As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Mecanismo de classificação ao usar uma combinação de paralelismo de pipeline e paralelismo de tensores
Esta seção explica como o mecanismo de classificação do paralelismo do modelo funciona com o paralelismo tensorial. Isso foi estendido do Ranking Basicssmp.tp_rank() tensores, classificação paralela de smp.pp_rank() pipeline e classificação paralela de dados reduzidos. smp.rdp_rank() Os grupos de processos de comunicação correspondentes são tensor parallel group (TP_GROUP), pipeline parallel group (PP_GROUP) e reduced-data parallel group (RDP_GROUP). Esses grupos são definidos da seguinte maneira:
-
Um grupo paralelo de tensores (
TP_GROUP) é um subconjunto uniformemente divisível do grupo paralelo de dados, sobre o qual ocorre a distribuição paralela de módulos por tensores. Quando o grau de paralelismo do pipeline é 1,TP_GROUPé o mesmo que model parallel group (MP_GROUP). -
Um grupo paralelo de pipeline (
PP_GROUP) é o grupo de processos nos quais o paralelismo de pipeline ocorre. Quando o grau de paralelismo do tensor é 1,PP_GROUPé o mesmo queMP_GROUP. -
Um grupo paralelo de dados reduzidos (
RDP_GROUP) é um conjunto de processos que mantêm as mesmas partições de paralelismo de pipeline e as mesmas partições paralelas de tensor e realizam paralelismo de dados entre si. Isso é chamado de grupo paralelo de dados reduzido porque é um subconjunto de todo o grupo de paralelismo de dados,DP_GROUP. Para os parâmetros do modelo que são distribuídos dentro doTP_GROUP, a operação de gradienteallreduceé executada somente para grupos paralelos de dados reduzidos, enquanto para os parâmetros que não são distribuídos, o gradienteallreduceocorre em todo o grupoDP_GROUP. -
Um grupo paralelo de modelo (
MP_GROUP) se refere a um grupo de processos que armazenam coletivamente o modelo inteiro. Consiste na união dosPP_GROUPs de todas as classificações que estão no processo atualTP_GROUP. Quando o grau de paralelismo do tensor é 1,MP_GROUPé equivalente aPP_GROUP. Também é consistente com a definição existenteMP_GROUPde versões anteriores desmdistributed. Observe que a correnteTP_GROUPé um subconjunto da correnteDP_GROUPe da atualMP_GROUP.
Para saber mais sobre o processo de comunicação APIs na biblioteca de paralelismo de SageMaker modelos, consulte o Common API
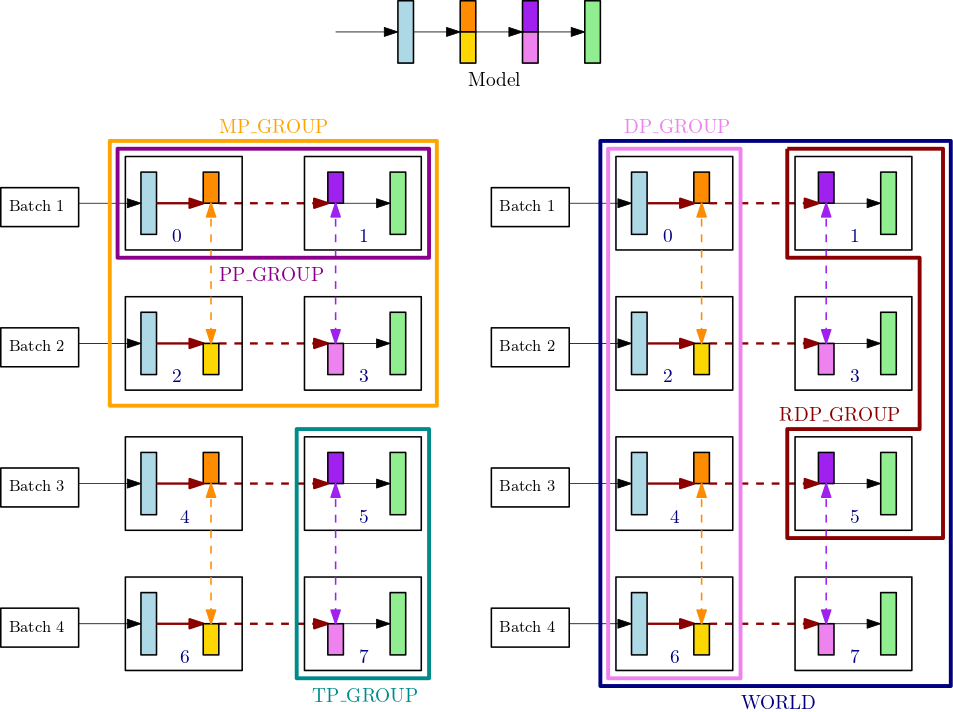
Por exemplo, considere grupos de processos para um único nó com 8GPUs, em que o grau de paralelismo do tensor é 2, o grau de paralelismo do pipeline é 2 e o grau de paralelismo dos dados é 4. A parte central superior da figura anterior mostra um exemplo de modelo com 4 camadas. As partes inferior esquerda e inferior direita da figura ilustram o modelo de 4 camadas distribuídas em 4 GPUs usando paralelismo de tubulação e paralelismo de tensor, onde o paralelismo de tensor é usado para as duas camadas intermediárias. Essas duas figuras inferiores são cópias simples para ilustrar diferentes linhas de limite de grupos. O modelo particionado é replicado para paralelismo de dados em 0-3 e 4-7. GPUs A figura inferior esquerda mostra as definições de MP_GROUP, PP_GROUP e TP_GROUP. A figura inferior direita mostraRDP_GROUP,DP_GROUP, e WORLD sobre o mesmo conjunto deGPUs. Os gradientes das camadas e das fatias da camada que têm a mesma cor são allreduce unidos para paralelismo de dados. Por exemplo, a primeira camada (azul claro) transmite as operações allreduce em DP_GROUP, enquanto a fatia laranja escura na segunda camada só obtém as operações allreduce dentro do processo RDP_GROUP. As setas vermelhas escuras em negrito representam tensores com o lote inteiro TP_GROUP.
GPU0: pp_rank 0, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 0 GPU1: pp_rank 1, tp_rank 0, rdp_rank 0, dp_rank 0, mp_rank 1 GPU2: pp_rank 0, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 2 GPU3: pp_rank 1, tp_rank 1, rdp_rank 0, dp_rank 1, mp_rank 3 GPU4: pp_rank 0, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 0 GPU5: pp_rank 1, tp_rank 0, rdp_rank 1, dp_rank 2, mp_rank 1 GPU6: pp_rank 0, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 2 GPU7: pp_rank 1, tp_rank 1, rdp_rank 1, dp_rank 3, mp_rank 3
Neste exemplo, o paralelismo do pipeline ocorre entre os GPU pares (0,1); (2,3); (4,5) e (6,7). Além disso, o paralelismo de dados (allreduce) ocorre em GPUs 0, 2, 4, 6 e de forma independente em GPUs 1, 3, 5, 7. O paralelismo tensorial ocorre em subconjuntos de DP_GROUP s, entre os GPU pares (0,2); (1,3); (4,6) e (5,7).
