umo desempenho melhor do que a versão existente anterior, substitua a versão antiga do modelo pela nova versão em produção.
O exemplo a seguir mostra como realizar testes de A/B modelo. Para ver uma amostra de caderno que implementa esse exemplo, consulte "A/B Testando modelos de ML na produção
Etapa 1: Criar e implantar modelos
Primeiro, definimos onde nossos modelos estão localizados no Amazon S3. Esses locais são usados quando implantamos nossos modelos em etapas subsequentes:
model_url = f"s3://{path_to_model_1}" model_url2 = f"s3://{path_to_model_2}"
Depois, criamos os objetos do modelo com a imagem e os dados do modelo. Esses objetos do modelo são usados para implantar variantes de produção em um endpoint. Os modelos são desenvolvidos treinando modelos de ML em conjuntos de dados diferentes, em algoritmos ou estruturas de trabalho de ML diferentes e em hiperparâmetros diferentes:
from sagemaker.amazon.amazon_estimator import get_image_uri model_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" model_name2 = f"DEMO-xgb-churn-pred2-{datetime.now():%Y-%m-%d-%H-%M-%S}" image_uri = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-1') image_uri2 = get_image_uri(boto3.Session().region_name, 'xgboost', '0.90-2') sm_session.create_model( name=model_name, role=role, container_defs={ 'Image': image_uri, 'ModelDataUrl': model_url } ) sm_session.create_model( name=model_name2, role=role, container_defs={ 'Image': image_uri2, 'ModelDataUrl': model_url2 } )
Agora criamos duas variantes de produção, cada uma com seus próprios requisitos de modelo e recurso diferentes (contagens e tipo de instância). Isso permite que você também teste modelos em tipos de instância diferentes.
Definimos um initial_weight de 1 para ambas as variantes. Isso significa que 50% das solicitações vão para a Variant1 e os 50% restantes das solicitações vão para a Variant2. A soma dos pesos em ambas as variantes é 2 e cada variante tem atribuição de peso de 1. Isso significa que cada variante recebe 1/2, ou 50%, do tráfego total.
from sagemaker.session import production_variant variant1 = production_variant( model_name=model_name, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant1', initial_weight=1, ) variant2 = production_variant( model_name=model_name2, instance_type="ml.m5.xlarge", initial_instance_count=1, variant_name='Variant2', initial_weight=1, )
Finalmente, estamos prontos para implantar essas variantes de produção em um endpoint de SageMaker IA.
endpoint_name = f"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}" print(f"EndpointName={endpoint_name}") sm_session.endpoint_from_production_variants( name=endpoint_name, production_variants=[variant1, variant2] )
Etapa 2: Invocar os modelos implantados
Agora enviamos solicitações a esse endpoint para obter inferências em tempo real. Usamos distribuição de tráfego e direcionamento direto.
Primeiro, usamos a distribuição de tráfego configurada na etapa anterior. Cada resposta de inferência contém o nome da variante de produção que processa a solicitação, para que possamos ver que o tráfego para as duas variantes de produção é aproximadamente igual.
# get a subset of test data for a quick test !tail -120 test_data/test-dataset-input-cols.csv > test_data/test_sample_tail_input_cols.csv print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload ) time.sleep(0.5) print("Done!")
SageMaker A IA emite métricas como Latency e Invocations para cada variante na Amazon CloudWatch. Para obter uma lista completa das métricas que a SageMaker IA emite, consulteMétricas de SageMaker IA da Amazon na Amazon CloudWatch. Vamos consultar CloudWatch para obter o número de invocações por variante, para mostrar como as invocações são divididas entre as variantes por padrão:
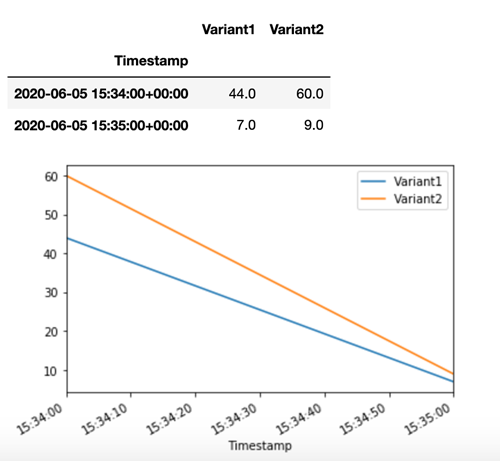
Agora vamos invocar uma versão específica do modelo especificando Variant1 como a TargetVariant na chamada para invoke_endpoint.
