Programação de um modelo
Um dos principais atributos da biblioteca de paralelismo de modelos do SageMaker é o paralelismo de pipeline, que determina a ordem na qual os cálculos são feitos e os dados são processados nos dispositivos durante o treinamento de modelo. O pipelining é uma técnica para alcançar a verdadeira paralelização no paralelismo do modelo, fazendo com que as GPUs computem simultaneamente em diferentes amostras de dados e para superar a perda de performance devido à computação sequencial. Quando você usa o paralelismo de pipeline, o trabalho de treinamento é executado de forma agrupada em microlotes para maximizar o uso da GPU.
nota
O paralelismo de pipeline, também chamado de particionamento de modelos, está disponível para PyTorch e TensorFlow. Para versões compatíveis com os frameworks, consulte Frameworks compatíveis e Regiões da AWS.
Cronograma de execução do pipeline
O pipelining é baseado na divisão de um minilote em microlotes, que são inseridos no pipeline de treinamento um por um e seguem um cronograma de execução definido pelo runtime da biblioteca. Um microlote é um subconjunto menor de um determinado minilote de treinamento. O cronograma do pipeline determina qual microlote é executado por qual dispositivo em cada intervalo de tempo.
Por exemplo, dependendo do cronograma do pipeline e da partição do modelo, a GPU i pode realizar a computação (para frente ou para trás) no microlote b enquanto a GPU i+1 executa a computação no microlote b+1, mantendo as duas GPUs ativas ao mesmo tempo. Durante uma única passagem para frente ou para trás, o fluxo de execução de um único microlote pode visitar o mesmo dispositivo várias vezes, dependendo da decisão de particionamento. Por exemplo, uma operação que está no início do modelo pode ser colocada no mesmo dispositivo que uma operação no final do modelo, enquanto as operações intermediárias estão em dispositivos diferentes, o que significa que esse dispositivo é visitado duas vezes.
A biblioteca oferece dois cronogramas de pipeline diferentes, simples e intercalados, que podem ser configurados usando o parâmetro pipeline no SageMaker Python SDK. Na maioria dos casos, o pipeline intercalado pode obter melhor performance utilizando as GPUs com mais eficiência.
Gasoduto intercalado
Em um pipeline intercalado, a execução reversa dos microlotes é priorizada sempre que possível. Isso permite uma liberação mais rápida da memória usada para ativações, usando a memória com mais eficiência. Também permite aumentar o número de microlotes, reduzindo o tempo ocioso das GPUs. Em estado estacionário, cada dispositivo alterna entre passes para frente e para trás. Isso significa que a passagem para trás de um microlote pode ser executada antes que a passagem para frente de outro microlote termine.

A figura anterior ilustra um exemplo de cronograma de execução para o pipeline intercalado em 2 GPUs. Na figura, F0 representa a passagem para frente para o microlote 0 e B1 representa a passagem para trás para o microlote 1. A atualização representa a atualização do otimizador dos parâmetros. A GPU0 sempre prioriza as passagens para trás sempre que possível (por exemplo, executa B0 antes de F2), o que permite limpar a memória usada para ativações anteriores.
Pipeline simples
Uma tubulação simples, por outro lado, termina de executar a passagem para frente para cada microlote antes de iniciar a passagem para trás. Isso significa que ele apenas canaliza os estágios de passagem para frente e para trás dentro de si. A figura a seguir ilustra um exemplo de como isso funciona, com mais de 2 GPUs.

Execução de pipelining em estruturas específicas
Use as seções a seguir para aprender sobre as decisões de agendamento de pipeline específicas da estrutura que a biblioteca de paralelismo de modelos do SageMaker toma para o TensorFlow e o PyTorch.
Execução de pipeline com o TensorFlow
A imagem a seguir é um exemplo de um gráfico do TensorFlow particionado pela biblioteca de paralelismo de modelos, usando a divisão automatizada de modelos. Quando um gráfico é dividido, cada subgráfico resultante é replicado B vezes (exceto para as variáveis), onde B é o número de microlotes. Nesta figura, cada subgráfico é replicado 2 vezes (B=2). Uma operação SMPInput é inserida em cada entrada de um subgráfico e uma operação SMPOutput é inserida em cada saída. Essas operações se comunicam com o backend da biblioteca para transferir tensores de e para os outros.

