As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Escolhendo um modo de entrada e uma unidade de armazenamento
A melhor fonte de dados para seu trabalho de treinamento depende das características da workload, como o tamanho do conjunto de dados, o formato do arquivo, o tamanho médio dos arquivos, a duração do treinamento, um padrão de leitura sequencial ou randomizado do carregador de dados e a rapidez com que seu modelo pode consumir os dados de treinamento. As práticas recomendadas a seguir fornecem diretrizes para começar a usar o modo de entrada e o serviço de armazenamento de dados mais adequados para seu caso de uso.
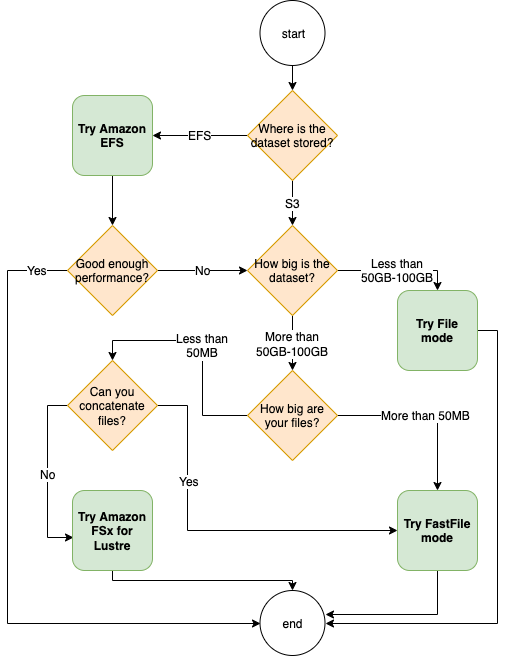
Quando usar a Amazon EFS
Se seu conjunto de dados estiver armazenado no Amazon Elastic File System, você pode ter um aplicativo de pré-processamento ou anotações que usa a Amazon para armazenamento. EFS Você pode executar um trabalho de treinamento configurado com um canal de dados que aponta para o sistema de EFS arquivos da Amazon. Para obter mais informações, consulte Acelere o treinamento na Amazon SageMaker usando o Amazon FSx for Lustre e os sistemas de EFS arquivos da Amazon
Use o modo de arquivo para pequenos conjuntos de dados
Se o conjunto de dados estiver armazenado no Amazon Simple Storage Service e seu volume geral for relativamente pequeno (por exemplo, menos de 50 a 100 GB), tente usar o modo de arquivo. A sobrecarga do download de um conjunto de dados de 50 GB pode variar com base no número total de arquivos. Por exemplo, leva cerca de 5 minutos se um conjunto de dados for dividido em fragmentos de 100 MB. Se essa sobrecarga inicial é aceitável depende principalmente da duração geral do seu trabalho de treinamento, porque uma fase de treinamento mais longa significa uma fase de download proporcionalmente menor.
Serializar muitos arquivos pequenos
Se o tamanho do seu conjunto de dados for pequeno (menos de 50 a 100 GB), mas for composto por muitos arquivos pequenos (menos de 50 MB por arquivo), a sobrecarga de download do modo de arquivo aumentará, pois cada arquivo precisa ser baixado individualmente do Amazon Simple Storage Service para o volume da instância de treinamento. Para reduzir essa sobrecarga e o tempo de passagem de dados em geral, considere serializar grupos desses arquivos pequenos em menos contêineres de arquivos maiores (como 150 MB por arquivo) usando formatos de arquivo, como TFRecord
Quando usar o modo de arquivo rápido
Para conjuntos de dados maiores com arquivos maiores (mais de 50 MB por arquivo), a primeira opção é experimentar o modo de arquivo rápido, que é mais simples de usar do FSx que o Lustre, pois não requer a criação de um sistema de arquivos ou a conexão com um. VPC O modo de arquivo rápido é ideal para contêineres de arquivos grandes (mais de 150 MB) e também pode funcionar bem com arquivos com mais de 50 MB. Como o modo de arquivo rápido fornece uma POSIX interface, ele suporta leituras aleatórias (leitura de intervalos de bytes não sequenciais). No entanto, esse não é o caso de uso ideal e seu throughput pode ser menor do que com as leituras sequenciais. No entanto, se você tiver um modelo de ML relativamente grande e computacionalmente intensivo, o modo de arquivo rápido ainda poderá saturar a largura de banda efetiva do pipeline de treinamento e não resultar em um gargalo de E/S. Você precisará experimentar e ver. Para alternar do modo de arquivo para o modo de arquivo rápido (e vice-versa), basta adicionar (ou remover) o input_mode='FastFile' parâmetro ao definir seu canal de entrada usando o SageMaker PythonSDK:
sagemaker.inputs.TrainingInput(S3_INPUT_FOLDER, input_mode = 'FastFile')
Quando usar o Amazon FSx for Lustre
Se seu conjunto de dados for muito grande para o modo de arquivo, tiver muitos arquivos pequenos que você não pode serializar facilmente ou usar um padrão de acesso de leitura aleatória, FSx o Lustre é uma boa opção a ser considerada. Seu sistema de arquivos é escalável para centenas de gigabytes por segundo (GB/s) de taxa de transferência e milhõesIOPS, o que é ideal quando você tem muitos arquivos pequenos. No entanto, observe que pode haver um problema de inicialização a frio devido ao carregamento lento e à sobrecarga de configurar e inicializar o sistema de arquivos do FSx Lustre.
dica
Para saber mais, consulte Escolha a melhor fonte de dados para seu trabalho de SageMaker treinamento na Amazon