print(f"Sending test traffic to the endpoint {endpoint_name}. \nPlease wait...") with open('test_data/test_sample_tail_input_cols.csv', 'r') as f: for row in f: print(".", end="", flush=True) payload = row.rstrip('\n') sm_runtime.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, TargetVariant="Variant1" ) time.sleep(0.5)
Para confirmar que todas as novas invocações foram processadas porVariant1, podemos consultar CloudWatch para obter o número de invocações por variante. Vemos que, para as invocações mais recentes (timestamp mais recente), todas as solicitações foram processadas pela Variant1, como tínhamos especificado. Não foram feitas invocações para a Variant2.
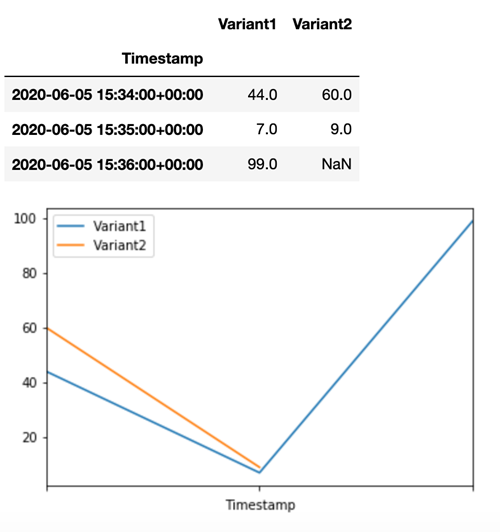
Etapa 3: Avalie o desempenho do modelo
Para ver qual versão do modelo tem melhor desempenho, vamos avaliar a exatidão, a precisão, o recall, a pontuação F1 e o receptor operando charactersistic/Area sob a curva para cada variante. Primeiro, vamos ver essas métricas para a Variant1:
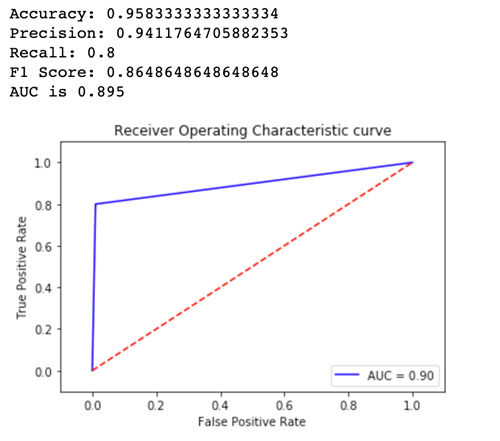
Agora vamos ver as métricas para a Variant2:
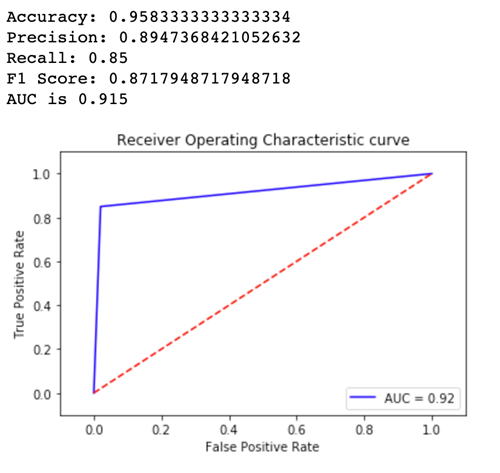
Para a maioria de nossas métricas definidas, o desempenho da Variant2 é melhor, então essa é a que queremos usar na produção.