A imagem a seguir é um exemplo de 2 subgráficos divididos com B=2 com operações de gradiente adicionadas. O gradiente de uma operação SMPInput é uma operação SMPOutput e vice-versa. Isso permite que os gradientes fluam para trás durante a retropropagação.
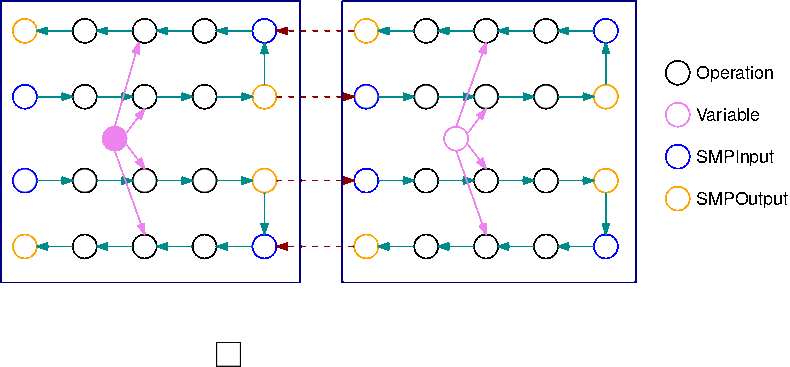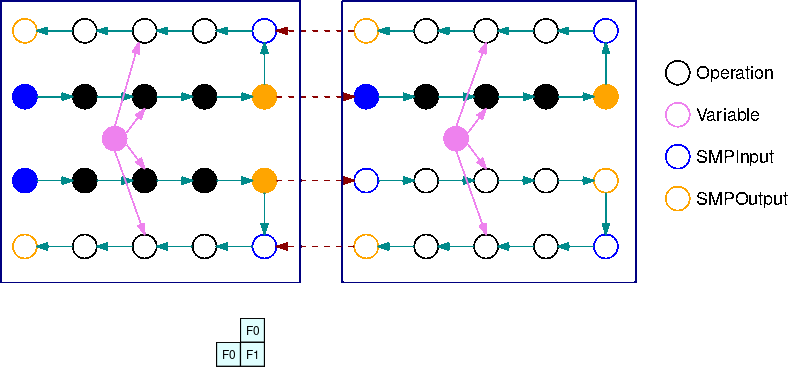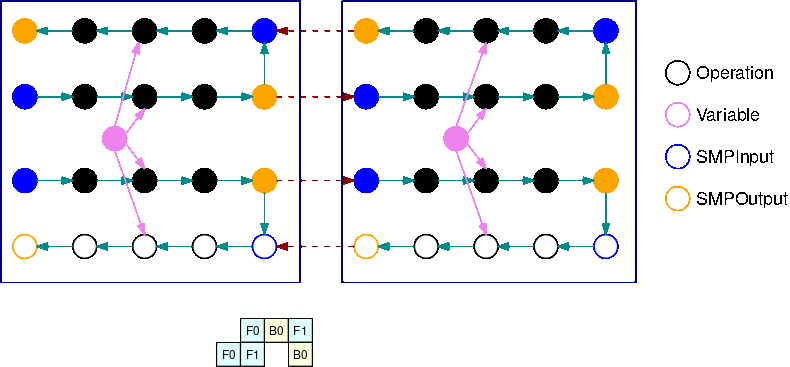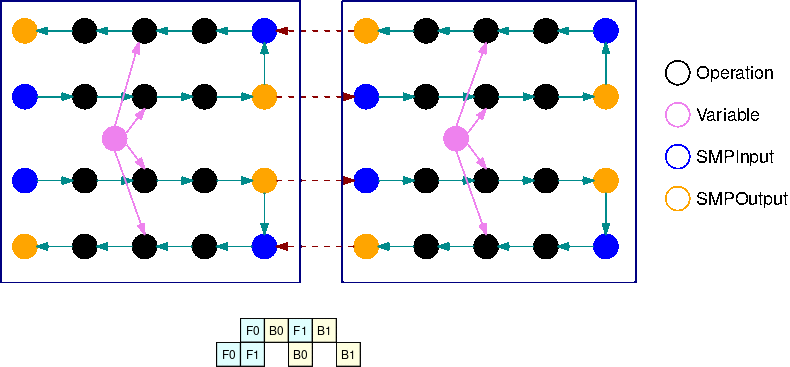
Esse GIF demonstra um exemplo de cronograma de execução de pipeline intercalado com B=2 microlotes e 2 subgráficos. Cada dispositivo executa sequencialmente uma das réplicas do subgráfico para melhorar a utilização da GPU. À medida que B cresce, a fração de intervalos de tempo ociosos vai para zero. Sempre que é hora de fazer cálculos (para frente ou para trás) em uma réplica específica do subgráfico, a camada do pipeline sinaliza para as operações azuis correspondentes SMPInput começarem a ser executadas.
Depois que os gradientes de todos os microlotes em um único minilote são calculados, a biblioteca combina os gradientes entre microlotes, que podem ser aplicados aos parâmetros.
Execução de pipeline com PyTorch
Conceitualmente, o pipelining segue uma ideia semelhante no PyTorch. No entanto, como o PyTorch não envolve gráficos estáticos, o atributo PyTorch da biblioteca de paralelismo de modelos usa um paradigma de pipeline mais dinâmico.
Como no TensorFlow, cada lote é dividido em vários microlotes, que são executados um por vez em cada dispositivo. No entanto, o cronograma de execução é gerenciado por meio de servidores de execução lançados em cada dispositivo. Sempre que a saída de um submódulo colocado em outro dispositivo é necessária no dispositivo atual, uma solicitação de execução é enviada ao servidor de execução do dispositivo remoto junto com os tensores de entrada do submódulo. O servidor então executa esse módulo com as entradas fornecidas e retorna a resposta para o dispositivo atual.
Como o dispositivo atual fica ocioso durante a execução do submódulo remoto, a execução local do microlote atual é pausada e o runtime da biblioteca muda a execução para outro microlote no qual o dispositivo atual possa trabalhar ativamente. A priorização dos microlotes é determinada pelo cronograma de pipeline escolhido. Para um cronograma de pipeline intercalado, os microlotes que estão no estágio anterior da computação são priorizados sempre que possível.