Etapa 4: Aumentar o tráfego para o melhor modelo
Agora que determinamos que a Variant2 tem um desempenho melhor do que a Variant1, deslocamos mais tráfego para ela. Podemos continuar usando para TargetVariant invocar uma variante de modelo específica, mas uma abordagem mais simples é atualizar os pesos atribuídos a cada variante chamando. UpdateEndpointWeightsAndCapacities Isso altera a distribuição de tráfego para as variantes de produção sem exigir atualizações ao endpoint. Lembre-se, na seção de configuração, de que definimos os pesos das variantes para dividir o tráfego 50/50. As CloudWatch métricas do total de invocações para cada variante abaixo nos mostram os padrões de invocação de cada variante:
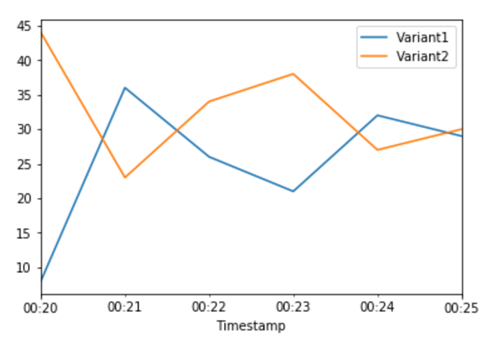
Agora, transferimos 75% do tráfego para Variant2 atribuindo novos pesos a cada variante usando. UpdateEndpointWeightsAndCapacities SageMaker A IA agora envia 75% das solicitações de inferência para Variant2 e 25% das solicitações restantes paraVariant1.
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 25, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 75, "VariantName": variant2["VariantName"] } ] )
As CloudWatch métricas do total de invocações para cada variante nos mostram mais invocações para do que para: Variant2 Variant1
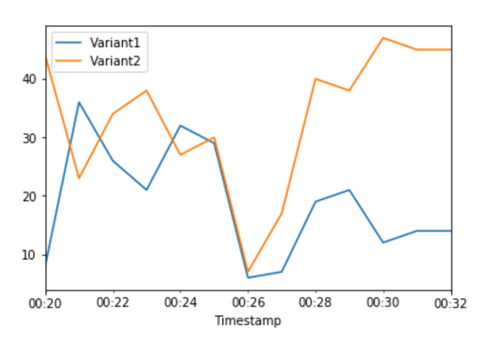
Podemos continuar monitorando nossas métricas e, quando estivermos satisfeitos com o desempenho de uma variante, podemos rotear 100% do tráfego para essa variante. Usamos UpdateEndpointWeightsAndCapacities para atualizar as atribuições de tráfego para as variantes. O peso para Variant1 é definido como 0 e o peso para Variant2 é definido como 1. SageMaker A IA agora envia 100% de todas as solicitações de inferência para o. Variant2
sm.update_endpoint_weights_and_capacities( EndpointName=endpoint_name, DesiredWeightsAndCapacities=[ { "DesiredWeight": 0, "VariantName": variant1["VariantName"] }, { "DesiredWeight": 1, "VariantName": variant2["VariantName"] } ] )
As CloudWatch métricas do total de invocações para cada variante mostram que todas as solicitações de inferência estão sendo processadas Variant2 e não há solicitações de inferência processadas por. Variant1
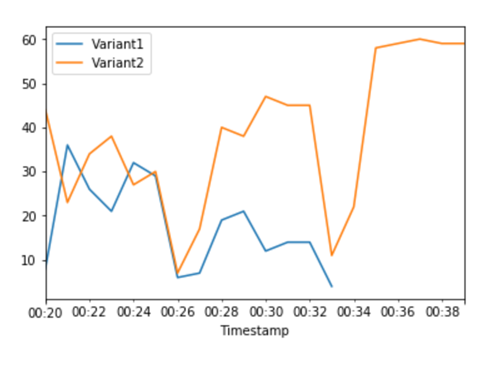
Agora é possível atualizar o endpoint com segurança e excluir a Variant1 do endpoint. Também é possível continuar testando novos modelos em produção adicionando novas variantes ao endpoint e seguindo as etapas de 2 a 4.
